
Как сделать xml parser на PHP
Я видел много xml parser`ов, но не затрагивал при этом веб-программирование. Теперь же я хочу выяснить и научиться вместе с вами, как сделать простой xml parser в php.
Не, ну на самом деле: xml-файлы — очень полезная штука. И любой профессионал должен… нет, не должен, а обязан знать, как с ними работать. Мы же хотим стать профессионалами? Если Вы на моем блоге, то такое желание у Вас есть.
Мы предполагаем, что знаем, что такое XML и описывать его здесь не будем. Ну, если не знаем, то легко узнаем здесь: http://ru.wikipedia.org/wiki/XML
При поиске способов парсинга XML на PHP, я обнаружил простой набор функций в PHP для работы с XML-файлами, который называется «XML Parser Functions». Парсинг начинается с инициализации парсера вызовом функции xml_parser_create:
Потом нам нужно сказать парсеру, какие функции будут обрабатывать попадающиеся ему xml-теги и текстовую информацию в процессе парсинга. Т.е. нужно установить некие обработчики:
Эта функция отвечает за установку обработчиков начала элемента и конца элемента. Например, если в тексте xml-файла встретится комбинация , то функция startElement сработает, когда парсер найдет элемент , а функция endElement — при нахождении .
Сами же функции startElement и endElement принимают несколько параметров согласно документации по php:
А как же считывать данные из файла? Мы же пока не видели ни одного параметра для этого ни в одной из функций! А об этом дальше: считывание файла возлагается на плечи программиста, т.е. мы должны использовать стандартные функции для работы с файлами:
Открыли файл. А теперь нужно построчно считывать его и скармливать считываемые строки функции xml_parse:
Здесь заметим две очень важные вещи. Первая — это то, что функции xml_parse в третьем параметре нужно передать флаг считывания последней строки (true — если строка последняя, false — если нет). Второе — это то, что как и в любом деле, мы должны следить здесь за ошибками. За это отвечают функции xml_get_error_code и xml_error_string. Первая функция получает код ошибки, а вторая — по полученному коду возвращает текстовое описание ошибки. Что в результате возникновения ошибки получится — рассмотрим позже. Не менее полезная функция xml_get_current_line_number скажет нам номер текущей обрабатываемой строки в файле.
И как всегда мы должны освободить занимаемые системой ресурсы. Для парсинга XML — это функция xml_parser_free:
Вот, основные функции мы рассмотрели. Пора бы посмотреть их на деле. Для этого я придумал xml-файл с очень простой структурой:
Назовем этот файл data.xml и попытаемся его распарсить с помощью следующего кода:
В результате разработанного нами простейшего скрипта браузер вывел в свое окно следующую информацию:
Попробуем испортить XML-файл, заменив тег
на , а закрывающий тег оставив прежним:
XML Error: Mismatched tag at line 5
Ух ты! Сообщения об ошибках работают! Причем довольно информативные.
Эх, я забыл еще одну вещь… Мы же не вывели текст, содержащийся внутри тегов address и phone. Исправляем наш недочет — добавляем текстовый обработчик с помощью функции xml_set_character_data_handler:
И добавляем в код саму функцию-обработчик:
Посмотрим теперь на вывод:
Кстати, кто-нибудь заметил, что имена тегов и атрибутов все большими буквами написаны? Странно… они же в нашем xml-файле малыми буквами обозначены. Видимо где-то какие-то настройки установлены, чтобы делать uppercase…
Ааа, нашел! Оказывается есть еще функция xml_parser_set_option:
Таким вызовом мы отменяем вывод имен атрибутов и имен тегов большими буквами:
В этой статье мы рассмотрели самый простой, но для большинства задач достаточный метод вытаскивания информации из XML-файлов. Я еще слышал про какие-то другие более мощные методы, но их буду рассматривать, когда сам изучу немного
Источник статьи: http://www.internet-technologies.ru/articles/kak-sdelat-xml-parser-na-php.html
XML парсер
Все современные браузеры имеют встроенный XML парсер.
Этот XML парсер преобразует XML документ в объект XML DOM, которым затем можно манипулировать при помощи JavaScript.
Объект XMLHttpRequest
Объект XMLHttpRequest позволяет обмениваться данными в фоновом режиме.
