
Создание и нормализация словарей. Выбираем лучшее, убираем лишнее

Использование подходящих словарей во время проведения тестирования на проникновение во многом определяет успех подбора учетных данных. В данной публикации я расскажу, какие современные инструменты можно использовать для создания словарей, их оптимизации для конкретного случая и как не тратить время на перебор тысяч заведомо ложных комбинации.
Инструменты
Пожалуй, один из самых известных инструментов для быстрого создания словарей. Он по умолчанию входит в популярный дистрибутив для проведения пентеста Kali Linux.
Инструмент работает в нескольких режимах:
Создание словаря, состоящего из перечисленных символов, например чисел
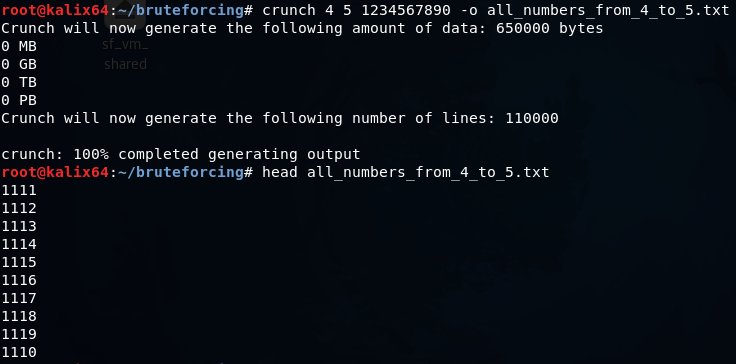
Создается словарь длиной от четырех до пяти цифр.
Создание словаря по шаблону

Сперва указывается длина пароля — 10 символов. Затем перечисляются наборы символов: буквы в нижнем регистре, буквы в верхнем регистре, цифры и спецсимволы. Ключ -t задает шаблон, где
- ^ — спецсимволы
- @ — буквы в нижнем регистре
- , — буквы в верхнем регистре
- % — цифры
И третий режим работы crunch — перестановки.
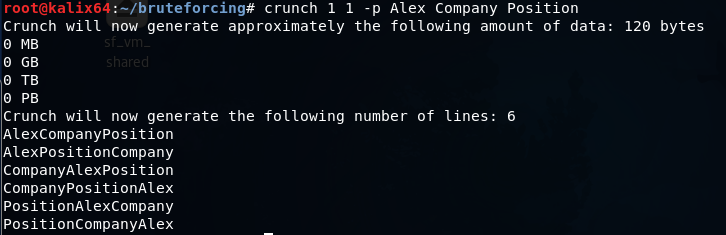
Словарь состоит из всех возможных комбинаций слов Alex, Company и Position.
Подробнее изучить инструмент можно через стандартные man страницы, они достаточно подробные.
Иногда требуется указать не только наборы под конкретный тип символов, а вообще свой набор, включающий и буквы, и цифры, и спецсимволы. В этом случае можно воспользоваться утилитой maskprocessor от брутфорсера hashcat. Скачать ее можно с официального гитхаба hashcat.
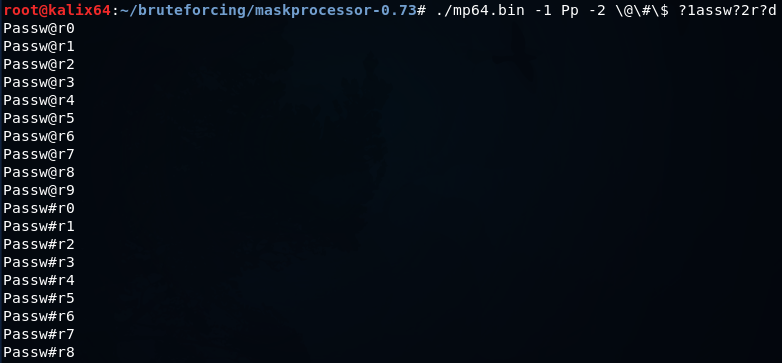
Вы можете задать до четырех собственных наборов символов и использовать готовые наборы
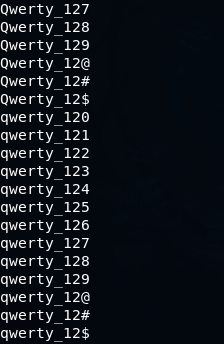
Или можно задать набор из цифр, но добавить к нему еще несколько спецсимволов так
