
Войдите в ОК
ПАДЕЖИ В ЭРЗЯНСКОМ ЯЗЫКЕ:
ЭРЗЯНЬ КЕЛЬ [ЭРЗЯНСКИЙ ЯЗЫК], MASTOR | Эрзянь мель — группы вконтакте
11 падежей эрзянского языка:
1) Именительный — кие? мезе? (кто? что?) — АВА, КУДО;
2) Родительный — кинь? мезень? (кого? чего?) — АВАНЬ, КУДОНЬ;
3) Дательный — кинень? мезнень? (кому? чему?) — АВАНЕНЬ, КУДОНЕНЬ;
4) Отложительный — киде? мезде? (о ком? о чём?) — АВАДО, КУДОДО;
5) Местный — кисэ? мейсэ? (в ком? в чём?) — АВАСО, КУДОСО;
6) Исходный — кистэ? мейстэ? (из кого? из чего?) — АВАСТО, КУДОСТО;
7) Направительно-вносительный — кис? мезес? ков? (в кого? во что? куда?) — АВАС, КУДОС;
8) Переместительный — кива? мезева? кува? (по кому? по чему? где?) — АВАВА, КУДОВА;
9) Превратительный — кикс? мезекс? (в кого? чем? во что?) — АВАКС, КУДОКС;
10) Сравнительный — кишка?(кинь эйшка?) мезешка? (с кого? с чего?) — АВАШКА, КУДОШКА;
11) Изъятельный — кивтеме? мезевтеме? (без кого? без чего?) — АВАВТОМО, КУДОВТОМО.
Источник статьи: http://m.ok.ru/tonavtnety/topic/65279833063613
Эрзянский язык — знакомо и весело?
Добрый Вечер! — Шумбрат! Эрзянский язык — один из национальных языков Российской Федерации. Входит в финно-пермскую языковую общность которая вместе с угорскими языками входит в финно-угорские языки. Вместе с самодийскими финно-угорские языки образуют уральскую языковую семью.
Эрзянский наиболее близок к мокшанскому языку. Иногда для них используется собирательное «мордовские языки». Степень родства языка эрзян с языками мещеры, мери и муромы является предметом спекуляций среди национально ориентированных энтузиастов.
В эрзянском языке ударение свободное, а вот в мокшанском — фиксированное (в большинстве случаев). Пока что для записи используется кириллица, что очень удобно.
Начнем, пожалуй, со знакомых или понятных слов.
Капуста — капста, Бочка — боцька, Бык — бука (сравните: польск. byk, каз. бұқа), Магистраль — улиця, Баран — баран (мокш. Боран).
Вы удивитесь, но в эрзянском есть. балтизмы — заимствованный слова из древних балтских языков, которые БЫЛИ родственны современным латышскому и литовскому. Из балтских племен на территории России мы знаем только голядь (Московская область).
Волк — Верьгиз (эрз), Върьгаз (мокш).// слово сравнивается с литовским vilkas и латыш. vilks. Напрашивается и сравнение с древнескандинавским vargr (варг) — мифический волк. Сравните с марийским — пире, пирӹ.
Гром — Пурьгине -> Пургаз. Слово сравнивают с балто-славянским богом грома Перуном. Но вот балтская форма даже ближе — Перкунас. В пантеоне эрзян был бог-громовержец, что более свойственно именно для индоевропейцев.
лист — лопа. Сравнивается с lapa (латыш), lapas (литовский). Запомнить это слово легко: лопасть, лопата. Стоит назвать еще иранизм мирде -муж, смертный, человек (ср. morte)
Интересно и сравнение обозначений некоторых птиц: Ворон — кренч (эрз.), кранч (мок.) — krauklis (латыш.), crow (англ.). Ворона — варсей, варака (эрз) — varna (лит.), vārna (лат)
Бумажный (прил) — конёвонь. Беременность— пекияма. Осина — пой. Белый — ашо, Песец — ашо ривезь, Потому что — секс мекс, Почва — мода, Хозяин-Владелец — Азор. Рыба — кал.
Во-первых — Васняяк, Воск — шта. По-братски — патякс-лелякс. Внизу — ало. Воевать — тюремс. Весенний — тундонь.
Огурец — куяр (сравните с татарским кыяр). Но зато тыква — дурак куяр. Кстати, можно найти параллели с тюркскими языками, благо мои небольшие познания позволяют. Враг — ят, душман (тат. Дошман, индоевропейский тадж. душман). Борода — сакал (казахск. и татар. Сакал — сюда же Аксакал — старейшина — букв. «Белая борода»). Вред, беда, напасть — зыян (сравните с татар. Зыян и казахским зиян. В русском есть слово изъян). Мыло — сапонь (каз. Сабын)
Думаю, на сегодня вам хватит. Надеюсь, я смог без самосожжений и грантов привлечь вас с вот таким вот удивительным языком.

Дубликаты не найдены
потому что по-братски — секс-мекс патякс-лелякс (эрз.)
Волк — Верьгиз (эрз), Върьгаз (мокш).// слово сравнивается с литовским vilkas и латыш. vilks. Напрашивается и сравнение с древнескандинавским vargr (варг) — мифический волк. Сравните с марийским — пире, пирӹ.
Пире, скорей всего, произошло из тюркских. У татар и башкир, живущих по соседству с марийцами, есть слово бүре в значении волк. Узбекский (далеко не сосед марийцев) – bo’ri. Турецкий – börü (сейчас, правда, говорят kurt, а börü я ни разу не слышал, но в словаре есть и в турецкой Вики тоже упоминается в статье Kurt). То есть бүре – это явно общетюркское слово и вряд ли оно могло мигрировать от марийцев до турков.
Происхождение пире от бүре более вероятно, чем от балтийских и скандинавских слов (где Прибалтика и где Татария с Башкирией). Кроме того, надо проверить соответствие между пире и верьгиз – соответствуют ли они друг другу закономерно? Марийцы явно заимствовали у соседей, тогда как эрзя и мокша сохранили либо свой исконный вариант, либо взяли у прибалтов. Склоняюсь к тому, что это их собственное слово.


Тут моя позиционная ошибка) Это сравнение как раз должно было показать, что эрзянское слово совершенно не родственно с марийским. А получилось, что я утверждаю, что марийское тоже из И-Е) Но это не так.
По поводу «пире»? Вот что удалось найти при беглом поиске:
Предполагается происхождение марийского названия волка из иранских языков, так как версия тюркского заимствования сталкивается с фонетическими трудностями [Кузнецова 2010: 54-55].
Любопытно. Картина намного шире, чем у меня (понятное дело). Получается, что пире, волк и бүре в любом случае связаны, но связи гораздо сложнее, чем я мог бы предполагать.
Табуирование и поздний (на фоне индо-европейцев) переход финно-угров на оседлое сельское хозяйство звучат вполне убедительно. И где-то мы уже обсуждали, что кто-то из финно-угров даже заимствовал целое название для народа, кажется, марийцы – слово иранского происхождения, что уж говорить о волке.
При этом даже среди тюрков для волка есть разные обозначения. Азеры их называют просто джанавар (ади джанавар – волк обыкновенный), хотя в турецком и татарском и, подозреваю, в других тюркских джанавар – это зверь, чудовище.
Двадцать, тридцать, девятьсот
Продолжаю отвечать на вопрос @RainbowDysch о числительных (см. первую часть). Сегодня мы поговорим о русских названиях десятков и сотен.

