
Как писать компьютерные программы
![]()
сообщество редакторов, исследователей и специалистов
wikiHow работает по принципу вики, а это значит, что многие наши статьи написаны несколькими авторами. При создании этой статьи над ее редактированием и улучшением работали, в том числе анонимно, 12 человек(а).
Количество просмотров этой статьи: 52 777.
По мере того как технология становится все более и более доступной широкой публике, растет и потребность в программистах. Написание компьютерных кодов и программ, оно же кодинг (от английского «сoding») — это навык, который приобретается и совершенствуется на протяжении долгого времени, но даже самый опытный программист когда-то был новичком. Существует большое разнообразие языков программирования, которые великолепно подходят для начинающих программистов, вне зависимости от того, в какой сфере деятельности вы хотите применять ваши навыки (например, JavaScript довольно сложен, так что лучше начать с HTML или CSS). Узнайте, как научиться писать компьютерные программы, прочитав эту статью.



Наш специалист делится своей историей:: «Я пришла к написанию кодов, не зная ничего ни о компьютерном дизайне, ни о программировании. Когда я захотела научиться писать программы, я начала с чтения книг по языку и с использования информации из интернета. Сегодня в мире доступно так много ресурсов, что научиться новым навыкам очень легко!»
7 правил написания программ, которые не умрут вместе с вами
Ваши программы – это ваше наследие. Решайте сами, как долго оно будет существовать.
Жизнь заканчивается, но программы не обязательно должны умирать.
После серии моих твитов на тему того, как нужно писать программы, меня попросили раскрыть эту тему. Предупреждаю, что редко в каком проекте удаётся чётко следовать всем семи правилам. У меня самого это часто не получается. Но чем больше правил вы соблюдаете, тем больше ваши программы проживут. Каждый символ добавляет что-то к общей экосистеме, и наша задача, как инженеров, поддерживать экосистему в чистоте и порядке.
Что можно получить, выдавая хороший код? Разве не имеет права на жизнь подход в обучении под названием «двигайся быстрее, ломая всё на своём пути?» Нет. Обучиться писать код – это навык, это доступно каждому. Обучиться писать хороший код – это искусство. Это требует усилий, времени и целеустремлённости.
Разве вы хотите оставить после своей смерти миру ещё больше SEGFAULT-ов? Хотите ли вы, чтобы сисадмины занимались починкой систем, которые сломались из-за вашего дерьмового кода? Чтобы ваш менеджер проектов вспоминал вас как инженера, работа которого бесила пользователей?
Ничего плохого в быстром продвижении вперёд нет, но в какой-то момент нужно осознать, что низкокачественный код далеко вас не уведёт.
Когда вы приходите к врачу, тот сначала задаёт вам много вопросов, чтобы понять, что с вами случилось. Он не выписывает лекарства перед постановкой диагноза. Точно так же важно разобраться, действительно ли с вашим кодом что-то не так.
1. Накат обновлений отнимает много времени и сил?
2. Система рушится даже от небольшого обновления?
3. Выкатывали ли вы когда-нибудь сломанный код на продакшн, причём это становилось известно только после жалоб пользователей?
4. Знаете ли вы, что именно нужно делать, когда система падает? Как добраться до бэкапов и восстановиться из них?
5. Проводите ли вы больше времени за сменой окружений, повторных выполнений одних и тех же команд, запуска каких-то утилит – чем за самим написанием программ?
Если вы ответили «да» – эта статья для вас. Читайте, а лучше прочтите два раза.
1. Делите на модули
Мозг человека – сложное устройство, сложнее любого процессора, при этом он не справляется с решением сложных задач. Допустим, сложно сразу умножить 13*35. Но если разделить эти операции на простые: 35*10 + 30*3 + 5*3 = 455, то подсчёт упрощается. Разбивая задачу на простые и независимые, мы приходим к ответу.
Так же и с программами. Разбейте программу на несколько частей, файлов, директорий. проектов. Все зависимости выведите в одно место, используйте принцип MVC или его вариант. Такой код и читать проще, и отлаживать легче. В большинстве случаев отладка приведёт вас к нескольким строкам кода, а не к файлу из тысячи строк. Накатывая апдейты одного модуля, вы не сломаете всю остальную систему.