Популярный брутфорсер John the Ripper (JTR) тоже позволяет генерировать словари на основе правил. Делается это при помощи ключа —rules, а сами правила описываются в файле john.conf
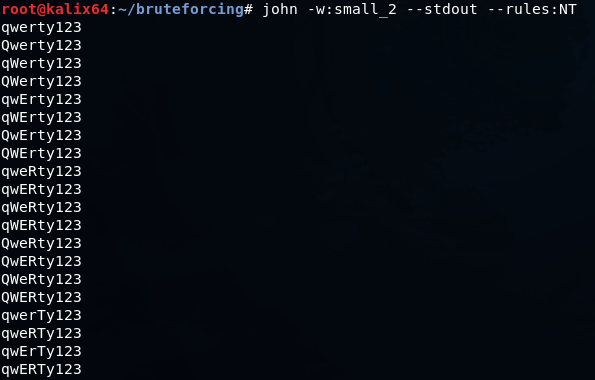
Вот так выглядит стандартное правило, используемое для взлома NTLM хэша
В первой строчке сказано, что нужно изменить регистр символа на нулевой позиции (T0), символ Q позволяет не допустить дубликатов в результирующем словаре. Во второй строке символ на первой позиции меняет свой регистр, затем скобки задают препроцессор, чтобы были сгенерированы пароли и с измененным нулевым символом и так далее.
Предположим, вы успешно провели брутфорс LM хэша и получили значение QWERTY123, так как для LM регистр не важен.
Но для авторизации вам нужно провести брутфорс NTLM хэша, где регистр имеет значение. Воспользовавшись правилом, описанным выше, можно получить следующий словарь
JTR по умолчанию содержит множество готовых правил, но можно написать и свои, либо взять за основу уже написанное и скорректировать под текущую ситуацию.
Подробно про синтаксис правил можно почитать здесь.
Еще одним полезным инструментом является набор утилит от популярного брутфорсера hashcat.
Рассмотрим некоторые их них. Описания всех утилит на английском языке можно найти тут.
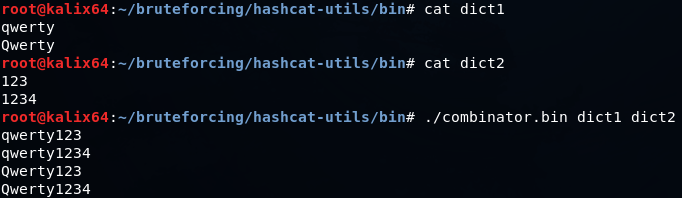
combinanor.bin — позволяет генерировать словарь из слов, входящих в два других словаря.
combinanor3.bin делает то же самое, но на вход принимает три файла, вместо двух.
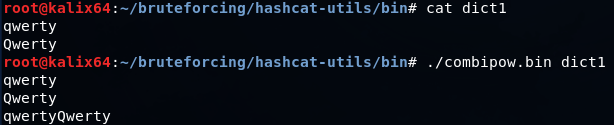
combipow.bin — создает все возможные комбинации из слов, перечисленных в файле (похоже на ключ -p в crunch)
cutb.bin — обрезает слова в словаре до указанной длины. Можно указывать смещение (offset)

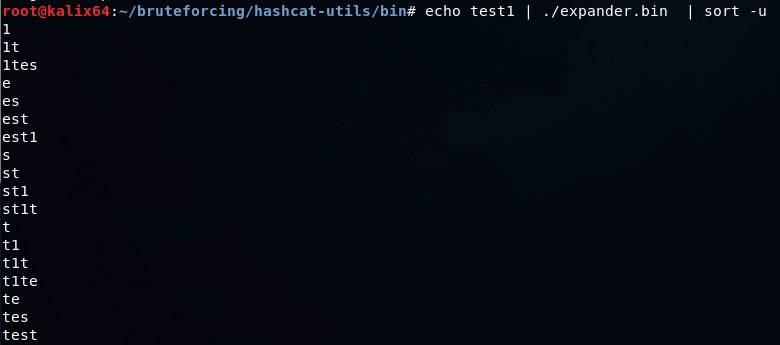
expander.bin — получает на ввод слова, разбирает их на символы, комбинирует и отправляет в STDOUT
permute.bin — создает словарь, который используется hashcat при атаке типа Permutation attack. Перед использованием словарь нужно пропустить через утилиту prepare.