Для начала нужно сказать, что числительные первого десятка в праиндоевропейском языке вели себя по-разному. Самые древние, 1–4, как прилагательные, они согласовывались с существительным по числу и роду (в современном русском разные формы родов есть только у 1 и 2, но раньше были также у 3 и 4). Более новые, 5–10, по происхождению сами были существительными и после них зависимое слово ставилось в родительный падеж множественного числа (это называется управление). Эта же схема сохранилась в праславянском и старославянском языках (напоминаю, что это не одно и то же).
Если учесть, что в праславянском языке было три числа, мы получаем четыре возможных способа сочетания числительного с существительным:
1 + именительный падеж единственного числа;
2 + именительный падеж двойственного числа;
3-4 + именительный падеж множественного числа;
5-10 + родительный падеж множественного числа.
Продемонстрирую это в таблице (для простоты берём только неодушевлённое существительное мужского рода):
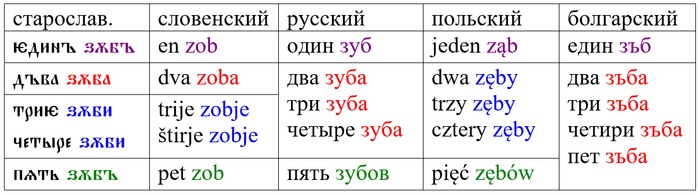
Современные славянские языки пошли несколькими путями:
1) полностью сохранить старую систему смогли только те языки, где есть двойственное число – словенский и лужицкие;
2) в русском и сербохорватском 2-4 сочетаются со старой формой именительного падежа двойственного числа;
3) в польском, чешском и словацком с 2-4 используется именительный падеж множественного числа;
4) у болгар и македонцев с 2-5 сочетается так называемая счётная форма, которая восходит к всё тому же именительному падежу двойственного числа.
Перейдём к наименованиям десятков. Нужно сразу сказать, что уже в праиндоевропейском языке было слово *ḱm̥tom /кьмтом/ «сто», прямым потомком которого наше сто и является. Соответственно, существовали и названия десятков, которые хорошо сохранились в санскрите, греческом, латыни и ряде других ветвей индоевропейских языков, но праславянский заменил их на новые, более прозрачные, обозначения. Скажем, 20 для праиндоевропейского реконструируется как *ṷih₁ḱm̥tih₁ /ўихкьмтих/ (сложение *dṷoh₁ «два» и *deḱm̥t «десять»), и эта форма отразилась в латыни как viginti /ўигинти/, в древнегреческом как εἴκοσι /экоси/, а в санскрите как viṁśatí /винщати/. Если бы это слово сохранилось в современном русском, оно бы звучало как *висяти. Однако праславянский ввёл вместо него *dъva desęti, то есть «два десятка».
Все названия десятков в праславянском и древнерусском вели себя как сочетания единиц и числительного десять, полностью подчиняющиеся вышеописанной схеме.

Поначалу это были именно словосочетания, то есть, между их компонентами могли вставляться другие слова, кроме того, при склонении названий десятков в древнерусском изменялись обе части:

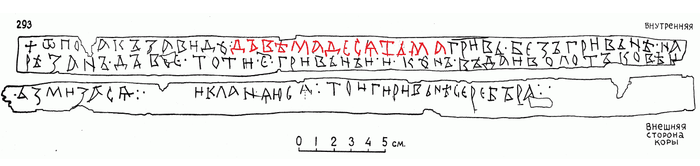
Довольно рано словосочетания срастаются в одно слово, и первый компонент слов 20 и 30 перестаёт склоняться. Кроме того, произошло фонетически незакономерное упрощение слов 20 и 30. Так, из древнерусского дъва десяти в современном русском должно было получиться двадесяти. Однако для числительных довольно характерны нестандартные укорачивания. Скажем, на месте литературного тысяча в разговорном русском появилась форма тыща, хотя у нас сейчас не действует фонетического закона, по которому заударные гласные бы просто так исчезали. Аналогичным образом в двадесяти отвалились -е- и -и. При этом произношение типа двадсять было невозможно, поскольку в русском не могут друг за другом следовать звонкая и глухая согласные. Вследствие этого на месте —дс— получаем —тс-, а —тс— уже в свою очередь сливаются в —ц— (аффриката ц по сути и состоит из т и с). Похожие процессы имеем в случаях браться – /брацца/ или /браца/, детский – /децкий/.
Форма трицать засвидетельствована уже в новгородской берестяной грамоте №1 (1380‒1400 гг.):
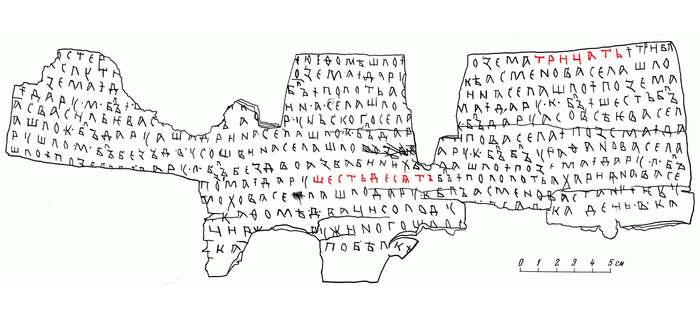
Современная запись вида двадцать и тридцать наполовину фонетична, наполовину этимологична, она объединяет —ц-, возникшее в результате описанных выше процессов, и —д-, которое там уже давно не произносится.
Довольно похожие процессы проходили, например, в чешском языке:
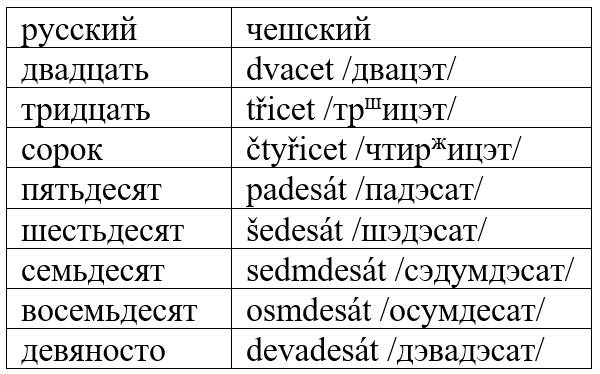
Несложно заметить, что русский ввёл новые названия для 40 и 90. О первом я уже как-то писал, о втором надеюсь сделать отдельный пост в дальнейшем.
Перейдём к сотням. Их обозначения выстроены по тем же принципам, что и названия десятков:

В отличие от названий десятков, в современном литературном русском эти обозначения сохранились почти в неизменном виде. Вполне закономерно пали «редуцированные» (ъ и ь – особые гласные). Кроме того в форме двѣстѣ произошла диссимиляция, то есть расподобление ѣ…ѣ > ѣ. и. Аналогичный пример: сѣдѣти > сидеть.
Отдельно следует оговорить вопрос склонения названий десятков и сотен. Как я уже написал выше, первые части 20 и 30 перестали склоняться рано. Что касается 50-90, со временем вместо форм типа пятьюдесятью начинают появляться пятидесятью, шестидесятью и так далее:
Наконец подпоручик Толстовалов с пятидесятью охотниками сделал вылазку, очистил ров и прогнал бунтовщиков, убив до четырехсот человек и потеряв не более пятнадцати. [А. С. Пушкин. История Пугачева (1833)]
В сию минуту Салманов передался, и Бошняк остался с шестидесятью человеками офицеров и солдат. [А. С. Пушкин. История Пугачева (1833)]

В разговорном языке существует тенденция к полной утрате склоняемости первой части, которая является частью того же процесса, который упростил склонение 20 и 30:
Если вес уссурийского тигра достигает трехсот килограмм, а бенгальского ― двухсот пятидесяти, то «туранец» весил не больше пятьдесяти—шестьдесяти килограмм. [Александр Яблоков. Точка возврата позади // «Знание — сила», 2006]
Литературная норма также велит, чтобы в названиях сотен склонялись обе части:
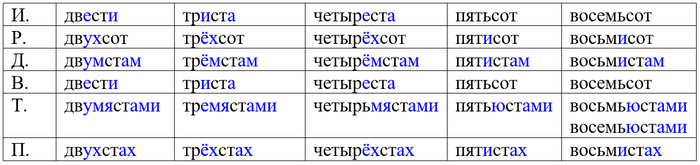
Однако в разговорной речи эта система уже в значительной степени разрушена, и есть сильная тенденция ориентироваться на склонение числительного сто. Отсюда формы типа пятиста:
― 8-я английская армия в 4.30 утра 6 апреля внезапно штурмовала позиции Роммеля, открыв огонь из пятиста орудий. [В. В. Вишневский. Дневники военных лет (1943-1945)]
Кроме того, зачастую не склоняют первые компоненты составных числительных, то есть состоящих из названий нескольких разрядов. Для многих носителей современного русского будет достаточно проблематично просклонять числительное в следующем примере в соответствии с нормой:
Написав по этой азбуке цифрами слова L’empereur Napoleon, выходит, что сумма этих чисел равна 666-ти и что поэтому Наполеон есть тот зверь, о котором предсказано в Апокалипсисе. [Л. Н. Толстой. Война и мир. Том третий (1867-1869)]
Надеюсь, этот пост помог вам лучше понять, как устроены русские числительные 20-900 в исторической перспективе. За более подробной информацией отсылаю к книге О.Ф. Жолобова Историческая грамматика древнерусского языка IV. Числительные. Больше о том, как русские числительные утрачивают склонение можно прочитать в статье М.Я. Гловинской Изменения в склонении числительных в русском языке на рубеже ХХ—XXI веков // Язык в движении: К 70-летию Л.П. Крысина. М., 2007.

Магия против науки — сравнение книг о Гарри Поттере и диссертаций
Продолжаем анализировать русский язык при помощи математики! Предыдущие посты:
В комментариях под прошлым постом предложили сравнить очень интересный материал — магистерскую и докторскую диссертации, написанные на одной кафедре. Этим мы сегодня и займёмся! А чтобы читать пост было интересно всем, сравним их с первой и последней книгами из серии о Гарри Поттере
Волшебник из книг Джоан Роулинг рос вместе с нами. Первая книга «Гарри Поттер и философский камень» написана простым языком, понятным и детям. В последней книге серии — «Гарри Поттер и дары смерти» герои взрослее, а проблемы серьёзнее

В науке исследования, как правило, ведутся в узком направлении. Но каждая работа должна быть уникальной, а магистерская и докторская диссертации отличаются по сложности. Итак, что по вашему мнению будет больше похоже: первая и последняя книги о Гарри Поттере или магистерская и докторская диссертации, написанные на одной кафедре? Ставки приняты, начнём анализ!
Тексты о волшебстве
Начнём с анализа книг о Гарри Поттере. Сперва, по традиции, посмотрим на топ 15 самых частых слов в книгах:
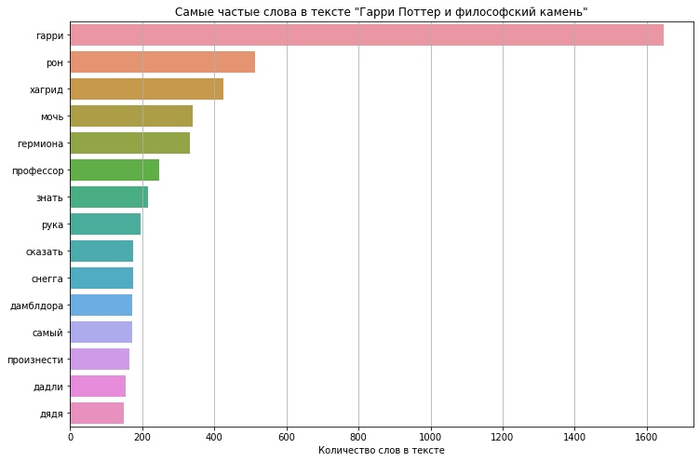
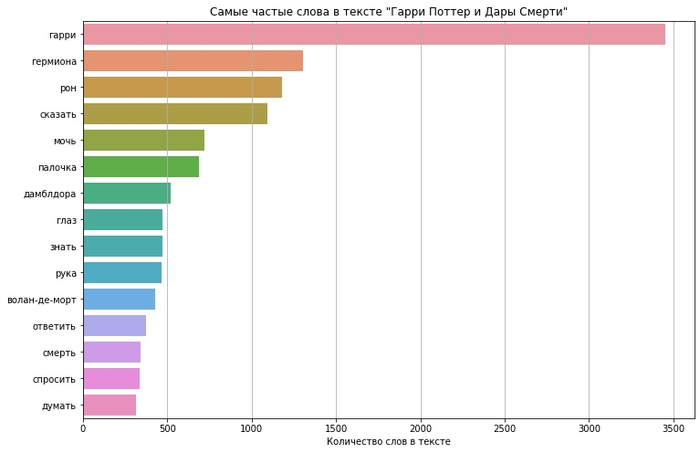
Да уж, нет никаких сомнений в том, кто главный герой серии. Забавно, что Гермиона обогнала Рона по частоте упоминаний в последней книге, хотя в первой уступала даже Хагриду. А ещё в серии неожиданно часто встречаются руки
Кстати, в этот раз я улучшил предобработку: теперь стоп-слова, наподобие частиц и предлогов, выбрасываются из текста, а остальные слова приводятся к одинаковой форме. Например, и «ответил», и «ответила» превращаются в «ответить», а «Рона», «Рону» и «Рон» считаются как одно слово. Это называется лемматизацией
Это делается автоматически и иногда приводит к казусам. Например «Малфой» превратился в слово «Малфа», а «Снегг» в «Снегга». Любители фанфиков, наверняка, останутся довольны
Вот визуализация топ 150 слов в текстах. Чем больше слово, тем чаще оно упоминается в книге:


В первой книге очень много имён, ведь она знакомит нас с новым миром. В последней речь больше идёт о главных героях и их действиях
Для анализа использовались две работы с кафедры электротехнологий, электрооборудования и автоматизированных производств Чувашского Государственного Университета. Большое спасибо за этот материал Фёдору Иванову (@fedor0804)
1. Магистерская диссертация «Индукционная установка для сквозного нагрева заготовок» Фёдора Иванова
2. Докторская диссертация «Исследование особенностей характеристик электротехнологических дуг в дуговых печах» Дениса Михадарова
Топ слов, конечно, совсем не похож на книги о Гарри Поттере. Главные герои здесь индуктор и дуга, а в тексте часто встречаются числа и специальные символы. Их, к сожалению, не удалось правильно обработать и на графиках они выглядят как прямоугольники. Скорее всего, это греческие буквы, например, β


Сравнение магии и науки
Итак, у нас есть 4 огромных текста. Как понять, насколько они похожи друг на друга? Для этого можно посчитать косинус угла между текстами или даже сам угол. Давайте разберёмся, как это работает
Представим два текста поменьше: по одному предложению в каждом. Первый текст — «Еле-еле ели». Второй текст совсем лаконичный — из одного слова «Едим». После лемматизации у нас будут уже такие тексты:
Теперь подсчитаем количество слов в них:
Мы можем нарисовать простой график, где по одной оси будет отложено количество слова «еле» в тексте, а по другой — количество слова «есть». Изобразим наши предложения на этом графике
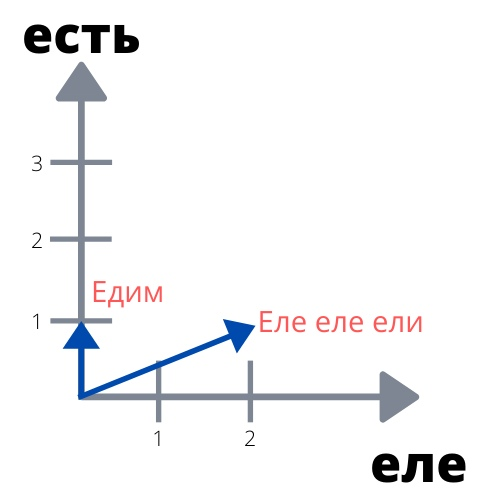
Теперь не проблема посчитать угол между текстами! Можно, конечно, взять транспортир. Но для того, чтобы решить эту задачу для текстов с тысячами слов, это не поможет. Если конечно, вы не живёте в тысячемерном мире и у вас полно тысячемерных транспортиров
Мы представили тексты в виде векторов. В школе вы считали скалярное произведение между векторами и находили через него угол. Здесь можно сделать то же самое — и неважно, сколько всего уникальных слов в текстах – два или тысячи. Для текстов из примера — косинус будет равен примерно 0.44, а угол — 63 градуса
Чем меньше угол между текстами, тем больше они похожи. Если же угол равен 90 градусам, то тексты перпендикулярны — совсем разные. Например, такой угол был бы между текстами на русском и китайском языках — у них нет общих слов. Надеюсь, вы только что стали немного умнее 🙂

Вернёмся к нашим текстам. Больше всего оказались похожи книги о Гарри Поттере. Угол между ними — всего 26 градусов
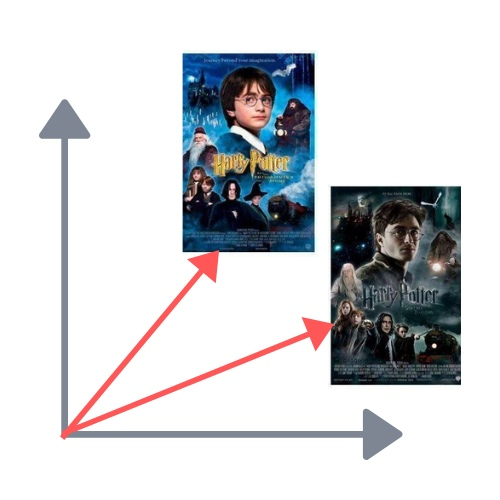
Между магистерской диссертацией и книгами о Гарри Поттере оба угла составили 87 градусов. Эти тексты очень разные. Ещё менее похожими на книги Джоан Роулинг оказалась докторская диссертация — у неё получился угол 88 градусов с первой книгой и 89 градусов с седьмой
Что забавно, научные работы тоже оказались довольно разными. Угол между диссертациями — целый 71 градус
Так что, последняя книга о Мальчике, который выжил — почти то же самое, что и первая, но немного под другим углом. А читая научные работы, даже с одной кафедры, вы каждый раз изучаете новый труд

Заглядывайте в комментарии – там есть небольшой бонус. Пишите, анализ, каких текстов вам ещё бы хотелось увидеть