Это настоящая сбывшаяся мечта разработчика, потому что вы можете:
- Обновлять содержимое веб-страницы не перезагружая веб-страницу
- Запрашивать данные с сервера, когда веб-страница уже загружена
- Получать данные с сервера, когда веб-страница уже загружена
- Посылать данные на сервер в фоновом режиме
Создание объекта XMLHttpRequest
Все современные браузеры (IE7+, Firefox, Chrome, Safari, Opera) уже имеют встроенный объект XMLHttpRequest.
Объект XMLHttpRequest создается следующим образом:
Старые версии браузера Internet Explorer (IE5 и IE6) используют объект ActiveXObject:
Работа с объектом XMLHttpRequest
Типичный синтаксис JavaScript для работы с объектом XMLHttpRequest выглядит следующим образом:
В строке var xhttp = new XMLHttpRequest(); создается объект XMLHttpRequest.
В строке xhttp.onreadystatechange = function() свойство onreadystatechange определяет функцию, которая будет выполняться каждый раз, когда статус объекта XMLHttpRequest изменится.
Строка if (this.readyState == 4 && this.status == 200). Когда свойство readyState равно 4, и свойство status равно 200, ответ готов.
Свойство responseText возвращает ответ сервера в виде текстовой строки.
Эта текстовая строка может использоваться для изменения кода веб-страницы. Строка document.getElementById(«demo»).innerHTML = xhttp.responseText;.
Парсинг XML документа
Следующий фрагмент кода парсит XML документ в объект XML DOM:
Парсинг XML строки
Следующий фрагмент кода парсит XML строку в объект XML DOM:
Замечение: Браузер Internet Explorer использует метод loadXML() для парсинга XML строки, в то время, как остальные браузеры используют объект DOMParser.
Доступ к данным на других доменах
Из-за соображения безопасности современные браузеры не допускают возможности обращаться к данным на других доменах.
Это означает, что веб-страница и XML файл, который она пытается загрузить, должны находиться на одном и том же сервере.
Источник статьи: http://msiter.ru/tutorials/uchebnik-xml-dlya-nachinayushchih/xml-parser
Пишем свой XML-парсер
 Решив запустить небольшой сервис на подаренном мне хостинге, оказалось, что там нету ни одного xml-парсера: ни SimpleXML, ни DOMXML, а только libxml и xml-rpc. Недолго думая, я решил написать свой. Мне требовался разбор не сложных rss-лент, поэтому хватило достаточно просто класса xml => array. [1]
Решив запустить небольшой сервис на подаренном мне хостинге, оказалось, что там нету ни одного xml-парсера: ни SimpleXML, ни DOMXML, а только libxml и xml-rpc. Недолго думая, я решил написать свой. Мне требовался разбор не сложных rss-лент, поэтому хватило достаточно просто класса xml => array. [1]
Но для интересной статьи этого было явно не достаточно, поэтому сейчас мы напишем свою замену для SimpleXML. А заодно пробежимся по многим интересным возможностям PHP 5.
Постановка задачи
Доступ к элементам у нас будет осуществляться как доступ к свойствам класса, например $xml-> element , а доступ к атрибутам элемента, как к массиву, те $xml-> element[ ‘attr’ ] , также реализуем проверку на существование атрибута при помощи isset () и итерацию по элементам при помощи foreach . И так, начнем.
Немного магии?
В PHP 5 для классов определены некоторые ‘магические’ методы, они начинаются с двойного подчеркивания ‘__’ и вызываются при происхождении определенного действия. [2] Нам понадобятся следующие:
- void __construct ([ mixed $args [, $. ]] ) — самый известный магический метод, вызывается после создания класса оператором new .
- mixed __get ( $name ) – вызывается при обращении к свойствам класса, если соответствующее поле не было найдено, например $obj-> element вызовет __get( ‘element’ ) , если element не был объявлен как поле класса.
- void __set ( $name , $value ) – соответственно вызывается при изменении свойства класса, например $obj-> element = $some_var вызовет __set( ‘element’ , $some_var ) .
