
Пишем программу для автоматического распознавания объектов с веб-камер

В OpenCV существует множество вариантов для трансляции видеопотока. Можно использовать один из них – IP-камеры, но с ними бывает довольно трудно работать. Так, некоторые IP-камеры не позволяют получить доступ к RTSP-потоку (англ. Real Time Streaming Protocol). Другие IP-камеры не работают с функцией OpenCV cv2.VideoCapture . В конце концов, такой вариант может быть слишком дорогостоящим для ваших задач, особенно, если вы хотите построить сеть из нескольких камер.
Как отправлять видеопоток со стандартной веб-камеры с помощью OpenCV? Одним из удобных способов является использование протоколов передачи сообщений и соответствующих библиотек ZMQ и ImageZMQ.
Поэтому сначала мы кратко обсудим транспорт видеопотока вместе с ZMQ, библиотекой для асинхронной передачи сообщений в распределенных системах. Далее, мы реализуем два скрипта на Python:
- Клиент, который будет захватывать кадры с простой веб-камеры.
- Сервер, принимающий кадры и ищущий на них выбранные типы объектов (например, людей, собак и автомобили).
Для демонстрации работы узлов применяются четыре платы Raspberry Pi с подключенными модулями камер. На их примере мы покажем, как использовать дешевое оборудование в создании распределенной сети из камер, способных отправлять кадры на более мощную машину для дополнительной обработки.
Передача сообщений и ZMQ
Передача сообщений – парадигма программирования, традиционно используемая в многопроцессорных распределенных системах. Концепция предполагает, что один процесс может взаимодействовать с другими процессами через посредника – брокера сообщений (англ. message broker). Посредник получает запрос, а затем обрабатывает акт пересылки сообщения другому процессу/процессам. При необходимости брокер сообщений также отправляет ответ исходному процессу.
ZMQ является высокопроизводительной библиотекой для асинхронной передачи сообщений, используемой в распределенных системах. Этот пакет обеспечивает высокую пропускную способность и малую задержку. На основе ZMQ Джефом Бассом создана библиотека ImageZMQ, которую сам Джеф использует для компьютерного зрения на своей ферме вместе с теми же платами Raspberry Pi.
Начнем с того, что настроим клиенты и сервер.
Конфигурирование системы и установка необходимых пакетов

Сначала установим opencv и ZMQ. Чтобы избежать конфликтов, развертывание проведем в виртуальной среде:
Теперь нам нужно клонировать репозиторий с ImageZMQ:
Далее, можно скопировать директорию с исходником или связать ее с вашим виртуальным окружением. Рассмотрим второй вариант:
Библиотеку ImageZMQ нужно установить и на сервер, и на каждый клиент.
Примечание: чтобы быть увереннее в правильности введенного пути, используйте дополнение через табуляцию.
Подготовка клиентов для ImageZMQ
В этом разделе мы осветим важное отличие в настройке клиентов.
Наш код будет использовать имя хоста клиента для его идентификации. Для этого достаточно и IP-адреса, но настройка имени хоста позволяет проще считать назначение клиента.
В нашем примере для определенности мы предполагаем, что вы используете Raspberry Pi с операционной системой Raspbian. Естественно, что клиент может быть построен и на другой ОС.
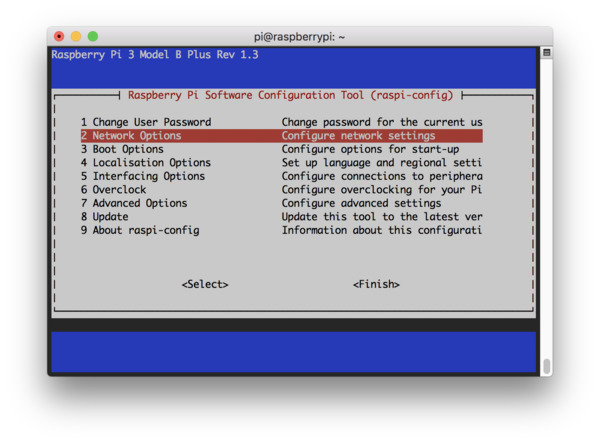
Чтобы сменить имя хоста, запустите терминал (это можно сделать через SSH-соединение) и введите команду raspi-config :
Вы увидите следующее окно терминала. Перейдите к пункту 2 Network Options.