gate.bin — разбивает словарь на несколько частей для параллельной обработки несколькими ядрами или несколькими машинами. В примере ниже мы разбиваем стандартный словарь JTR на две части. В первую часть попадают слова под номером 0, 2, 4, 6,…. Во вторую 1, 3, 5, 7,…
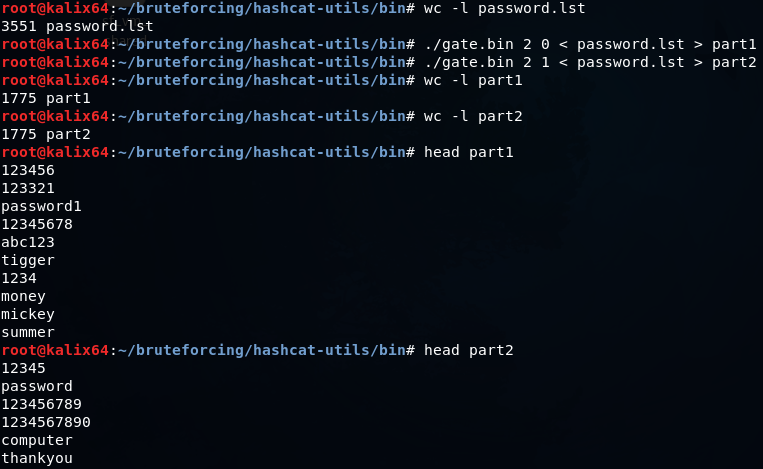
len.bin — оставляет в словаре только слова определенной длины от min до max
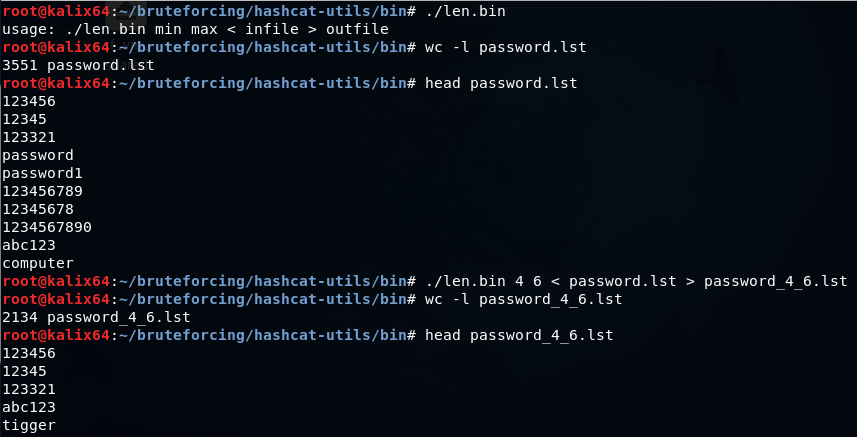
mli2.bin — объединяет два словаря.
req-include.bin — крайне полезный инструмент, который убирает из словаря все, что не подходит под заданные правила. Например, вы знаете, что по парольной политике в пароле обязательно присутствует буква в верхнем регистре, цифра и спецсимвол.

Число выбрано исходя из таблицы

Если таким образом нормализовать известный словарь rockyou, то можно сократить его размер в 270 раз! и не тратить ресурсы на заведомо ложные комбинации.

req-exclude.bin делает то же самое, что req-include, но с точностью до наоборот.
rli.bin — эта утилита удаляет значения из первого словаря, если они встречаются во втором. Полезно использовать, если вы создаете один словарь из нескольких.
Когда под рукой нет утилит
Может оказаться так, что воспользоваться набором hashcat-utils или crunch нет возможности, а нужно срочно создать словарь или нормализовать его. Некоторые алгоритмы довольно сложны в реализации, но базовые операции можно выполнить просто в командной строке.