- string __toString() — вызывается при любых операциях над классом, как над строкой, допустим echo $obj или strval( $obj ) . Этот метод нам потребуется для получения содержимого элемента. К сожалению, методов возвращающих не строку нету, поэтому чтобы преобразовать элемент в число придется делать так: intval(strval( $obj )) .
Standard PHP Library – стандартная библиотека PHP, как и STL из мира C++, создавалась для того, чтобы дать разработчику инструменты для решения типовых задач. [3]Нам потребуется реализовать следующие интерфейсы:
- ArrayAccess – для доступа к классу, как к массиву, например $obj [ ‘name’ ] или isset( $obj [ ‘name’ ]) .
- IteratorAggregate – для возможности итерации по классу при помощи foreach .
- Countable — чтобы узнать количество потомков у элемента.
XML и expat
Это стандартные библиотеки для работы с XML и создания XML-парсеров. [4] То, что надо для решения нашей задачи. Ради интереса можете написать разбор xml-файла вручную, допустим на регулярных выражениях.
Больше всего в expat нас интересуют следующие функции:
- bool xml_set_element_handler ( resource $parser , callback $start_element_handler , callback $end_element_handler ) – устанавливает функции, вызываемые при нахождении открытого и закрытого тегов соответственно.
- bool xml_set_character_data_handler ( resource $parser , callback $handler ) – вызывает функцию, передавая ей символьное содержание элемента, причем даже если там ничего не было, она все равно вызывается.
Примечание: callback в php это либо имя функции, переданное как строка, либо массив с двумя значениями – первое это название класса, а второе название метода этого класса.
Указатели
Указатели в PHP работают не совсем так, как в C или в C++. [5] Фактически, конструкция $a =& $b всего лишь означает, что теперь $a указывает на ту же область с данными, что и $b , причем изменить адрес куда указывает $b через $a невозможно, те можно сказать, что изменение адреса имеет один уровень вложенности.
Начиная с пятой версии, в PHP все переменные передаются в функцию по указателю, но как только вы изменяете ее значение – выделяется память под новую. В нашем случае указатели пригодятся для указания на родительский элемент.
Кодинг
class XML implements ArrayAccess , IteratorAggregate , Countable <
private $attributes = array();
public function __construct ( $data )
public function __toString ()
public function __get ( $name )
public function offsetGet ( $offset )
public function offsetExists ( $offset )
public function offsetSet ( $offset , $value )
public function offsetUnset ( $offset )
public function getIterator ()
public function appendChild ( $tag , $attributes )
public function setParent ( XML $parent ) <>
public function getParent ()
public function setCData ( $cdata ) <>
private function parse ( $data ) <>
private function tag_open ( $parser , $tag , $attributes ) <>
private function cdata ( $parser , $cdata ) <>
private function tag_close ( $parser , $tag ) <>
public function __construct ( $data ) <
list( $this -> tagName , $this -> attributes ) = $data ;
public function __get ( $name ) <
if (isset( $this -> childs [ $name ])) <
if ( count ( $this -> childs [ $name ]) == 1 )
return $this -> childs [ $name ][ 0 ];
return $this -> childs [ $name ];
throw new Exception ( «UFO steals [$name]!» );
Функции offsetGet , offsetExists , offsetSet и offsetUnset реализуют интерфейс ArrayAccess , для доступа к объекту как к массиву. Мы его используем для доступа к атрибутам элемента. offsetSet и offsetUnset оставим пока заглушками.
public function offsetGet ( $offset ) <
if (isset( $this -> attributes [ $offset ]))
return $this -> attributes [ $offset ];
throw new Exception ( «Holy cow! There is’nt [$offset] attribute!» );
public function offsetExists ( $offset ) <
return isset( $this -> attributes [ $offset ]);
А теперь мы столкнулись с проблемой из-за принятого недавно решения. Если вдруг мы захотим запустить цикл foreach по единственному элементу, то он запустится по самому xml-объекту! Поэтому придется пожертвовать возможностью простым способом использовать foreach для атрибутов элемента и реализовать метод getAttributes() . А итератор и количество элементов мы будем возвращать для массива элементов, к которому принадлежит вызываемый, а если у него нету родителя, то итератор по массиву из одного текущего элемента. Таким образом, будут реализованы интерфейсы IteratorAggregate и Countable .
