
Учимся писать парсер сайта своими руками
Сегодня я приведу вам в пример, который возможно понадобиться начинающим парсерам и возможно вы найдете в нем ценную информацию. В комментариях очень хотелось бы увидеть возможные изменения для упрощения задачи, так что всегда рад услышать ваши мнения.
Передо мной стояла задача заполнить интернет магазин товарами в количестве свыше 50 тыс наименований. Оригиналы товаров лежали на сайтах поставщиков.
Особо заморачиваться с кодом и решением я не стал, поэтому сделал все максимально просто и быстро.
Прикрепленные файлы буду выкладывать на проекте моих друзей и партнеров 2file.ru Будьте уверены что все ссылки всегда будут действующими и вы всегда сможете скачать любой файл из данной инструкции. +размер файлов не ограничен, нет времени ожидания и нет рекламмы.
Первым делом я решил скачать полностью сайт себе чтобы в дальнейшем было проще работать с ним.
Для Windows нам потребуется программа wget (КАЧАЕМ)
Распаковываем например на диск С и для удобства переименовываем в wget.
Далее нажимаем пуск-выполнить-cmd и там вводим CD C:\wget\. Далее нам нужно запустить команду wget.exe -c -p -r -l0 -np -N -k -nv АДРЕС САЙТА 2>wget.log. Описание команд -c -p -r -l0 -np -N -k -nv можно подробно почитать ТУТ. Нажимаем enter и начинается скачивание. В папке wget появляется папка с названием сайта, куда сливается сайт. ВНИМАНИЕ, при больших объемах, сайт может скачиваться даже несколько дней.
. Прошло несколько дней…
Вот мы и дождались загрузки сайта на наш компьютер. В моем случаи в корне находились страницы с подробным описанием товаров, так что буду следовать отсюда.
Нам понадобится установленный на компьютере сервер apache+php. Для удобства и быстроты настройки можно использовать например xampp, который можно взять бесплатно на ЭТОМ сайте, где так-же приведен процесс инсталяции.
Ок, теперь у нас стоит апач, есть скачанный сайт. Далее для удобства я перенес все скачанные странички в папку xampp для дальнейшей работы с ними. Чтобы не усложнять код, я переименовал все страницы в порядковые номера чтобы получилось 1.html, 2.html… и так далее. Сделать это очень просто. Например через total commender в меню файлы-групповое переименование. Далее в папке с переименованными страницами я создал index.php файл. Теперь начнем разбираться в коде:
(.+?.) #is’, $html, $matches );
foreach ( $matches[1] as $value ) echo $value.’<br>’;
?>
Первой строчкой я указываю на открытие 132.html, в котором будет осуществляться выборка данных.
Открыв любую скачанную страницу, мы видим что интересующая нас информация находится между тегами.
Один из моих примеров это
preg_match_all( ‘#(.+?.)#is’, $html, $matches );
Далее осуществляется вывод полученных данных на экран и спуск на строчку вниз br.
Для выдирания нескольких результатов из одной страницы, можно использовать код на подобии:
(.+?.) #is’, $html, $matches );
preg_match_all( ‘# (.+?.) #is’, $html, $matches1 );
preg_match_all( ‘# (.+?.) #is’, $html, $matches2 );
foreach ( $matches[1] as $value ) echo $value.’ ‘;
foreach ( $matches1[1] as $value ) echo $value.’ ‘;
foreach ( $matches2[1] as $value ) echo $value.’<br>’;
?>
Должно получится что-то вроде (значение1, значение2, значение3 <br>)
Теперь немного дополним наш код чтобы прогнать все наши скачанные страницы. Решил сделать с помощью цикла и получилось что-то вроде этого:
(.+?.) #is’, $html, $matches );
preg_match_all( ‘# (.+?.) #is’, $html, $matches1 );
preg_match_all( ‘# (.+?.) #is’, $html, $matches2 );
foreach ( $matches[1] as $value ) echo $value.’ ‘;
foreach ( $matches1[1] as $value ) echo $value.’ ‘;
foreach ( $matches2[1] as $value ) echo $value.’<br>’;
Отлично, теперь мы видим что-то вроде этого:
значение#значение#значение
значение#значение#значение
Для удобства дальнейшей работы я использовал #. Теперь копируем все что получилось, загоняем в excel, нажимаем данные-текст по столбцам и ставим # в качестве разделителя столбцов. Отлично, мы получили таблицу с результатами нашего парсинга. УРА
Дальнейшая работа зависит от вашей фантазии и цели. Спасибо за внимания, надеюсь на инвайт.
Данная статья не подлежит комментированию, поскольку её автор ещё не является полноправным участником сообщества. Вы сможете связаться с автором только после того, как он получит приглашение от кого-либо из участников сообщества. До этого момента его username будет скрыт псевдонимом.
Источник статьи: http://habr.com/ru/sandbox/30536/
Пишем парсер новостей на PHP
Долгое время я вынашивал идею написать что-нибудь по теме парсинга контента, и вот решился! Начнём с самого тривиального, а потому, востребованного примера – парсинга новостей в рунете. Мы воспользуемся самым простым способом, который есть в PHP и разберем его максимально подробно. В дальнейшем это позволит нам написать более интересные вещи.
Для чего же ещё нам может понадобиться парсер новостей? И тут, честно говоря, вариантов достаточно, чтобы уделить время этой теме. Вот несколько примеров, которые я могу привести исходя из своего опыта.
Так как я в последние время работаю с интернет-магазинами, то стандартная задача от клиента, который только что зарелизил свой магазин или только собирается это сделать — наполнение каталога актуальными товарами, т.е. изображениями, ценами, описаниями товаров и т.д. Вручную это делать бессмысленно, для этого мы можем использовать сайт близкий по тематике, а необходимый контент оттуда спарсить.
Второй пример будет касаться сегодняшней темы – это парсер новостей. Представьте ситуацию, когда необходимо отслеживать изменения новостей и появление новых на десятке различных сайтов по определённым ключам, и транслировать их своим посетителям. К примеру, такой популярный новостной портал как tjournal использует для этого своих роботов или, проще говоря, скрипты, которые парсят новостные ленты и самое интересное отображают у себя.
Основной принцип написания парсера, а в нашем случае парсера новостей – это получить страницу со стороннего ресурса, вытянуть из нее необходимый контент и обработать его. И вся ирония, заключается в том, что не всегда приходит, то, что мы ожидаем. Как с этим бороться мы рассмотрим в других статьях, а сегодня возьмем идеальный вариант и попробуем спарсить новостную ленту Яндекса на главной странице.