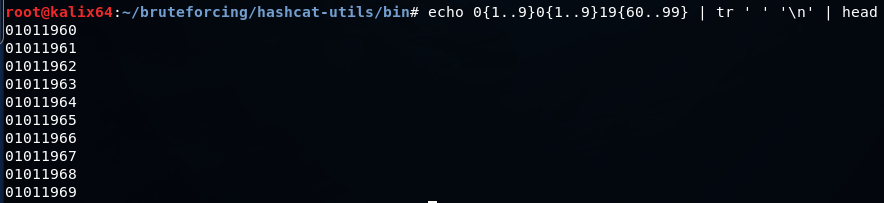
Простой словарь с датами можно создать серией подобных команд
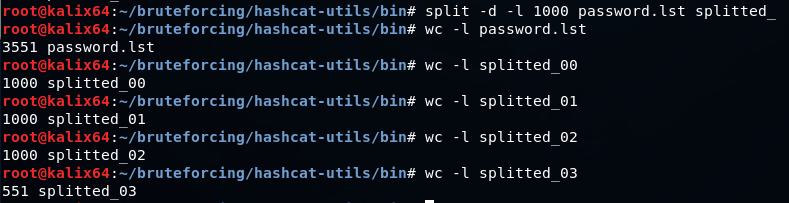
Если нужно разбить словарь на части для параллельной обработки, можно воспользоваться командой split
Быстро объединить два словаря можно так
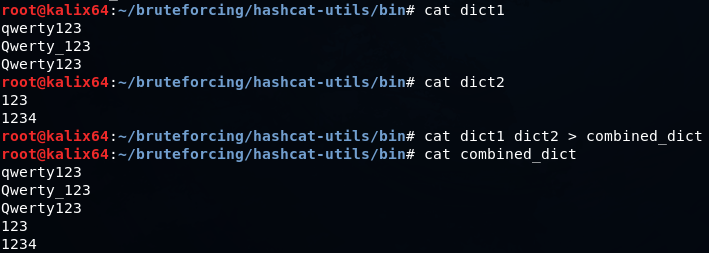
Чтобы сделать заглавной первую или последнюю буквы в каждом слове, нужно выполнить, соответственно, команды
Для перевода регистра в нижний нужно заметить «u» на «l»
Дописать что-то в начало каждого слова из словаря можно так
А так можно дописать слово в конец
Следующей командой можно добавить в начало число от 0 до 99 к каждому слову в словаре
Можно очистить словарь от значений, в которых не присутствует хотя бы 2 числа так
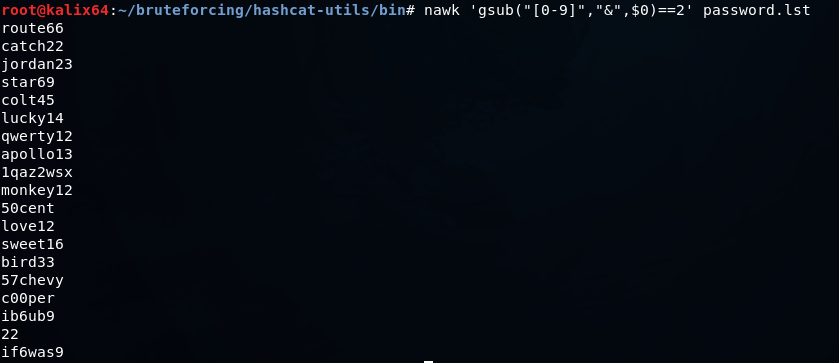
Это лишь некоторые примеры. Можно писать более сложные обработки на Python и других скриптовых языках. Но всегда нужно помнить, что создание качественного словаря и его нормализация под целевой протокол — важный этап при проведении тестирования на проникновение.
Источник статьи: http://habr.com/ru/company/pentestit/blog/337718/
Как создать РАБОЧИЙ СЛОВАРЬ для брута паролей в Kali Linux?
 Zip File, мамкины хацкеры. Под одним из последних роликов про взлом почтового ящика, один камрад написал весьма занятный коммент. Если в вкратце, то суть его в следующем, мол самое сложное в бруте – это найти путный словарь. И с этим действительно не поспоришь. Ведь чаще всего изначально даже неизвестно из скольки символов состоит подбираемый пароль у объекта тестирования. Что уж там говорить о реально действенной комбинации, которая точно сработает.
Zip File, мамкины хацкеры. Под одним из последних роликов про взлом почтового ящика, один камрад написал весьма занятный коммент. Если в вкратце, то суть его в следующем, мол самое сложное в бруте – это найти путный словарь. И с этим действительно не поспоришь. Ведь чаще всего изначально даже неизвестно из скольки символов состоит подбираемый пароль у объекта тестирования. Что уж там говорить о реально действенной комбинации, которая точно сработает.
Именно по этой причине злоумышленники в случае серьёзных атак крайне редко применяют исключительно общедоступные словари. Тут нужно уже задействовать навыки социальной инженерии.