return count ( $this -> parent -> childs [ $this -> tagName ]);
public function getIterator () <
return new ArrayIterator ( $this -> parent -> childs [ $this -> tagName ]);
return new ArrayIterator (array( $this ));
public function appendChild ( $tag , $attributes ) <
$element = new XML (array( $tag , $attributes ));
$this -> childs [ $tag ][] = $element ;
xml_set_object ( $parser , $this );
xml_parser_set_option ( $parser , XML_OPTION_CASE_FOLDING , false );
xml_set_element_handler ( $parser , «tag_open» , «tag_close» );
xml_set_character_data_handler ( $parser , «cdata» );
private function tag_open ( $parser , $tag , $attributes ) <
private function cdata ( $parser , $cdata ) <
$this -> pointer -> setCData ( $cdata );
private function tag_close ( $parser , $tag ) <
Все. Парсер готов к работе. Дабы не раздувать статью еще больше, полностью исходный код с комментариями я загрузил на Google Docs и пример использования тоже. [6]
Что дальше?
Это все еще не полная замена для SimpleXML, наш парсер до сих пор не умеет создавать xml-документ из данных, находящихся в нем. Добавление нужных функций не сложная задача, поэтому я ее оставлю, для тех, кому это интересно, как домашнее задание 🙂
Источник статьи: http://habr.com/ru/post/30353/
Средства парсинга XML в PHP
В личной практике задача разбирать XML средствами PHP возникла еще в 2005. Однако, при попытке разобраться и написать несложный скрипт, загружающий XML-файл в массив, я наткнулся на довольно серьёзную проблему – не существует нормальных программных средств и бинарных библиотек PHP для работы с XML. По мере работы с XML средствами PHP и эволюции PHP применялись различные технологии разбора XML кода, о них далее и пойдет речь.
Сперва приведу сводную таблицу совместимости средств PHP и библиотек XML.
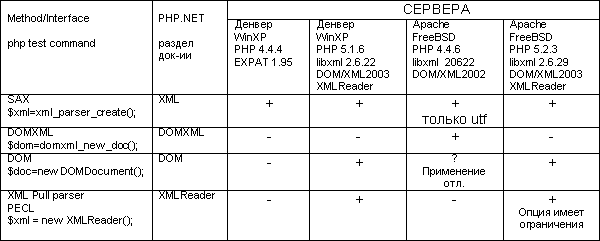
Самым совместимым оказался SAX (Simple API for XML), он поддерживается даже в библиотеке EXPAT имеющейся во всех версиях PHP 4 и выше. Однако его возможности и способы применения вызвали резко негативную реакцию – нет возможности модификации XML, крайне громоздкий и сложный код с большим количеством мест для потенциальных ошибок.
DOMXML ужасная вещь, т.к. существовала в виде дополнительных экспериментальных библиотек для PHP 4. В PHP 5 не включена, т.к. PHP 5 по умолчанию обладает более универсальным средством DOM (Стандарт W3C DOM level 3). DOM наиболее документирован (English PHP & W3C) и завершен, однако не включен в PHP 4, т.к. был разработан только к началу 2006. Если выбор станет DOM или PHP4, однозначно следует сказать DOM, т.к. на сегодняшний день PHP 5 имеется у любого уважающего себя хостинг провайдера. Тем более у разработчика, есть возможность писать PHP 4 совместимый код, т.к. PHP 4 обладает базовой DOM и она поддерживает некоторые основные функции новой DOM.
Существуют ещё дополнительные библиотеки XML-RPC, но они являются экспериментальными, что говорит само за себя – их тестирование и пробы возможны не ранее чем в 2009 году.
В Рунете небыло никакой более-менее полезной литературы на тот момент (осень 2007), все разработчики наповал использовали SAX (часто даже свои библиотеки базирующиеся на SAX) либо DOMXML. О DOM ещё мало кто слышал, а те, кто слышал, отказывались от использования в пользу более старого и менее стандартного, но более привычного DOMXML. Таким образом, имелся крайне низкий уровень реализации и переносимость существующих WEB решений использующих XML. Решение использовать новое, удобное, одобренное W3C средство DOM, было единственно правильным. DOM в PHP по его совместимости и взаимопониманию идентичен DOM’у в JS.