2. Тестируйте
Такая реакция естественна, потому что нас учили, будто тесты не являются частью программирования. Вас учат шаблонам в С++, но не тому, как их тестировать. В этом и проблема. Некоторые считают, что тесты над писать до самой программы.
Мне всё равно, когда вы пишете тесты, если вы их пишете. Не надо геройствовать, начните с простого (print(add(1, 1) == 2)), а затем уже переходите на фреймворк для тестов в вашем языке.
Тогда вы начнёте понимать сложность вашей программы, учиться делить её на модули, части, которые можно тестировать по отдельности. Получается, что используя тесты, вы уже будете выполнять два из семи правил.
3. Непрерывная интеграция
Тесты должны успешно отрабатывать, причём в разных окружениях (например, в разных версиях Python). Также тесты надо проводить после каждого изменения. Вместо того, чтобы делать это вручную из командной строки, удобнее и быстрее создать платформу для непрерывной интеграции.
Непрерывная интеграция (НИ) – это практика разработки, при которой код интегрируется в репозиторий несколько раз в день. Каждый раз проверяется автоматически, что позволяет отслеживать проблемы на ранней стадии.
Для своих проектов я использую TravisCI и Drone.io. Когда я делаю новое дополнение кода, платформа делает билд и выполняет тесты.
4. Автоматизируйте
У больших проектов всегда есть куча мелких вспомогательных задач. Некоторые люди делают текстовики с командами и копируют их оттуда. Но проще освоить скрипты на bash (и/или Python). Вот некоторые задачи, которые необходимо автоматизировать скриптами:
— преобразование README.md в другие форматы
— автоматическое тестирование (включая создание тестовых серверов и данных, удаление временных файлов и т.д.)
— заливка кода на сервер разработки
— размещение программы на продакшене
— автоматическое обновление зависимостей
5. Избыточность
Первое, что вы видите на git-scm.com:
Git – бесплатная распределённая система контроля версий с открытым исходным кодом, предназначенная для работы как с малыми, так и очень большими проектами, с высокой скоростью и эффективностью.
Распределённая. Это ключевое слово. Ущипните себя, если вы хоститесь только на гитхабе. Потому, что это единая точка отказа. Если гитхаб падает, или во время push-операции вы повредили файлы, ваш процесс разработки останавливается.
Залогиньтесь на Bitbucket и выполните следующее в вашем репозитории:
Теперь, когда вы заливаете код, изменения идут как на Github, так и на Bitbucket. Никогда не знаешь, когда что-либо сломается. И всегда полезно иметь бэкапы. Вот, как это работает у меня:
— весь код живёт в директории Codebase в Dropbox. Автоматическая синхронизация.
— почти весь код живёт на Github
— самый важный код живёт на двух частных зеркалах – одно в школе, другое на моём AWS
Я потеряю свой код, только если настанет конец света.
6 Коммиты
Это должно быть вам знакомо. Загляните в историю, и вы увидите что-то вроде:
Исправил? Какую ошибку? В каком модуле?
Многие расценивают систему контроля версий как бэкап, а не как способ хранить историю. История из таких сообщений бесполезна. Допустим, через неделю после этого коммита вы решили что-то вернуть назад, потому что оно привнесло в проект новый баг. Но поскольку описания действия нет, вам нужно просматривать все изменения. Именно для предотвращения этого и создавались системы контроля версий.
Чтоб не напрягаться, просто воспользуйтесь следующей шапргалкой:
— у каждого коммита должен быть смысл. Исправление ошибки, добавление новой функции, удаление существующей?
— только одно изменение на один коммит
— включайте номер проблемы в сообщение о коммите
— включайте описание изменений. Это зависит от правил текущего проекта, но обычно вы упоминаете, что приводило к ошибке, как вы её исправили и как это тестировать
— пишите осмысленное сообщение:
добавил новую форму в заголовок, чтобы было легче собирать ссылки. закрыл #3
удалил всякое, ибо почему бы и нет, хех
7. Планируйте
Даже если вы выполняете все предыдущие правила и чувствуете себя богом программирования, всё равно может случиться всё, что угодно. Имейте план на самый плохой случай. Что, если трафик побьёт рекорды? Откуда вы возьмёте бэкапы, если система упадёт? Кому звонить ночью, если сервер навернётся?