Первое, что мы должны сделать, это проанализировать HTML разметку и посмотреть, где находятся нужные нам новости:

Все записи лежат в двух списках. Первый это видимый, а второй скрытый для эффекта смены. Сама же новость обернута ссылкой:

После того, как мы получим страницу, нам потребуется вытянуть все эти ссылки, у которых мы возьмем текст и значение атрибута href.
Какие же инструменты и библиотеки нам потребуются для этого? Во-первых, сам механизм для получения контента со стороннего ресурса, сегодня я использую для этого функцию file_get_contents(). Во-вторых, библиотека для разбора контента, одна из известных и удобных — phpQuery.
Итак, приступим, в качестве сервера использовать я буду opensever, где создам новый сайт parser.loc, куда через composer установлю библиотеку phpQuery. Делается это довольно просто, открываем консоль (можно воспользоваться консолью нашего сервера):

Перейдем в папку с нашим сайтом:
![]()
Теперь нужно установить phpQuery, найти нужный пакет можно на сайте packagist :

Вернемся в консоль и установим пакет, а следом создадим файл index.php и завершим работу с консолью:

Всё, что нам нужно для работы мы подготовили, теперь приступим к написанию кода и в исполняемый файл подключим библиотеку:
Далее вытянем страницу и сразу отобразим её для проверки:

Самый главный этап мы сделали, осталось спарcить названия новостей и их ссылки, для удобства результат можно поместить в массив:
Работа с DOM деревом phpQuery схожа с jQuery. Поэтому эта библиотека очень хорошо подходит для задачи разбора страницы, конечно можно использовать и другие инструменты, но зачем? Вкратце, что тут происходит: полученную страницу мы передаем методу newDocument(), как итог мы получаем объект документа, с которым далее и работаем. Очень важно в конце всех манипуляций удалить его из памяти! Делается это при помощи метода unloadDocuments(). Вытянуть новости не особо ресурсозатратная операция, но если вы решили спарсить пару сотен страниц и их обработать, то вы ощутите всю необходимость подчищать память. В phpQuery функция pq() соответствует функции из jQuery $(). Поэтому внутри, по аналогии, мы втягиваем все ссылки и сохраняем их в массив. Для визуализации давайте отобразим их на странице:

Вот и всё! Наш парсер новостей на PHP готов. Сегодня мы рассмотрели самый быстрый способ, но для того, чтобы спарсить более сложные страницы file_get_contents() не подойдет, мы можем при желании передать и заголовки при обращении на страницу донора, но если там установлен редирект, нам будет необходимо это отслеживать и следовать за ним. Эта функция больше подходит для работы с различными API. Для написания более универсального парсера можно воспользоваться CURL, где многие вещи сделать удобнее, но об этом мы поговорим в одной из следующих статей.
Источник статьи: http://falbar.ru/article/pishem-parser-novostej-na-php
30+ парсеров для сбора данных с любого сайта

Десктопные/облачные, платные/бесплатные, для SEO, для совместных покупок, для наполнения сайтов, для сбора цен… В обилии парсеров можно утонуть.
Мы разложили все по полочкам и собрали самые толковые инструменты парсинга — чтобы вы могли быстро и просто собрать открытую информацию с любого сайта.
Зачем нужны парсеры
Парсер — это программа, сервис или скрипт, который собирает данные с указанных веб-ресурсов, анализирует их и выдает в нужном формате.
С помощью парсеров можно делать много полезных задач:
- Цены. Актуальная задача для интернет-магазинов. Например, с помощью парсинга вы можете регулярно отслеживать цены конкурентов по тем товарам, которые продаются у вас. Или актуализировать цены на своем сайте в соответствии с ценами поставщика (если у него есть свой сайт).
- Товарные позиции: названия, артикулы, описания, характеристики и фото. Например, если у вашего поставщика есть сайт с каталогом, но нет выгрузки для вашего магазина, вы можете спарсить все нужные позиции, а не добавлять их вручную. Это экономит время.
- Метаданные: SEO-специалисты могут парсить содержимое тегов title, description и другие метаданные.
- Анализ сайта. Так можно быстро находить страницы с ошибкой 404, редиректы, неработающие ссылки и т. д.
Для справки. Есть еще серый парсинг. Сюда относится скачивание контента конкурентов или сайтов целиком. Или сбор контактных данных с агрегаторов и сервисов по типу Яндекс.Карт или 2Гис (для спам-рассылок и звонков). Но мы будем говорить только о белом парсинге, из-за которого у вас не будет проблем.
Где взять парсер под свои задачи
- Оптимальный — если в штате есть программист (а еще лучше — несколько программистов). Поставьте задачу, опишите требования и получите готовый инструмент, заточенный конкретно под ваши задачи. Инструмент можно будет донастраивать и улучшать при необходимости.
- Воспользоваться готовыми облачными парсерами (есть как бесплатные, так и платные сервисы).
- Десктопные парсеры — как правило, программы с мощным функционалом и возможностью гибкой настройки. Но почти все — платные.
- Заказать разработку парсера «под себя» у компаний, специализирующихся на разработке (этот вариант явно не для желающих сэкономить).
Первый вариант подойдет далеко не всем, а последний вариант может оказаться слишком дорогим.
Что касается готовых решений, их достаточно много, и если вы раньше не сталкивались с парсингом, может быть сложно выбрать. Чтобы упростить выбор, мы сделали подборку самых популярных и удобных парсеров.
Законно ли парсить данные?
В законодательстве РФ нет запрета на сбор открытой информации в интернете. Право свободно искать и распространять информацию любым законным способом закреплено в четвертом пункте 29 статьи Конституции.
Допустим, вам нужно спарсить цены с сайта конкурента. Эта информация есть в открытом доступе, вы можете сами зайти на сайт, посмотреть и вручную записать цену каждого товара. А с помощью парсинга вы делаете фактически то же самое, только автоматизированно.
Но если вы хотите собрать персональные данные пользователей и использовать их для email-рассылок или таргетированной рекламы, это уже будет незаконно (эти данные защищены законом о персональных данных).
Десктопные и облачные парсеры
Облачные парсеры
Основное преимущество облачных парсеров — не нужно ничего скачивать и устанавливать на компьютер. Вся работа производится «в облаке», а вы только скачиваете результаты работы алгоритмов. У таких парсеров может быть веб-интерфейс и/или API (полезно, если вы хотите автоматизировать парсинг данных и делать его регулярно).
Например, вот англоязычные облачные парсеры:
Из русскоязычных облачных парсеров можно привести такие:
Любой из сервисов, приведенных выше, можно протестировать в бесплатной версии. Правда, этого достаточно только для того, чтобы оценить базовые возможности и познакомиться с функционалом. В бесплатной версии есть ограничения: либо по объему парсинга данных, либо по времени пользования сервисом.
Десктопные парсеры
Большинство десктопных парсеров разработаны под Windows — на macOS их необходимо запускать с виртуальных машин. Также некоторые парсеры имеют портативные версии — можно запускать с флешки или внешнего накопителя.
Популярные десктопные парсеры:
- ParserOK,
- Datacol,
- Screaming Frog, ComparseR, Netpeak Spider — об этих инструментах чуть позже поговорим подробнее.
Виды парсеров по технологии
Браузерные расширения
Для парсинга данных есть много браузерных расширений, которые собирают нужные данные из исходного кода страниц и позволяют сохранять в удобном формате (например, в XML или XLSX).
Парсеры-расширения — хороший вариант, если вам нужно собирать небольшие объемы данных (с одной или парочки страниц). Вот популярные парсеры для Google Chrome:
Надстройки для Excel
Программное обеспечение в виде надстройки для Microsoft Excel. Например, ParserOK. В подобных парсерах используются макросы — результаты парсинга сразу выгружаются в XLS или CSV.
Google Таблицы
С помощью двух несложных формул и Google Таблицы можно собирать любые данные с сайтов бесплатно.
Функция использует язык запросов XPath и позволяет парсить данные с XML-фидов, HTML-страниц и других источников.
Функция принимает два значения:
- ссылку на страницу или фид, из которого нужно получить данные;
- второе значение — XPath-запрос (специальный запрос, который указывает, какой именно элемент с данными нужно спарсить).
Хорошая новость в том, что вам не обязательно изучать синтаксис XPath-запросов. Чтобы получить XPath-запрос для элемента с данными, нужно открыть инструменты разработчика в браузере, кликнуть правой кнопкой мыши по нужному элементу и выбрать: Копировать → Копировать XPath.