Русизмы в чешском языке
Я посвятил немало постов истории слов, заимствованных в русский язык, однако недавно @Basileus навёл меня на мысль, что широкой публике почти неизвестна тема русских заимствований в других славянских языках. Тема эта велика и обширна, и о каждом языке следует рассказать отдельно. Начнём с чешского.
Следует сказать, что долгое время в качестве основного языка литературы в Чехии использовалась латынь. На латыни написана первая чешская хроника, на этом же языке записывались стихи, песни, легенды, жития. Самая старая сохранившаяся фраза, написанная по-чешски, относится лишь к XIII веку. Впрочем, довольно рано по меркам католической Европы чешский язык выходит из тени. Уже в середине XIV века чехи переводят с латыни полный текст Библии, а следующий, XV, становится золотым веком их литературы. Однако после поражения в битве на Белой горе, начинается продолжительный упадок чешской культуры. Чешский язык теряет былой престиж, дворянство и население крупных городов стремительно германизируется. К началу XIX века даже уже стало казаться, что чехи скоро полностью растворятся в немецкой стихии. Один из отцов славистики, Йозеф Добровский, в 1811 году писал: «дело нашего народа, если не поможет бог, совершенно безнадежно».
Однако, как мы знаем, чешскому языку удалось выжить, в чём немаловажную роль сыграли так называемые «будители чешского народа», которые боролись за престиж чешского языка, за то, чтобы он мог использоваться в литературе, журналистике, театре и образовании. По понятным причинам многие будители были пуристами и выступали за очищение чешского языка от немецких и латинских заимствований. В начале XIX века Россия и русский язык рассматривались в очень позитивном ключе. Россия на тот момент была единственным независимым славянским государством, и неудивительно, что интерес к русскому языку и русской культуре среди чешских интеллектуалов был очень велик.
Антонин Пухмайер в одном своём письме даже выразил своё неудовольствие этим фактом: «Я замечаю, что русский язык только портит молодых чехов, так как они без разбору и без нужды наводняют им чешский. Я тоже занимался русским и особенно польским языком, но надеюсь, что я не испортился и остался верен своему чешскому языку».
Действительно, увлечение русским языком приводит к тому, что чешские писатели, переводчики и журналисты начинают активно использовать русизмы в своих произведениях. Значительное их количество дальше страниц этих произведений не пошли, однако многие смогли закрепиться, и используются по сей день.
Многие заимствования связаны с морем, что неудивительно, поскольку чехи хоть и здороваются друг с другом морским приветствием ahoj /ағой/, живут далеко от морского побережья.
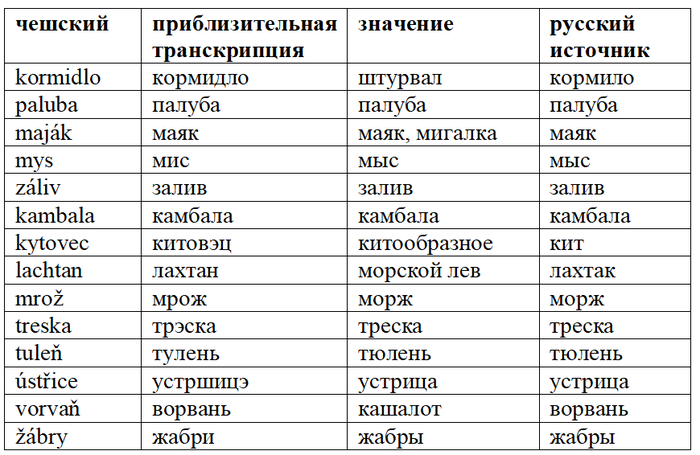
Комментарий: ударение в чешском всегда ставится на первый слог, а чарка (´) обозначает долготу гласного. H произносится примерно как украинское г (хотя это всё же разные звуки). Чешские звуки (звонкий и глухой), обозначаемые буквой ř, лишь весьма условно транскрибируются как рж и рш.
Заимствовались названия не только морских животных:
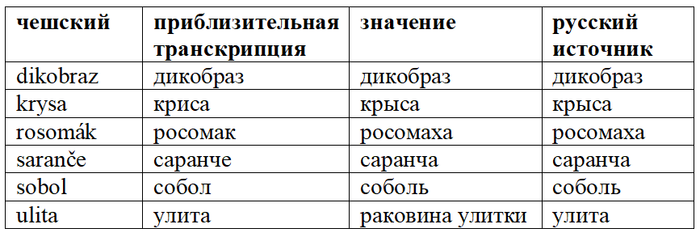
Кстати, до появления русизма krysa чехи называли это животное německá myš /немэцка миш/.
Ботаническая терминология также пополнилась русизмами:
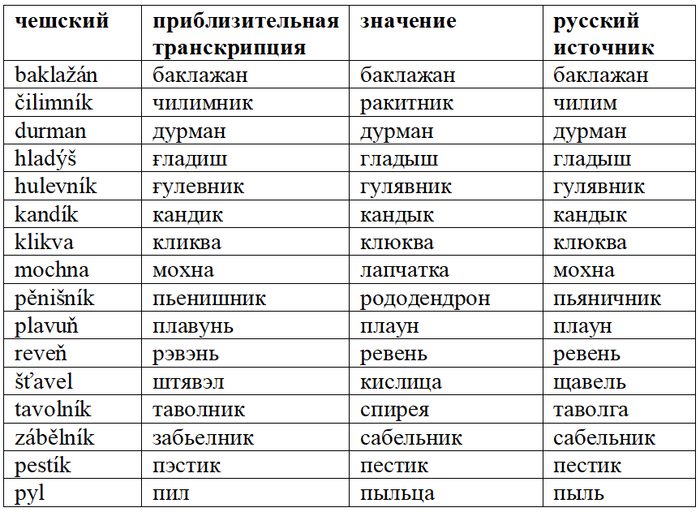
Есть термины из области химии и геологии:
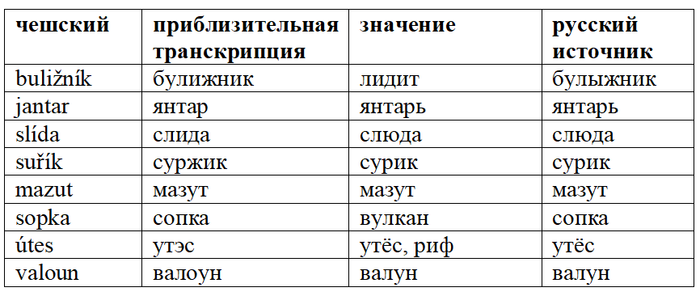
Большую группу составляют абстрактные понятия:
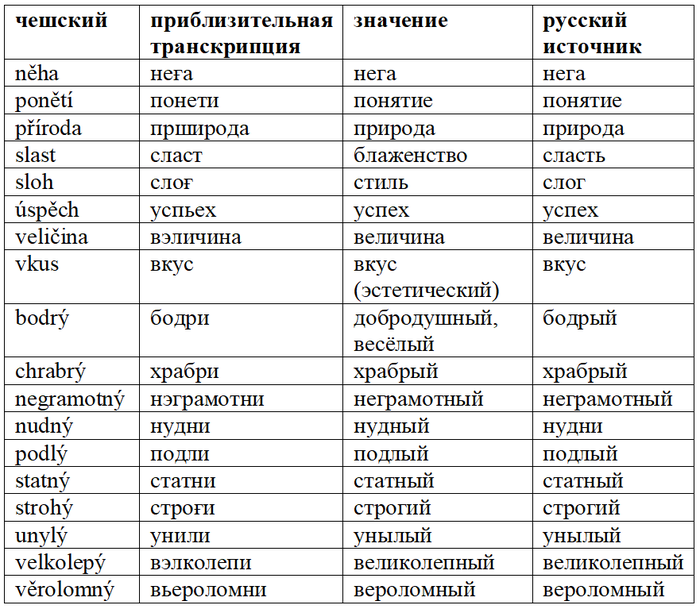
Глаголов сравнительно мало:
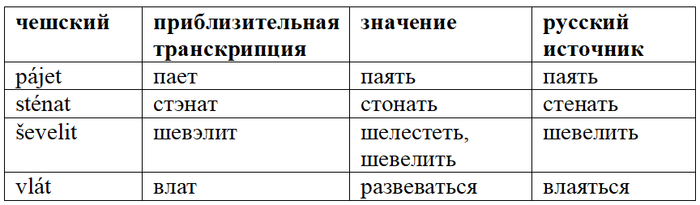
Прочие заимствования (список, конечно, не полон):
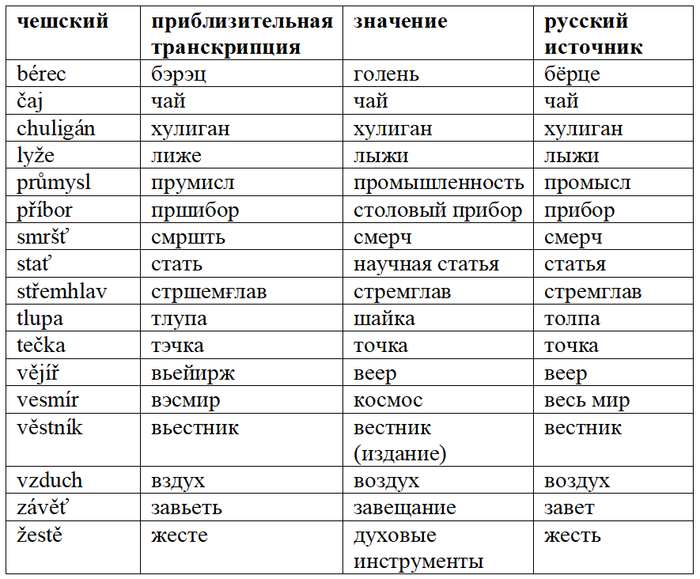
Из экспрессивной лексики были заимствованы слова svoloč /сволоч/, důra /дура/ и geroj /гэрой/. Последнее употребляется в иронических контекстах, в то время как нейтральное слово – hrdina /ғрдина/.
Как видно из таблиц, нередко русским заимствованиям пытались придать такой фонетический облик, какой они имели бы, если бы были унаследованы чешским из праславянского. В случае klikva или tlupa это сделано вполне корректно, а вот kormidlo было адаптировано лишь наполовину, правильнее было бы *krmidlo. Иногда будители серьёзно ошибались. Так, слово пьяничник было воспринято как производное от «пена», а не «пьяный» и перешло в чешский в виде pěnišník. В сабельнике также не угадали саблю (которая по-чешски будет šavle /шавле/) и проассоциировали со словом «белый», в результате чего он превратился в zábělník. В ряде случаев серьёзно менялось значение. Скажем по-русски ворвань – это вытопленный жир морских животных, а у чехов слово vorvaň стало обозначать кашалота.
Иногда заимствованию не удавалось потеснить уже имеющееся в чешском слово, и тогда происходили различные семантические сдвиги. Например, русизм dumat имеет значение «размышлять, раздумывать» (а просто «думать» будет myslet). Заимствованное ženština /женштина/ не смогло вытеснить исконное žena «жена, женщина» и приобрело негативную окраску. Наоборот, borec /борэц/, не сумев побороть собственно чешское zápasník, сейчас используется в разговорном чешском в значении «молодец» или «красавчик».
Интересный кульбит совершило чешское слово poručník /поручник/ «заместитель, опекун». В своё время оно было заимствовано в польский, где постепенно его значение сузилось до обозначения офицера в звании ниже капитана. Именно в таком смысле польское porucznik /поручник/ попало в русский язык, где стало звучать как поручик. Затем чехи заимствовали русское слово в виде poručík и уже в новом значении – «лейтенант».
За прочими подробностями отсылаю к литературе:
Rejzek J. Český etymologický slovník. Brno, 2001.
Наихудшие ученики
Если вы подумали, что эта статья будет про наших школьников, или про систему образования в целом — можете расслабиться, она совсем о другом.
Бывая за границей и общаясь с иностранцами, естественно возникает желание выучить что-нибудь на их языке, и они также будут просить вас научить их русскому.
Однако же, далеко не всем Великий и Могучий даётся одинаково легко, есть такие, которым он не даётся вообще ни на сколько.
Итак, наихудшие ученики русского языка — это гонконговцы. Почему? Да всё просто — они не умеют читать! И элементарно научиться читать для них является просто наисложнейшей задачей.