Если точнее, то просто взять и дополнить словарь всеми известными сведениями о жертве. Имя, фамилия, родной город, кличка любимца, марка и номер сотового, всё это реально может помочь злоумышеннику повысить процент успешной атаки в тысячу раз.
Нынче, я наглядно продемонстрирую вам, каким образом происходит генерация паролей для словаря брута с использованием сведений о персональных данных среднестатистического человека. Если интересно, устраивайтесь по удобнее и будем начинать.
Шаг 1. Запускаем Kali Linux. Я работаю в версии 2020 года. Если впервые заглянул на канал и не понимаешь, что к чему, в углу появится ссылочка на ролик, в котором описана самая быстрая установка данной операционки на виртуалку. Вводим команду для обновления списка пакетов: «apt-get update».

Шаг 2. И дождавшись подтягивания обнов вводим партянку отвечающую за копирование небольшого срипта для генерации паролей с гитхаба. Все команды, кстати, будут в описании. Так что не заморачивайся с запоминанием.

Шаг 3. Заходим в появившийся каталог Passwords.

Шаг 4. И запускаем скрипт «passgen» написанный на питоне.
Шаг 5. Программа предлагает нам ввести ключевые слова для добавления в генератор. Вводить их нужно не через запятую, а по одному в каждой строчке. Для примера укажу самые базовые сведения. Имя, фамилию, отчество, город детства, кличку питомца, номер мобильного, тут можно указать несколько вариантов, с восьмеркой, с +7, без восьмёрки. Чем больше, тем лучше.
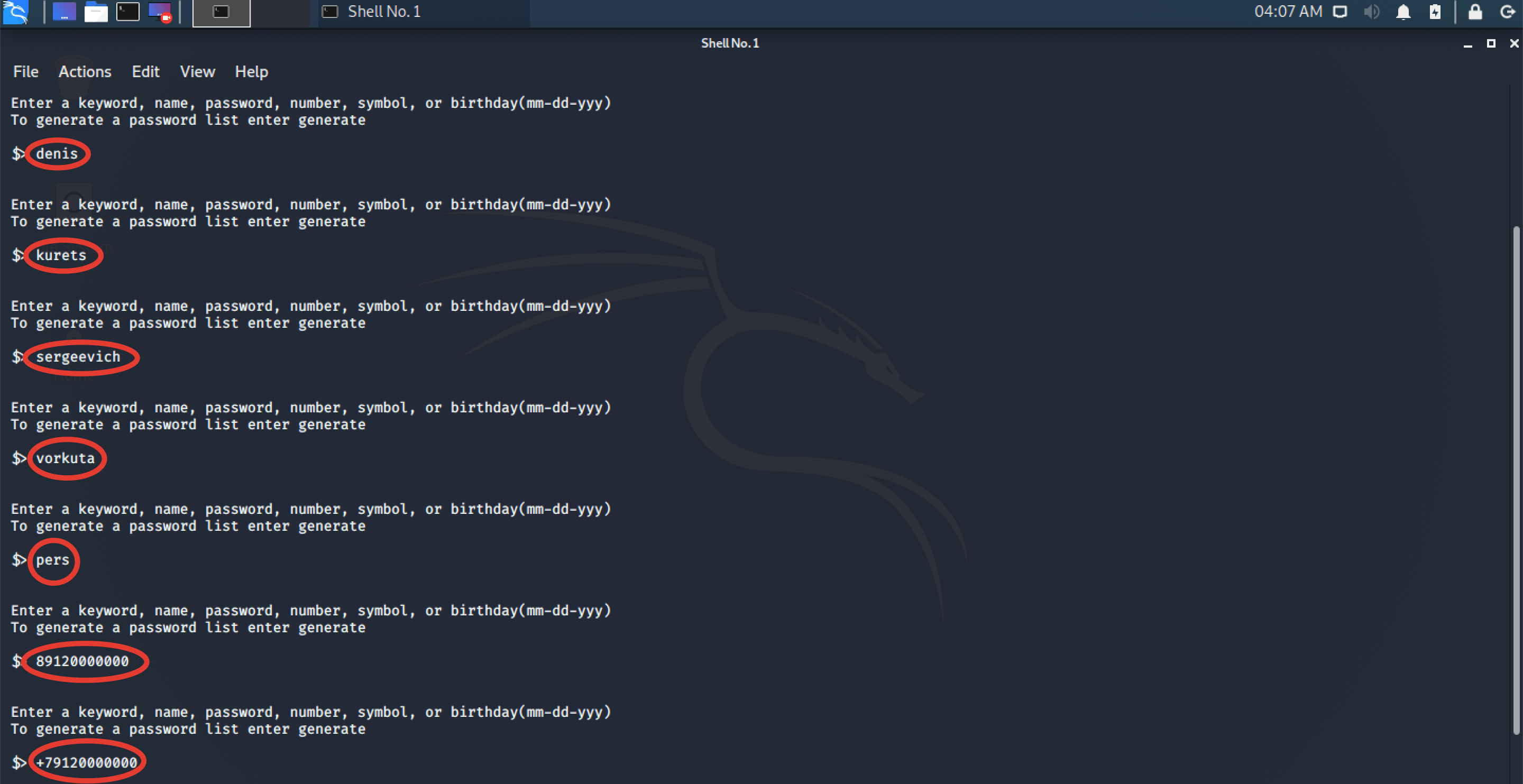
Шаг 6. Как только все известные вам сведения будут внесены, вводим «generate» и смотрим какое количество комбинаций смогла сгенерировать программулинка. Нехило.