Проведем сравнительный анализ производительности SAX PHP 4 и DOM PHP 5. Будет произведен замер времени разбора следующего XML-файла.

SAX алгоритм разбора
// Создаем SAX парсер, который будет использоваться для обработки XML-данных.
$parser = xml_parser_create();
// Регистрируем функции для обработки различных типов
// XML-данных:
// — начальный и конечный тэги XML
xml_set_element_handler($parser,’saxStartElement’,’saxEndElement’);
// — символьные данные
xml_set_character_data_handler($parser,’saxCharacterData’);
// Также существуют аналогичные функции для регистрации
// обработчиков других типов XML-данных.
// Убираем case folding, в этом случае имена тэгов будут
// передаваться обработчикам в оригинальном виде. Если case
// folding включен, то все имена тегов будут переведены
// в верхний регистр.
xml_parser_set_option($parser,XML_OPTION_CASE_FOLDING,false);
// Получаем содержимое XML-файла с сылками.
$xml = join(»,file($link_file));
// Производим парсинг (разбор) полученного XML-файла.
// В процессе разбора парсер будет вызывать описанные нами
// функции и в результате мы получим массив $news,
// содержащий новости из XML-файла.
$GLOBALS[‘sax’][‘links’] = array(); // В этом массиве будут храниться блоки ссылок, полученные из XML файла
$GLOBALS[‘sax’][‘current_linksblock’]=null;// Текущий блок ссылок. Используется в процессе импорта данных
$GLOBALS[‘sax’][‘page_r’] =0;
$GLOBALS[‘sax’][‘page_i’] =-1;
$GLOBALS[‘sax’][‘link_r’] =0;
$GLOBALS[‘sax’][‘link_i’] =-1;
$GLOBALS[‘sax’][‘index’] =null;// Текущий индекс в массиве ссылок.
// Используется в процессе импорта данных
if (xml_parse($parser,$xml,true))
// Уничтожаем парсер, освобождая занятые им ресурсы
xml_parser_free($parser);
//else
// Парсер возвращает значение FALSE, если произошла
// какая-либо ошибка. В этом случае мы также прекращаем
// выполнение скрипта и возвращаем ошибку.
// die(sprintf(‘AOW — Ошибка XML: %s в строке %d’,
// xml_error_string(xml_get_error_code($parser)),
// xml_get_current_line_number($parser)));
//Получили массив из XML $GLOBALS[‘sax’][‘links’]; содержащий полный набор необходимых данных
dbg($GLOBALS[‘sax’][‘links’],»results»);
//————————————————————————————-
// Функции, описанные ниже, являются обработчиками различных типов
// XML-данных и будут вызываться парсером в процессе разбора.
//————————————————————————————-
// Функция для обработки начальных тегов XML
// На входе:
// — указатель на SAX парсер
// — имя XML тега
// — массив аттрибутов
function saxStartElement($parser,$name,$attrs) <
switch($name) <
case ‘links’:
// Тег links содержит все блоки ссылок. Мы должны подготовить
// массив $links для приема из XML файла.
$GLOBALS[‘sax’][‘links’] = array();
break;
case ‘linksblock’:
// Каждый блок ссылок находится в теге linksblock. Подготавливаем массив
// $GLOBALS[‘current_linksblock’] для приема
$GLOBALS[‘sax’][‘current_linksblock’] = array(«page» => array(), «link» => array());
$GLOBALS[‘sax’][‘page_r’] =0;
$GLOBALS[‘sax’][‘link_r’] =0;
$GLOBALS[‘sax’][‘page_i’] =-1;
$GLOBALS[‘sax’][‘link_i’] =-1;
// Если у новости есть random — сохраняем его в массиве
if (isset($attrs))
$GLOBALS[‘sax’][‘current_linksblock’][‘attributes’] = $attrs;
break;
case ‘page’:
$GLOBALS[‘sax’][‘page_r’]=1;
$GLOBALS[‘sax’][‘page_i’]++;
$GLOBALS[‘sax’][‘current_linksblock’][‘page’][$GLOBALS[‘sax’][‘page_i’]]=»»;
break;
case ‘link’:
$GLOBALS[‘sax’][‘link_r’]=1;
$GLOBALS[‘sax’][‘link_i’]++;
$GLOBALS[‘sax’][‘current_linksblock’][‘link’][$GLOBALS[‘sax’][‘link_i’]]=»»;
break;
>;
>
//————————————————————————————-
// Функция для обработки конечных тегов XML
// На входе:
// — указатель на SAX парсер
// — имя XML тега
function saxEndElement($parser,$name) <
if ((is_array($GLOBALS[‘sax’][‘current_linksblock’])) && ($name==’linksblock’)) <
// Если в данный момент у нас есть массив $GLOBALS[‘current_linksblock’]
// что данные для этого блока кончились и мы можем поместить готовый блок в массив ссылок.