Все жители Гонконга это билингвы, или даже трилингвы. Помимо родного кантонского, вторым государственным языком там является английский (спасибо бывшим колонизаторам), также немалая часть говорит на путунхуа.
Поскольку английский у них на довольно хорошем уровне, коммуникация с внешним не представляет для местных жителей больших трудностей, а потому с изучением других языков они особо сильно не заморачиваются, ибо нет смысла. Но именно в знании своих официальных языков и заключается причина неспособности выучить другие.
Если в континентальном Китае ещё в середине прошлого века для записи произношения был разработан пиньинь, а на Тайване еще раньше чжуинь, то отрезанный от большой земли Сянган, находящийся под властью колонизаторов, эти нововведения вообще не коснулись. Они даже в компьютьере или на телефоне набирают иероглифы по ключам.
Видя как ты, лаовай, с лёгкостью набираешь текст пиньинем, они будут искренне тобой восхищаться. Ведь они то, китайцы, никак не могут его освоить, а у тебя получилось!
Их второй официальный язык — английский — также никак не способствует умению читать, а скорее даже наоборот — полностью его подавляет. Всем известно, что в английском языке нет орфографии, а слова представляют из себя набор латинских букв, который может даже близко быть не похож на то, как они произносятся. Но это понятно нам, так как у нас есть алфавит. Для людей с иероглифным мышлением каждое слово будет просто набором «ключей» в определенной последовательности, и никак не связанным с этими ключами произношением.
Если мы, или любые другие европейцы, видя незнакомое для нас слово, просто прочитаем его целиком, как оно написано, то жители Гонконга будут проговаривать его по одной буковке, как малые дети. Прочитать для них это очень сложно.
С английским же языком связано и отсутствие какой-либо логики и упорядоченности в транслитерации их собственного языка на латиницу. Если в материковом Китае пиньинь полностью стандартизирован и прикреплён к каждому иероглифу в неизменном виде, то в особой экономической зоне вариаций может быть великое множество. Например, иероглиф 九, который на кантонском произносится [кау], может быть записан как kow, kau, kou, kaw. И это будет на указателях, расположенных максимум метрах в 30 друг от друга. Самое забавное, что местных это нисколько не смущает, и они считают, что всё правильно, так и должно быть. Еще один забавный пример — там есть трамвайная станция, название которой записывается как TSZC или как-то так (да да, без гласных). После всех твоих упорных попыток это правильно произнести, выясняется, что реально она называется всего-лишь [дзы]. Уж не знаю, им самим пришло в голову так записать, или англичанам, но другие европейцы, которые видят это название, должны будут долго ломать голову над правильным прочтением.