Шаг 7. Для просмотра переходим в каталог Passwords. Открываем pass.txt.
Шаг 8. И видим массу возможных вариантов с паролями, не взятых с неба и из общедоступных источников, а основанных конкретно на реальных сведениях о предполагаемой жертве.
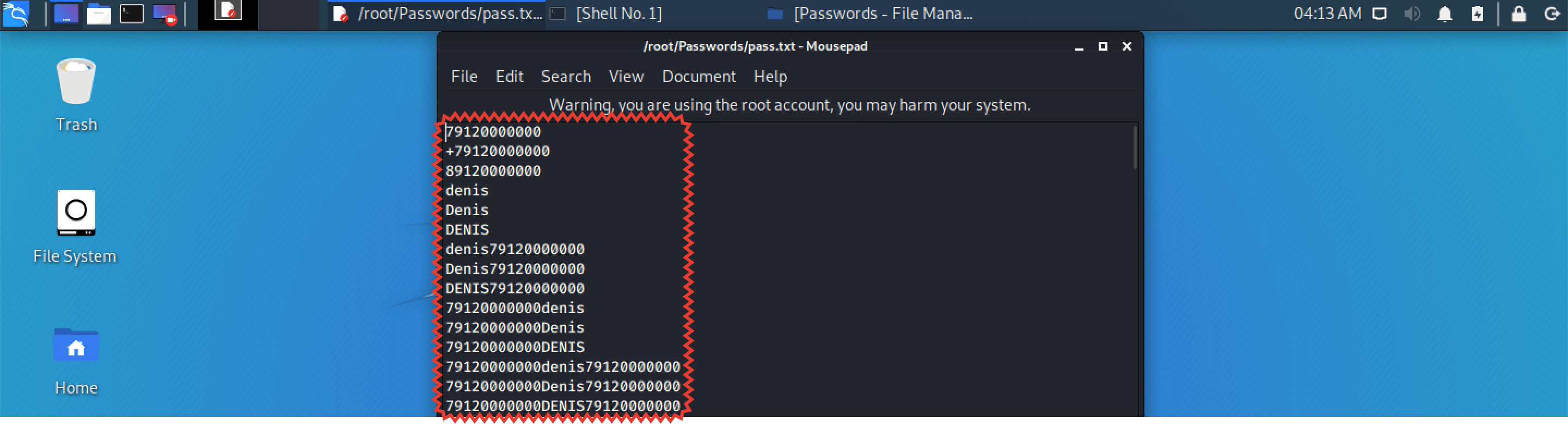
Именно таким образом злоумышленники и подбирают пароли к почтовым ящикам, аккаунтам в социальных сетях и персонифицированным Wi-Fiсоединениям.
Друзья, если вы хотите научиться работать в Linux так же лихо, как генерировать рабочие пароли для взлома, то обязательно обратите внимание на мой обучающий курс «Администрирование Linux с нуля».
В нём я максимально подробно рассматриваю работу с наиболее распространённой серверной операционной системой семейства Linux. А если хотите немножко сэкономить, то вам вообще повезло. На сегодняшний день всё ещё действует 50% скидка на его предзаказ. Ссылку со всеми подробностями ищите в описании.