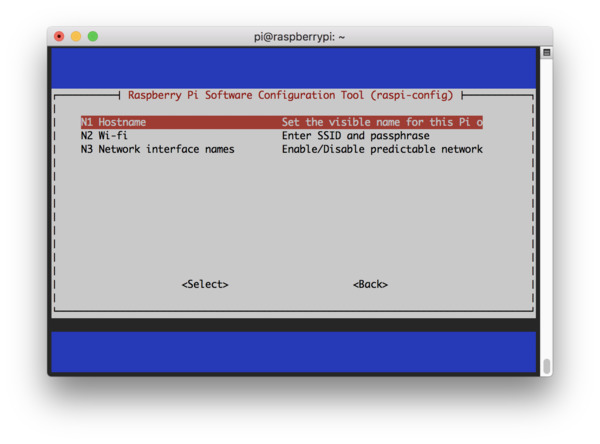
На следующем шаге выберите опцию N1 Hostname.
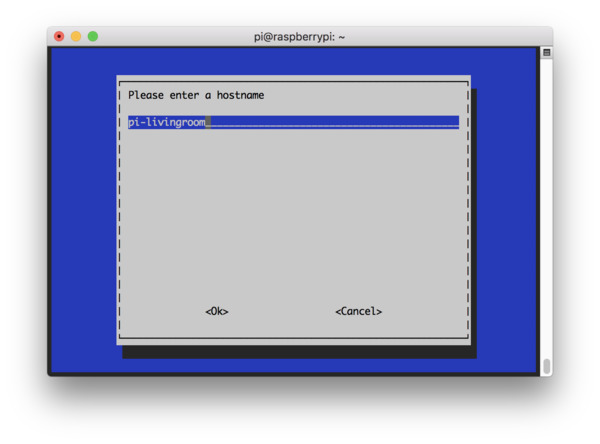
На этом этапе задайте осмысленное имя хоста (например, pi-livingroom, pi-bedroom, pi-garage). Так вам будет легче ориентироваться в клиентах сети и сопоставлять имена и IP-адреса.
Далее, необходимо согласиться с изменениями и перезагрузить систему.
В некоторых сетях вы можете подключиться через SSH, не предоставляя IP-адрес явным образом:
Определение отношений сервер-клиент
Прежде чем реализовать стриминг потокового видео по сети, определим отношения клиентов и сервера. Для начала уточним терминологию:
- Клиент – устройство, отвечающее за захват кадров с веб-камеры с использованием OpenCV, а затем за отправку кадров на сервер.
- Сервер — компьютер, принимающий кадры от всех клиентов.
Конечно, и сервер, и клиент могут и принимать, и отдавать какие-то данные (не только видеопоток), но для нас важно следующее:
- Существует как минимум одна (а скорее всего, несколько) система, отвечающая за захват кадров (клиент).
- Существует только одна система, используемая для получения и обработки этих кадров (сервер).
Структура проекта
Структура проекта будет состоять из следующих файлов:
Два первых файла из списка соответствуют файлам предобученной нейросети Caffe MobileNet SSD для распознавания объектов. В репозитории по ссылке можно найти соответствующие файлы, чьи названия, правда, могут отличаться от приведенных ( *.caffemodel и deploy.prototxt ). Сервер ( server.py ) использует эти файлы Caffe в DNN-модуле OpenCV.
Скрипт client.py будет находиться на каждом устройстве, которое отправляет поток на сервер.
Реализация клиентского стримера на OpenCV
Начнем с реализации клиента. Что он будет делать:
- Захватывать видеопоток с камеры (USB или RPi-модуль).
- Отправлять кадры по сети через ImageZMQ.
Откроем файл client.py и вставим следующий код:
Назначение импортируемых модулей описано в комментариях. В последних строчках создается объект-отправитель, которому передаются IP-адрес и порт сервера. Указанный порт 5555 обычно не вызывает конфликтов.