Продумайте, но не перестарайтесь. Автоматизируйте всё, что возможно. Затем задокументируйте всё подробно. Так, чтобы тот, кто получит ваш код, тоже смог следовать плану. Иметь план – не только значит выглядеть умнее, это значит реально быть умнее.

Вот такие правила и определяют хорошую программу. Если вас они не убедили, ответьте мне на два вопроса:
1. Ожидаете ли вы от новичка, присоединившегося к вам, что он поймёт существующий код с лёгкостью?
2. Является ли рефакторинг кода простым и быстрым делом?
Если нет – перечитайте заново. Сохраните, поделитесь с командой.
Эти правила поначалу могут показаться очевидными. Так и есть. Плохой код постоянно создают, и, в конце концов, он умирает. Ваши программы – это ваше наследие. Решайте сами, как долго оно будет существовать.
Источник статьи: http://habr.com/ru/post/250645/
Как спроектировать и написать полноценную программу
«Инструкция создания функционального приложения», часть 1.
«Мне кажется, что понимаю функциональное программирование на базовом уровне, и я даже писал простые программы, но как мне создать полноценное приложение, с реальными данными, с обработкой ошибок и прочим?»
Это очень распространенный вопрос, поэтому я решил, что в этой серии статей опишу инструкцию, охватывающую проектирование, валидацию, обработку ошибок, персистентность, управление зависимостями, организацию кода и так далее.
Сначала, несколько комментариев и предостережений:
- Я буду описывать только один сценарий, а не всё приложение. Надеюсь, будет очевидно как расширить код при необходимости.
- Это намеренно очень простая инструкция без особых ухищрений и продвинутой техники, ориентированная на поточную обработку данных. Но если вы начинающий, я думаю, вам будет полезно иметь последовательность простых шагов, которые вы сможете повторить и получить ожидаемый результат. Я не утверждаю, что это единственный верный способ. Различные сценарии будут требовать различных подходов, и конечно с ростом собственной экспертизы вы можете обнаружить, что эта инструкция слишком простая и ограниченная.
- Чтобы облегчить переход с объектно-ориентированного проектирования, я постараюсь использовать знакомые концепции такие как «шаблоны», «сервисы», «внедрение зависимости» и т.д., а также объяснять как они соотносятся с функциональным подходом.
- Инструкция также намеренно сделана в некоторой степени императивной, т.е. используется явный пошаговый процесс. Я надеюсь, этот подход облегчит переход от ООП к ФП.
- Для простоты (и возможности использовать F# script) я установлю заглушку на всю инфраструктуру и уклонюсь от взаимодействия с UI напрямую.
Обзор
Приступим
Давайте возьмем очень простой пример, а именно обновление некоторой информации о клиенте через веб-сервис.
И так, наши основные требования:
- Пользователь отправляет некоторые данные (идентификатор пользователя, имя и адрес почтового ящика).
- Мы проверяем корректность имени и адреса ящика.
- В базе данных в соответствующей пользовательской записи обновляются имя и адрес почтового ящика.
- Если адрес почтового ящика изменен, отправляем на этот адрес проверочное письмо.
- Выводим пользователю результат операции.
Это обычный сценарий обработки данных. Здесь присутствует определенный запрос, который запускает сценарий, после чего данные из запроса «протекают» через систему, подвергаясь обработке на каждом шаге. Я использую этот сценарий в качестве примера, потому что он распространен в корпоративном ПО.
Вот диаграмма составных частей процесса: 
Но это описание только успешного варианта событий. Реальность никогда не бывает столь простой! Что произойдёт, если идентификатор пользователя не найдется в базе данных, или почтовый адрес будет некорректный, или в базе данных есть ошибка?
Давайте изменим диаграмму и отметим всё, что может пойти не так. 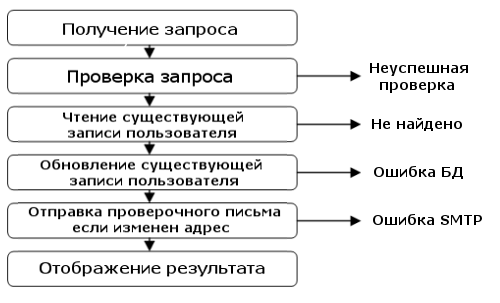
Как видим, на каждом шаге сценария могут возникнуть ошибки по различным причинам. Одна из целей серии этих статей — объяснить как элегантно управлять ошибками.