>>>КЛИКНИТЕ, ЧТОБЫ УЗНАТЬ ПОДРОБНОСТИ
На этом у меня всё. Искренне желаю вам удачи, успеха и безопасного сёрфинга. Берегите себя и свои аккаунты. Устанавливайте сложные пароли и по возможности никогда не сообщайте сведения о себе посторонним людям.
С вами был Денис Курец. Благодарю за просмотр. Если впервые зашёл на канал, то не забудь клацнуть колокол. С олдов, как обычно, по лайку. Очень жду ваших новых комментов. До новых встреч, братцы. Всем пока.
Источник статьи: http://kurets.ru/information-security/194-kak-sozdat-slovar-dlya-bruta-kali-linux
Как написать словарь для брута
[graytable]Создаём «правильные» словари для брута хэшей.
Многие из Вас пользовались программой PasswordsPro для брута хэшей, скачивали словари часто употребляеммых в качестве паролей слов, использовали их и в который раз убеждались что эффективность использования их достаточно мала — множество хэшей остаются не расшифрованными. Тогда многие переходили к бруту полным перебором и так же убеждались в том, что полный перебор эффективен только в случае короткого пароля и использования ограниченного набора символов, в остальных случаях на обычном компьютере, при скорости перебора 5млн. паролей в сек брут достаточно сложного и длинного пароля может длиться столетиями.
У многих наверно возникала мысль, а не сгенирировать ли нам свои словарики? типа lamerwords ? Ну тут сразу встаёт вопрос по каким правилам их генерить? Если полный перебор — это опять же — не хватит места на диске чтоб всё добро это хранить.
В этой статье я расскажу как правильно генерировать свои словарики, чтоб процент попадания в них реальных паролей был достаточно высок.
Начнём с устоявшихся правил и человеческой психологии:
1 . Всё знают и все админы говорят используйте одновременно в пароле буквы и цифры, а ещё лучше и спец символы.
2 . Не делайте слишком короткий пароль!
Обычный не далёко продвинутый юзер сделает пароль вида lamer_2007 — и что? он не нарушил устоявшихся правил — есть буквы и цифры и длинна 9 символов — что уже не мало (с точки зрения PasswordsPro полный перебор паролей этого диапазона займёт более 10 тыс. дней)
Другой возьмёт и использует в пароле номер своей (чужой мобилы) например 9XX-XXXXXXX, что тоже для PasswordsPro является длительной задачей. Многие поняли к чему я клоню. Вроде как определённые правила соблюдаются (длинный пасс, буквы и символы) но пароль для юзера остаётся простым для запоминания и использования и в тоже время недостижимым для PasswordsPro в плане подбора полным перебором.
1 . Оцениваем психологию юзверей (или правила продвинутых ламеров в выборе пароля)
а) Кому-то лень придумывать пароль и он использует в качестве пароля ник, не забудем про это.
б) Более продвинутый ламер использует пароль никxxxx (ник_xxxx, ник-xxxx) — где xxxx — цифры (обычно от 4 до 6 знаков)
в) Ещё более продвинутый ламер использует пароль wordxxxx (word_xxxx, word_xxxx) — где word — легко запоминающееся слово, xxxx цифры (обычно от 4 до 6 знаков).
г) Многим юзверям просто лень переключать регистр клавиатуры несколько раз и максимум на что они способны — сделать это в начале, т. е. первая буква в пассе (как и у ника) может быть заглавной (но редко). (Word_xxxx)
д) Отдельный интерес представляют юзвери, набирающие пароль в латинице но в русской раскладке т. е например kfvth_2007 (т.е. ламер_2007) не будем забывать и про таких.
Вывод, как мы видим типичный пароль продвинутого ламера представляет следующую конструкцию xyz, где:
x — слово, ник и т.п. от 4 до 8 символов
у — спецсимвол, чаше всего «-«, «_» а может и совсем отсутствовать.
z — число от 4 до 6 знаков (в качестве 4-х цифр чаще может быть использован год рождения или год регистрации), в качестве 6 например дата рождения (в формате ДДММГГ или ГГММДД)
Всё изложенное в п.1 о тех, кто придумывал пароли сам для лёгкого запоминания, не пользовался менеджерами и генераторами паролей (или в тот момент у них небыло их под рукой).
Ставим задачу сгенерировать словари, удовлетворяющие этим условиям, которые могут содержать потенциальные пароли продвинутых ламеров.