$GLOBALS[‘sax’][‘links’][] = $GLOBALS[‘sax’][‘current_linksblock’];
$GLOBALS[‘sax’][‘current_linksblock’] = null;
> elseif($name==’page’) <
$GLOBALS[‘sax’][‘page_r’] =0;
> elseif($name==’link’) <
$GLOBALS[‘sax’][‘link_r’] =0;
>
>
// Функция для обработки символьных данных
// На входе:
// — указатель на SAX парсер
// — символьные данные XML
function saxCharacterData($parser,$data) <
// Мы принимаем только данные для блоков ссылок, помещенные в
// какой-нибудь тег. Все остальные символьные данные
// (как правило это пустое пространство, использованное
// для форматирования) мы опускаем за ненадобностью.
if (is_array($GLOBALS[‘sax’][‘current_linksblock’])) <
//Если открыт тег page то пишем в массив строки, склеивая их
if($GLOBALS[‘sax’][‘page_r’]) <
$GLOBALS[‘sax’][‘current_linksblock’][‘page’][$GLOBALS[‘sax’][‘page_i’]].= iconv(«UTF-8», «windows-1251», $data);
> elseif($GLOBALS[‘sax’][‘link_r’]) <
//Если открыт тег link то пишем в массив строки, склеивая их
$GLOBALS[‘sax’][‘current_linksblock’][‘link’][$GLOBALS[‘sax’][‘link_i’]].= iconv(«UTF-8», «windows-1251», $data);
>
>
>
//————————————————————————————-
Недостатки этого метода разбора XML очевидны: громоздкость, неудобочитаемость программного кода и необходимость использования глобальных переменных.
Приведем 2 метода разбора того же XML файла, базирующиеся на DOM PHP 5.
Метод 1
/* here we must specify the version of XML : i.e: 1.0 */
$xml = new DomDocument(‘1.0’);
$xml->load($link_file);
$linksblocksa = array();
$i=0;
foreach($xml->documentElement->childNodes as $XMLlinksblock) <
if ($XMLlinksblock->nodeType == 1 && $XMLlinksblock->nodeName == «linksblock») <
$linksblocksa[$i][‘attributes’]=array();
foreach($XMLlinksblock->attributes as $attr)
$linksblocksa[$i][‘attributes’][$attr->name]= $attr->value;
Метод использует физическую безадресную навигацию по дереву XML документа.
Метод 2
/* here we must specify the version of XML : i.e: 1.0 */
$xml = new DomDocument(‘1.0’);
$xml->load($link_file);
$i=0;
foreach($xml->getElementsByTagName(‘linksblock’) as $XMLlinksblock) <
$linksblocksb[$i][‘attributes’]=array();
foreach($XMLlinksblock->attributes as $attr)
$linksblocksb[$i][‘attributes’][$attr->name]= $attr->value;
foreach($XMLlinksblock->getElementsByTagName(‘page’) as $page)
$linksblocksb[$i][‘page’][]= $page->nodeValue;
foreach($XMLlinksblock->getElementsByTagName(‘link’) as $link)
$linksblocksb[$i][‘link’][]= iconv(«UTF-8», $GLOBALS[‘E_server_encoding’], $link->nodeValue);
$i++;
>
unset($xml);
dbg($linksblocksb,»linksblocksb»);
Метод использует ассоциативно-адресную навигацию по дереву XML документа.