Инициализируем видеопоток и начнем отправлять кадры на сервер.
Теперь у нас есть объект VideoStream , созданный для захвата фреймов с RPi-камеры. Если вы используете USB-камеру, раскомментируйте следующую строку и закомментируйте ту, что активна сейчас.
В этом месте вы также можете установить разрешение камеры. Мы будем использовать максимальное, так что аргумент не передастся. Если вы обнаружите задержку, надо уменьшить разрешение, выбрав одно из доступных значений, представленных в таблице. Например:
Для USB-камеры такой аргумент не предусмотрен. В следующей строке после считывания кадра можно изменить его размер:
В последних строках скрипта происходит захват и отправка кадров на сервер.
Реализация сервера
На стороне сервера необходимо обеспечить:
- Прием кадров от клиентов.
- Детектирование объектов на каждом из входящих кадров.
- Подсчет количества объектов для каждого из кадров.
- Отображение смонтированного кадра (панели), содержащего изображения от всех активных устройств.
Последовательно заполним файл с описанием сервера server.py :
Библиотека imutils упрощает работу с изображениями (есть на GitHub и PyPi).
Пять аргументов, обрабатываемых с помощью парсера argparse :
- —prototxt : путь к файлу прототипа глубокого изучения Caffe.
- —model : путь к предообученной модели нейросети Caffe.
- —confidence : порог достоверности для фильтрации случаев нечеткого обнаружения.
- —montageW : количество столбцов для монтажа общего кадра, состоящего в нашем примере из 2х2 картинок (то есть montageW = 2) . Часть ячеек может быть пустой.
- —montageH : аналогично предыдущему пункту — количество строк в общем кадре.
Вначале инициализируем объект ImageHub для работы с детектором объектов. Последний построен на базе MobileNet Single Shot Detector.
Объект ImageHub используется сервером для приема подключений от каждой платы Raspberry Pi. По существу, для получения кадров по сети и отправки назад подтверждений здесь используются сокеты и ZMQ .
Предположим, что в системе безопасности мы отслеживаем только три класса подвижных объектов: собаки, люди и автомобили. Эти метки мы запишем в множество CONSIDER , чтобы отфильтровать прочие неинтересные нам классы (стулья, растения и т. д.).
Кроме того, необходимо следить за активностью клиентов, проверяя время отправки тем или иным клиентом последнего кадра.
Далее необходимо зациклить потоки, поступающие от клиентов и обработку данных на сервере.
Итак, сервер забирает изображение в imageHub , высылает клиенту сообщение о подтверждении получения. Принятое сервером сообщение imageHub.recv_image содержит имя хоста rpiName и кадр frame . Остальные строки кода нужны для учета активности клиентов.
Затем мы работаем с кадром, формируя блоб (о функции blobFromImage читайте подробнее в посте pyimagesearch). Блоб передается нейросети для детектирования объектов.
Замечание: мы продолжаем рассматривать цикл, поэтому здесь и далее будьте внимательны с отступами в коде.
Теперь мы хотим пройтись по детектированным объектам, чтобы посчитать и выделить их цветными рамками:
Далее, аннотируем каждый кадр именем хоста и количеством объектов. Наконец, монтируем из нескольких кадров общую панель:
Остался заключительный блок для проверки последних активностей всех клиентов. Эти операции особенно важны в системах безопасности, чтобы при отключении клиента вы не наблюдали неизменный последний кадр.
Запускаем стриминг видео с камер
Теперь, когда мы реализовали и клиент, и сервер, проверим их. Загрузим клиент на каждую плату Raspberry Pi с помощью SCP-протокола:
Проверьте, что на всех машинах установлены импортируемые клиентом или сервером библиотеки. Первым нужно запускать сервер. Сделать это можно следующей командой:
Далее запускаем клиенты, следуя инструкции (будьте внимательны, в вашей системе имена и адреса могут отличаться):
- Откройте SSH-соединение с клиентом: ssh pi@192.168.1.10
- Запустите экран клиента: screen
- Перейдите к профилю: source
/.profile
Ниже представлено демо-видео панели с процессом стриминга и распознавания объектов с четырех камер на Raspberry Pi.