а) Начнём пожалуй с третей части пасса, т. е. с цифр. Если ламер использовал год то, имхо есть смысл ограничится годами его возможного рождения или регистрации. Выбираем возростной порог юзверя 40 лет к примеру. В этом случае диапазон годов рождения будет 1967-2007 и составит всего 41 возможное значение.
Далее если дата рождения в формате ДДММГГ диапазон дат составит 010167 — 020307 и возможных значений тут будет больше — 14671. Отдельно тут надо упомянуть о незначащем нуле в начале. Вряд ли кто будет его кто-то использовать в наборе своей даты рождения, так что есть смысл его опустить (в этом случае получим пятизначную цифренную часть пасса).
Вообщем путём несложных манипуляций с Exel и обычным блокнотом, я за 5 мин. получаю все возможные мне значения (кто неумеет пользоваться может написать прогу генерирующую нужные даты):
А именно: четырёхзначные в формате ГГГГГ (41 значение)
Пятизначные в формате ДММГГ (4340 значений)
Шестизначные в формате ДДММГГ (10331 значений)
Шестизначные в формате ГГММДД (14671 значений) по поводу нуля перед годом, имхо отбрасывать не стоит — редко кто пишет год одной цифрой.
Предложенные мной варианты числовой части пасса — сугубо моё личное представление, наиболее, как мне кажется лучше отвечающее реальности (вы можете генерировать любые, всё зависит от вашей фантазии, главное чтоб в цифрах была хоть какая-то логика)
Итого получаем 41+4340+10331+14671=29383 значение возможной третей части пасса. Записываем их построчно (копи-пастим конечно ;-)) в блокнот, сохраняем в файл и получаем файл z.txt размером всего 226 Кб. — он содержит даты рождения или даты регистрации юзверя возрастом до 40 лет в предложенных мной форматах.
Ах, да, не забудем про дубли (вполне возможно они присутствуют так как инвертировали формат даты). Для очистки дублей (да и не только) я воспользуюсь утилитой V-ListmakeR (вообще-то она для генерации листов для брута асек вида UIN;PASS, но там есть модуль работы со словарями и джоинер). Итого после убиения дублей остается 19052 значения, а размер сокращается до 144КБ.
б) Ну а с первой частью всё понятно — берём все имеющиеся у вас пассы или ники и режем их до 8 символов (при необходимости, или отфильтровываем то что больше восьми). Хочу заметить что вам нужно будет собрать их в один файл, так как потом нам потребуется склейка с третьей частью. И хочу обратить внимание не переборщите с количеством значений в этом файле, так как при склейке размер у нас будет расти в геометрической прогрессии.
Я для примера беру ники Ачатовцев, кто в онлайн в данный момент, убираю запятые, загоняю в файл, получается всего 59 значений  , обзываю x.txt. Всё готово для генерации словарей.
, обзываю x.txt. Всё готово для генерации словарей.
Генерим (склеиваем) с помощью того же V-ListmakeR (оказывается от клеит не только номер;пасс, а всё что угодно).
Выбираем вкладку JoineR Load Unins File грузим Ваш x.txt, Load Pass File грузим z.txt. В качестве сепаратора (разделитель) выбираем любой спецсимвол, я взял «_».
Клацаем Save To xyz.txt, нажимаем Start и ждём. Итого у меня получился словарь состоящий из потенциально возможных паролей ачатовцев 😉 (включающий ник и дату рождения). Всего 1124068 слов (значений). Размер файла 17,1 МБ
Используя разные сепараторы вы можете наделать себе сколь угодно много таких словарей.
Многие скажут, зачем такой гимор ведь всё есть в PasswordsPro (они имеют ввиду комбинированную атаку по словарям). Им отвечу: во-первых посмотрите на скорость работы при такой атаке. Во вторых там идёт много перестановок слов из словарей, что нам не требуется! Также нам не всегда подойдёт то, что может сгенирировать генератор словарей, а также генератор паролей, даже если использовать генерацию по маске «символы(8):спецсимвол(1):число(6)» (то есть маска ?l?l?l?l?l?l?l?l?s?d?d?d?d?d?d) Вы получите кучу отличных паролей и ИМХО врядли туда попадёт хоть один наш продвинутого ламера! (Собственно для этого генератор и сделан ;-), чтоб генерировать хорошие пароли, а вот словари из него я не уверен что хорошие будут).
Кстати таким же образом делаем словарик, включающий все возможные номера известных операторов сотовой связи (большой наверно будет).
Источник статьи: http://hack-port.ru/forum/165-3294-1