В заключении замечу, что все три алгоритма в результате получают абсолютно идентичные массивы данных:

Тесты производительности алгоритмов производились с учетом следующих условий:
Платформа AMD Athlon(tm) 64 X2 Dual Core Processor 4200+, DDR 2 1024 MB.
Веб-сервер Windows NT 5.1 build 2600, Apache/1.3.33 (Win32) PHP/5.1.6.
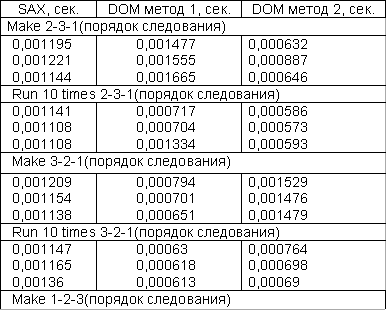
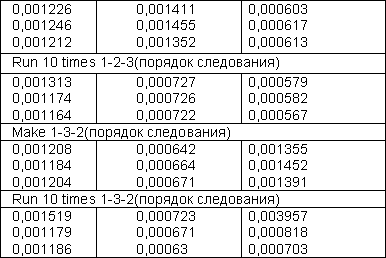

График производительности позволяет сделать следующие заключения: SAX наиболее стабилен и его производительность не зависит ни от положения в теле программы, ни от нагрузки на сервер.
Рассмотрим среднеквадратичные показатели производительности для каждой группы тестов.
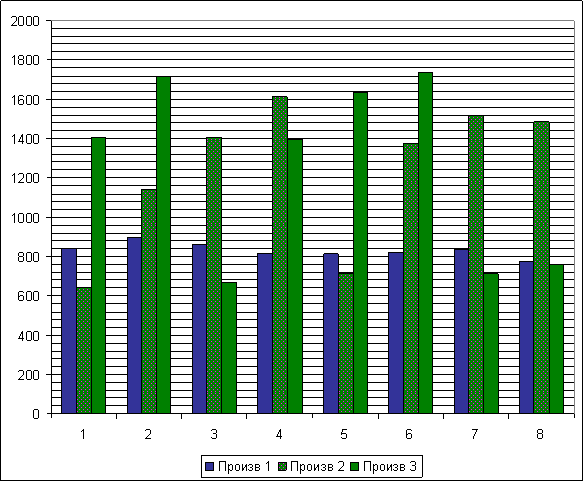
1-SAX Произв 1
2-DOM 1 Произв 2
3-DOM 2 Произв 3
Make — режим сборки, Run 10 times — режим нагрузки.
1)Make 2-3-1(порядок следования)
2)Run 10 times 2-3-1(порядок следования)
3)Make 3-2-1(порядок следования)
4)Run 10 times 3-2-1(порядок следования)
5)Make 1-2-3(порядок следования)
6)Run 10 times 1-2-3(порядок следования)
7)Make 1-3-2(порядок следования)
8)Run 10 times 1-3-2(порядок следования)
Очевидно, что наиболее важным на данном этапе анализа является выявление наиболее производительного метода разбора XML основанного на DOM, SAX не рассматриваем, т.к. его отставание и недостатки очевидны.
Напомню, метод 1 использует физическую безадресную навигацию по дереву XML документа, менее удобочитаем, чем метод 2, который использует ассоциативно-адресную навигацию по дереву XML документа.
Для нас наиболее важны режимы результаты производительности при режимах нагрузки, такими являются четные тесты:

Тесты 2 и 6, тесты в которых метод 1 идет первым, тесты 4 и 8, тесты в которых метод 2 идет первым.
Из графика следует, что при своем удобстве метод 2 достигает наивысших показателей производительности, только при многочисленном использовании XML в программе.
Метод 1, при меньшей лаконичности и пиковой производительности относительно метода 2, является более стабильным в использовании для разбора в единственном месте работы PHP скрипта.
Таким образом, переход на DOM PHP 5, в независимости от способа разбора XML документа, вполне оправдан, как по удобству кода, так и по производительности, тем более, с учетом того, что в настоящее время PHP 4 практически не используется.
Все тесты проводились кустарно, их основной задачей было показать различие а не количественные характеристики производительности того или иного парсера, очевидно, что при грамотной настройке кэширующих механизмов результаты могут отличаться.
Источник статьи: http://habr.com/ru/post/50668/