Аналогичные решения из кластера камер и сервера можно использовать и для других задач, например:
- Распознавание лиц. Такую систему можно использовать в школах для обеспечения безопасности и автоматической оценки посещаемости.
- Робототехника. Объединяя несколько камер и компьютерное зрение, вы можете создать прототип системы автопилота.
- Научные исследования. Кластер из множества камер позволяет проводить исследования миграции птиц и животных. При этом можно автоматически обрабатывать фотографии и видео только в случае детектирования конкретного вида, а не просматривать видеопоток целиком.
Источник статьи: http://proglib.io/p/pishem-programmu-dlya-avtomaticheskogo-raspoznavaniya-obektov-s-veb-kamer-2019-10-05
Веб-камера, Node.js и OpenCV: делаем систему распознавания лиц
Компьютерное зрение — это, в двух словах, набор технологий, в основу которых положены принципы человеческого зрения, которые позволяют компьютеру видеть и понимать то, что он видит. На первый взгляд вроде бы просто, но на самом деле это далеко не так.

Если вы хотите осознать важность компьютерного зрения и узнать об областях его применения, посмотрите это видео.
Как говорится: «лучше один раз увидеть», в данном случае — увидеть, как Amazon использует эту технологию для создания торговых центров нового поколения. Потрясающе, правда?
Если вы хотите приобщиться к технологиям компьютерного зрения — предлагаю поговорить о том, как создать интерактивную систему распознавания лиц с использованием обычной веб-камеры, Node.js и OpenCV.
Об изучении компьютерного зрения
Пожалуй, невозможно дать полное описание технологий компьютерного зрения в одном материале или даже в целой серии статей. Поэтому рассмотрим сейчас только самые важные вещи, которые позволят нам приступить к разработке.
Конечно, вы можете расширить свои знания в этой области и самостоятельно, например, записавшись на соответствующие курсы, скажем, на EDX.
Существует организация, которая называется OpenCV, работающая в области компьютерного зрения. Она занимается разработкой одноимённой библиотеки с открытым исходным кодом. Эта библиотека поддерживает C, C++ и Java. Официального модуля для Node.js нет, однако, существует модуль node-opencv , созданный энтузиастами. Мы будем пользоваться этим модулем в следующих разделах материала. А именно, ниже рассмотрим следующие вопросы:
- Установка OpenCV.
- Работа с модулем OpenCV для Node.js.
- Разработка системы интерактивного распознавания лиц.
Установка OpenCV
Для начала надо установить библиотеку OpenCV. Если вы пользуетесь Ubuntu, вам помогут следующие команды. Я их проверил на Ubuntu 16.04.
Итак, начнём с установки зависимостей, необходимых для OpenCV.
Теперь установим саму библиотеку OpenCV.
Установить её можно и иначе, воспользовавшись официальным руководством по установке и приведёнными в нём командами.
Библиотеку можно установить и для Windows.
Если вы работаете на Mac, вы можете либо собрать OpenCV из исходников, либо воспользоваться brew .
Модуль node-opencv
Как уже было сказано, OpenCV официально не предлагает драйвер для Node.js. Однако, в реестре npm имеется модуль node-opencv , работой над которым занимается Питер Брэйден и другие программисты. Модуль этот всё ещё находится в состоянии разработки, он пока не поддерживает все API OpenCV.
Надо отметить, что в настоящий момент последняя сборка с GitHub не объединена с npm-модулем node-opencv , поэтому, устанавливая модуль из npm, вы можете столкнуться с проблемами. Рекомендуется установить модуль непосредственно с GitHub, воспользовавшись следующей командой:
Теперь займёмся программированием.
Разработка интерактивной системы распознавания лиц
Прежде чем мы будем распознавать лица в видеопотоке веб-камеры, разберёмся с выполнением той же операции для обычной фотографии.