Именно в неумении сопоставить буквы со звуками и заключается основная лингвистическая проблема в данном мегаполисе. На твою просьбу записать произношение латиницей, они страшно тупят и не знают, как это правильно сделать. Ну и ты, если запишешь им произношение русских слов или своё имя, они тоже будут не знать как его читать.
Пиньинь, кстати, они не могут освоить ещё и потому, что хоть они и говорят на путунхуа, их «кантонский путунхуа» сильно отличается от северного варианта, особенно в плане произношения, что нехило так доставляет их северным соотечественникам. Например, кантоноговорящие часто путают звуки [л] и [н] (и в английском, кстати, тоже). Они считают эти 2 звука одним и тем же, и не видят между ними разницы, по этому не всегда понятно, какое именно слово они сказали. У жителей северных провинций даже есть куча мемов на эту тему.
В общем, на старте не так много сил уходит на заучивание самого алфавита, сколько на преодоление застрявших в голове убеждений. Как оказалось, такие очевидные для нас понятия, что буквы в словах это не просто случайный набор символов, они могут означать конкретные звуки, и их можно просто читать. И читать, оказывается, их нужно всегда одинаково, а не как попало в каждом новом слове.

Героически преодолев первый этап, неожиданно натыкаешься на второй – читать то они научились, а полностью прочитать все равно не могут, проглатывают половину слова. Вместо масла будут говорить «мало», вместо вишни – «виня» и т.д. При этом ты их тыкаешь в пропущенную букву, тебе её называют, а при произношении всего слова целиком каким-то необъяснимым образом снова про неё забывают, хоть миллион раз повторяй.
Причём здесь механизм такого буквопроглатывания мне понятен не до конца – в южных диалектах сохранился довольно большой набор финальных согласных, в отличие от северных, и по идее именно у южных не должно быть с ними проблем, однако же правильно по буковкам проговаривают всё именно путунхуисты, правда, добавляя к каждой согласной слоги (масыло, вишиня).
Вот кому из азиатов русский язык даётся легче всего – так это корейцам. На фоне китайцев, прогресс у них всегда просто семимильными шагами. К тому же, в корейском языке также есть звук [ы], что не может не радовать, и, что было для меня сюрпризом, даже некое подобие падежей. А алфавит так они вообще осваивают за 1-2 вечера.
Так что если вам попадётся житель Гонконга, выучивший русский, или какой-либо другой иностранный язык – можете смело пожать ему или ей руку, этот человек преодолел просто огромное количество трудностей, прежде чем хоть что-то начал понимать.
Манкеръ — кто это?
В архивах ЗАГС города Мытищи была обнаружена такая запись.
Родилась девочка Таня в 1919 году. Отец её записан как «манкеръ при заводских банях».

Это профессия? Или это образ жизни?
Прошу вас позвать на помощь знакомых лингвистов. И, конечно, высказать ваши предположения.

Один, един, Алёна, Елена
Попросил меня @arsdor прокомментировать данное утверждение:

Для того чтобы разобраться в этом вопросе, нужно знать об одном важном фонетическом изменении, отличающем восточнославянские языки (русский, украинский, белорусский) от западно- и южнославянских.
Речь идёт о переходе начального e— в определённых условиях в o-:
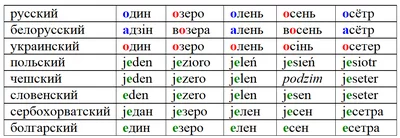
Комментарий: j произносится как й; болгарское е читается как э.
Теперь давайте посмотрим на это на диалектном материале, представленном в Общеславянском лингвистическом атласе (Выпуск №6 фонетико-грамматической серии, карта 6). На карте представлены формы слова «олень». Цветами обозначены гласные первого слога: зелёным e, красным o, синим a.
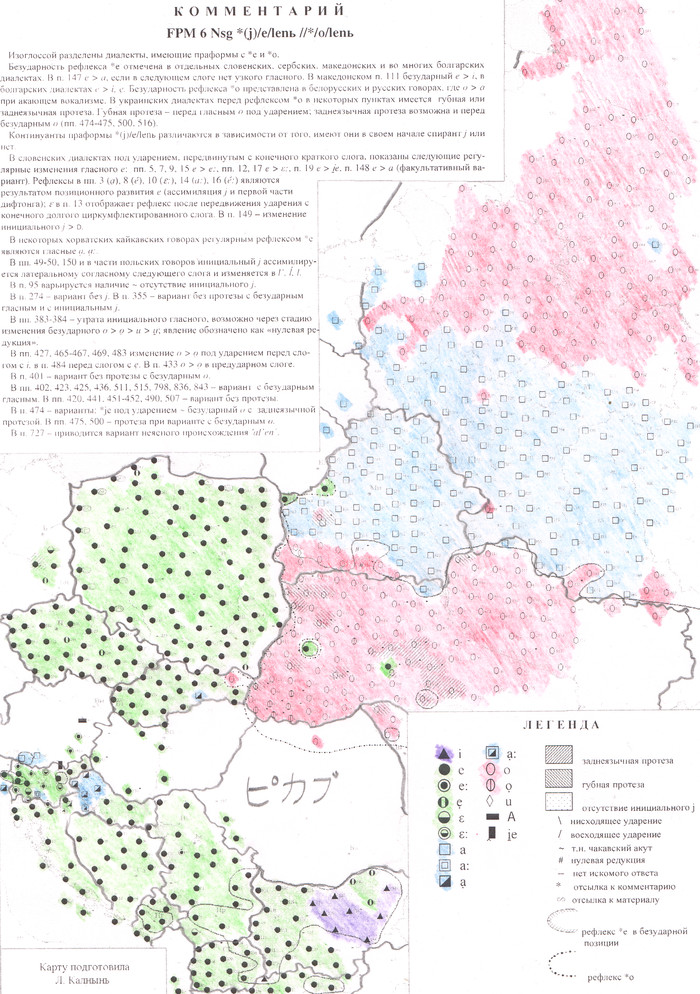
Разумеется, алень произносят в тех говорах, для которых характерно аканье, а в окающих сохраняется более старое произношение. Таким образом, синий и красный ареалы в исторической перспективе следует объединить. Картина получается довольно характерная: формы олень / алень характерны для почти всех восточнославянских говоров (есть лишь несколько пунктов, в которых мы находим полонизмы).
Действовал фонетический закон, по которому e— переходило в o-, в ту эпоху, когда наши предки позаимствовали из греческого слово ἐλάδιον «маслице». Вам оно известно как оладья.
Ещё более показательным примером являются скандинавские имена Helgi и Helga, которые в современном русском звучат как Олег и Ольга (начальное h— при заимствовании исчезло, поскольку у него не было аналога в древнерусском, см. пост об этом звуке в латыни).
Переходим к имени, вынесенному в заголовок поста. Как известно, вместе с христианством на Русь пришло большое количество имён греческого происхождения, включая Ἑλένη, которое на момент заимствования в греческом звучало как /элэни/. Окончание, понятное дело, поменяли на —а, чтобы можно было склонять. А начальное э— в народных говорах в полном соответствии с описанным выше законом перешло в о-, что даёт нам форму Олена:
В лѣто 6732. Създа Семен Борисович церковь камену святого Павла, и святого Семиона Богоприимца, и святого Констянтина и Олены. [ Новгородская Карамзинская летопись. Первая выборка (1400-1450)]
Олена – это Елена Равноапостольная, мать императора Константина Великого.
Затем в части восточнославянских говоров э переходит в о под ударением перед твёрдым согласным, что даёт нам форму Олёна. Наконец возникновение аканья приводит к появлению варианта Алёна. Обычно мы по-русски аканье на письме не отражаем, но есть и исключения (например, слова паром, калач и каракатица когда-то произносились как пором, колач и корокатица).
А форма Елена – церковнославянская, не подвергшаяся этим фонетическим изменениям, зато в ней появилось протетическое й— в начале. Долгое время Елена и Алёна воспринимались как варианты одного имени, причём второе как более народное, простое, ласковое:
Я часто заглядывала в бывшую сторожку, где жили Евгений Борисович, его жена Алена (Елена Владимировна, урожденная Шпет, внучка философа Шпета), их сын Петя, родившийся в ноябре 1958 г. [Зоя Масленикова. Близкие Бориса Пастернака (1968-2000)]
Схожая судьба была у имени Ирина. Оно тоже греческого происхождения (Εἰρήνη /ирини/ в современном произношении), и в древнерусский попало в двух вариантах – Ирина и Ерина. Второй мы находим в одном из списков «Слова о законе и благодати» митрополита Илариона:
Къ сему же виждь благовѣрную сноху твою Ерину, виждь вънукы твоа и правнукы
Обращается Иларион к князю Владимиру, а Ерина/Ирина – это Ингигерда, жена Ярослава Мудрого. Как известно, при крещении принималось христианское имя, которое использовалось наряду с языческим. Иногда при выборе нового имени старались подобрать такое, которое начинается на тот же звук, что и старое. Так Владимир стал Василием, Ингигерда Ириной, а Ярослав Георгием.
Но это я отвлёкся. Ерина подверглась тем же изменениям, что и Елена. Гласный первого слога перешёл в о-, что дало форму Орина, которую мы находим в памятниках:
Се яз, Семен Парфенов, купил есми пожню Телятевскую у Орины у Ефимьевы жены да у ее детей у Федота да у Гриди, собе и своим детем впрок; завел им в перечьных. А дал есми на них рубль да четверть да овцю пополнка. А завод той пожне по старой завод, куды коса их ходила. [Семен Парфенов. Купчая Сем. Парфенова на пожню Телятевскую, купленную у Орины Ефимьевой (1430-1460)]
Затем аканье привело к появлению формы Арина, которая тоже довольно долго не теряла связи с Ириной. Так, 5 мая (по старому стилю) – день мученицы Ирины Македонской. В народном календаре – Арины-рассадницы.
А как быть с тем, что в русском есть не только один, но и единый, и значения этих слов отчасти пересекаются (Все для мечтательницы нежной в единый образ облеклись, в одном Онегине слились)?
Ларчик открывается просто: один – исконная русская форма, а единый – церковнославянизм. В памятниках мы можем найти массу примеров, когда единъ используется именно как числительное. Цитата из Повести временных лет:
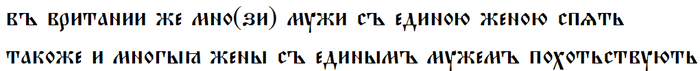
Впоследствии, значения исконно и заимствованного слов разошлись, причём, как это обычно бывает, для церковнославянизма характерно значение более абстрактное.
А вот фамилия Есенин никак не связана с церковнославянским словом есень «осень». Она образована от формы Есеня, уменьшительной от Есип, то есть Иосиф.
P.S. Насчёт Ярослава-Георгия была не шутка. Поскольку в древнерусском языке не было мягкого гь, при заимствовании его заменили на й, и греческое имя Γεώργιος в древнерусском стало звучать как Юрий или Егор.
Ковёр. История слова в мировых языках.
Мы привыкли в словосочетанию «персидский ковер». Ковер исторически ассоциируется с востоком и рукодельными промыслами. Сейчас ковры делают почти во всех странах мира.