Функциональное мышление
Теперь, когда мы разобрались с этапами нашего сценария, как его реализовать с помощью функционального подхода?
Сначала обратимся к различиям между исходным сценарием и функциональным мышлением.
В сценарии мы обычно подразумеваем модель запрос-ответ. Отправляется запрос, обратно приходит ответ. Если что-то пошло не так, то поток действий завершается и ответ приходит «досрочно» (прим. переводчика: Речь исключительно о процессе, не о затраченном времени.).
Что я имею ввиду, можно увидеть на диаграмме упрощенной версии сценария. 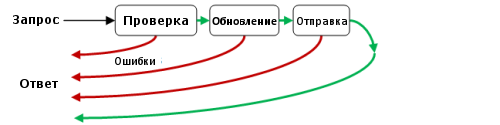
Но в функциональной модели, функция — это черный ящик с входом и выходом, как здесь: 
Как мы можем приспособить наш сценарий к такой модели?
Однонаправленный поток
Во-первых, вы должны осознать, что функциональный поток данных распространяется только вперед. Вы не можете вернуться «досрочно».
В нашем случае, это означает, что все ошибки должны передаваться до окончания сценария по альтернативному пути. 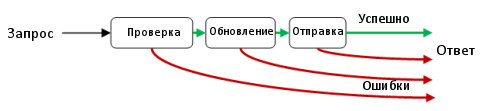
Как только мы это сделаем, у нас появится возможность превратить весь поток в единственную функцию — чёрный ящик: 
Конечно, если вы загляните внутрь этой большой функции, то обнаружите, что она сделана из («является композицией» в терминах функциональной методологии) меньших функций, по одной на каждый этап сценария, соединенных последовательно друг за другом. 
Управление ошибками
На последней диаграмме изображены один успешный выход и три выхода для ошибок. Это проблема, так как функции могут иметь только один выход, а не четыре!
Что мы можем с этим сделать?
Ответ в том, чтобы использовать тип Объединение, где каждый вариант представляет один из возможных выходов. Тогда у функции действительно будет только один выход.
Вот пример возможного определения типа для вывода результата:
И вот переделанная диаграмма, на которой изображён единственный выход с четырьмя различными вариантами, включёнными в него: 
Упрощение управления ошибками
Это решает проблему, но наличие ошибки для каждого шага — это хрупкая и мало пригодная для повторного использования конструкция. Можем ли мы сделать лучше?
Да! Нам в действительности нужны только два метода. Один для успешного случая и другой для всех ошибочных:

Этот тип очень универсальный и будет работать с любым процессом! Собственно вы скоро увидите, что для работы с этим типом мы можем сделать хорошую библиотеку полезных функций, которая подойдет для любых сценариев.
Ещё один момент — в результате, который возвращает функция, совсем нет данных, только статус успех/неудача. Нам потребуется кое-что поправить, чтобы результат функции содержал фактический успешный или сбойный объект. Мы объявим успешный и сбойный типы как универсальные (с помощью параметров типов).
Наконец, наша итоговая, универсальная версия:
На самом деле, в библиотеке F# уже есть подобный тип. Он называется Choice. Для ясности я всё же продолжу использовать в этой и последующих статьях созданный ранее тип Result. Мы вернемся к этому вопросу, когда подойдём к более серьезным задачам.
Теперь, снова взглянув на сценарий с отдельными шагами, мы увидим, что должны соединить ошибки каждого шага в единый «сбойный» путь. 
Как это сделать — тема следующей статьи.
Итог и методические указания
Итак, у нас есть следующие положения к инструкции:
Методические указания
- Каждый сценарий равносилен элементарной функции.
- Возвращаемый тип сценарной функции — объединение с двумя вариантами: Success и Failure.
- Сценарная функция строится из ряда небольших функций, которые представляют отдельные шаги в потоке данных.
- Ошибки всех этапов объединяются в единый путь ошибок.
Источник статьи: http://habr.com/ru/post/263035/