Как распознавать лица на фотографиях? OpenCV предоставляет различные классификаторы, которые можно использовать для распознавания лиц, глаз, автомобилей, и многих других объектов. Эти классификаторы, однако, достаточно просты, они не обучены с использованием технологий машинного обучения, поэтому, при распознавании лиц мы можем рассчитывать на точность примерно в 80%.
Вот фото моих друзей с одной из обычных офисных вечеринок.

Напишем программу, которая позволит распознать лица на этом снимке. Вот код (файл face-detector.js ), который читает исходное изображение с диска и выводит новое изображение с отмеченными на нём лицами.
Вот как программа распознала лица на снимке.

Знаю, получилось не очень точно, но начало положено, и это хорошо. Сделаем теперь то же самое, используя видеопоток с веб-камеры. Сначала нужно подключиться к камере и вывести видео. Вот код ( camera.js ), который это делает.
Запустите этот код следующей командой.
Если всё работает как надо, вы увидите окно, в котором будет выводиться то, что снимает видеокамера. В вашем случае картинка будет похожа на ту, что показана ниже, только в кадр попадёт ваше лицо, а не моё.
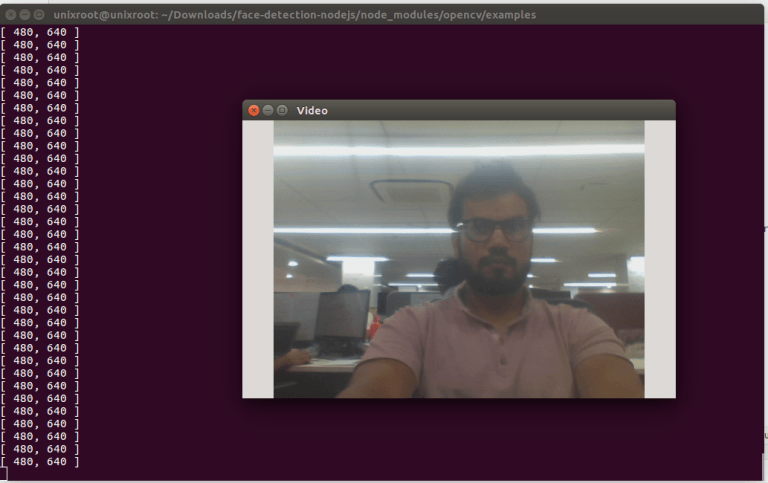
Веб-камера у меня не очень, но, честное слово, в жизни я выгляжу куда лучше. Разберём нашу программу.
Тут мы пытаемся получить доступ к видеопотоку с камеры и создать новое окно для показа видео.
Теперь для того, чтобы показать видео а не статичную картинку, нужно отобразить в окне свежее изображение, полученное с камеры. Делаем мы это, используя функцию setInterval() и обновляя содержимое окна каждые 20 миллисекунд.
Первое изображение имеет размеры 0x0 пикселей, его нам отображать не нужно. Об этом заботится выражение if .
Итак, мы знаем как распознавать лица на фотоснимках и как получить доступ к видеопотоку с веб-камеры. Теперь объединим это всё и наша интерактивная система распознавания лиц будет готова к работе. Вот код (файл camera.js ), который распознаёт лица в видеопотоке.
Опять же, точность распознавания здесь невысока, по грубым оценкам — порядка 80%.
Итоги
OpenCV — это потрясающий опенсорсный проект. Его можно использовать бесплатно для разработки приложений, которые могут найти применение, например, в таких областях, как распознавание движений и распознавание лиц. Кроме того, стандартные классификаторы можно обучить для повышения точности распознавания. Надеюсь, OpenCV будет официально поддерживать Node.js, что позволит использовать в этой среде больше возможностей данной замечательной библиотеки. Если вы хотите углубиться в технологии машинного зрения, то, помимо различных учебных курсов, полезно будет почитать эту книгу и взглянуть на материалы с официального сайта OpenCV.
Уважаемые читатели! Применяете ли вы технологии машинного зрения в своих проектах?
Источник статьи: http://habr.com/ru/company/ruvds/blog/335770/