На первый взгляд, происхождение слова, должно быть, легко найти.
Словари пишут: «Возможно«, тюркское слово. Итак, Макс Фасмер считает это слово волжско-булгарским или древне-чувашским, что указывает на До-Золотоордынское заимствование.
Путь: *kavǝr из *kebir — ср.-тюрк. kiviz (кивиз/кииз).
И вправду, в казахском «Киіз-уй — юрта», где кииз — войлочная ткань.
В казахском ковер — Кілем, в татарском — Келәм.
Наиболее близко к этому тюркскому варианту украинское слово килим (ковер). Этот же вариант в болгарском.
Но больше всего путает видимое с родство с английским словом (Сover -Кавэ’) — обложка, укрытие, чехол, покров, покрывало.
Если уж буран (аналог метели) и туман (аналог мглы) можно найти в казахском почти в первозданном виде: боран, думан (наваждение, пелена), то с ковром всё сложнее.
Вот у нас есть диковинный предмет — шатёр (от шатыр), значит должен быть и «кавыр».
Что же в славянских языках? чешский — kоbеrес, kober, в польском Dywan (диван — персизм, как ни странно это то же слово, обозначающее предмет мебели, что было заимствовано из французкого) и kobierzec, в белорусском — дыван, в словацком —koberec,
В румынском — covor.
В английском — Carpet. Слово появляется в 13-м веке в значении «грубая ткань, скатерть» и происходит от старого французского carpite. Возможно, от итальянского carpita.
Согласно этимологическим словарям слово «карпет» появилось в латыни (лат. carpita — «толстая шерстяная ткань», carpere — «щипать»)
По другому мнению слово это армянское и попало в европейские благодаря торговцам. В армянских средневековых рукописях слово «ковёр» в форме каперт (арм. կապերտ) впервые упоминается в переводе Библии ещё в V веке. Слово «каперт» образовано от корня «кап» (арм. կապ) — «узел».
В Арабском мире — «кали» / «хали» / «гали», происходит от названия ремесленного города Карина, который относился к Великой Армении, а сейчас находится в Турции.
На голландском ковер — Tapijt, на немецком — Teppich, на французком — Tarpis, на итал. Tappeto, на языке басков — Tapiz. По-литовски Kilimas, на латышском — Paklajs.
Монгольский вариант — Хивс, шведский — Matta.
Сербы и македонцы, хорваты, боснийцы говорят — тепих.
Интересен словенский вариант: Prepróga, в венгерском — szőnyeg.
Вот что написано в этимологическом онлайн-словаре Крылова Г. А. :Возможно, заимствовано из тюркских языков. Не исключено также, что имеет тот же корень, что и исчезнувшее ковора — «одеяло».
А вот словарь Шанского:Толкуется как др.-рус. заимств. из кипчакского яз. (кыпчаки — половцы),
где köwer Показать полностью
Источник статьи: http://pikabu.ru/story/yerzyanskiy_yazyik__znakomo_i_veselo_7060890