С помощью IMPORTXML можно собирать практически любые данные с html-страниц: заголовки, описания, мета-теги, цены и т.д.
У этой функции меньше возможностей — с ее помощью можно собрать данные из таблиц или списков на странице. Вот пример функции IMPORTHTML:
Она принимает три значения:
- Ссылку на страницу, с которой необходимо собрать данные.
- Параметр элемента, который содержит нужные данные. Если хотите собрать информацию из таблицы, укажите «table». Для парсинга списков — параметр «list».
- Число — порядковый номер элемента в коде страницы.
Об использовании 16 функций Google Таблиц для целей SEO читайте в нашей статье. Здесь все очень подробно расписано, с примерами по каждой функции.
Виды парсеров по сферам применения
Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
- интуитивно понятный интерфейс;
- возможность выгружать отдельные товары, разделы или весь каталог;
- можно выгружать данные в удобном формате. Например, в Облачном парсере доступно большое количество форматов выгрузки, кроме стандартных XLSX и CSV: адаптированный прайс для Tiu.ru, выгрузка для Яндекс.Маркета и т. д.
Популярные парсеры для СП:
Парсеры цен конкурентов
Инструменты для интернет-магазинов, которые хотят регулярно отслеживать цены конкурентов на аналогичные товары. С помощью таких парсеров вы можете указать ссылки на ресурсы конкурентов, сопоставлять их цены с вашими и корректировать при необходимости.
Вот три таких инструмента:
Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Парсеры для SEO-специалистов
Отдельная категория парсеров — узко- или многофункциональные программы, созданные специально под решение задач SEO-специалистов. Такие парсеры предназначены для упрощения комплексного анализа оптимизации сайта. С их помощью можно:
- анализировать содержимое robots.txt и sitemap.xml;
- проверять наличие title и description на страницах сайта, анализировать их длину, собирать заголовки всех уровней (h1-h6);
- проверять коды ответа страниц;
- собирать и визуализировать структуру сайта;
- проверять наличие описаний изображений (атрибут alt);
- анализировать внутреннюю перелинковку и внешние ссылки;
- находить неработающие ссылки;
- и многое другое.
Пройдемся по нескольким популярным парсерам и рассмотрим их основные возможности и функционал.
Парсер метатегов и заголовков PromoPult
Стоимость: первые 500 запросов — бесплатно. Стоимость последующих запросов зависит от количества: до 1000 — 0,04 руб./запрос; от 10000 — 0,01 руб.
Возможности
С помощью парсера метатегов и заголовков можно собирать заголовки h1-h6, а также содержимое тегов title, description и keywords со своего или чужих сайтов.
Инструмент пригодится при оптимизации своего сайта. С его помощью можно обнаружить:
- страницы с пустыми метатегами;
- неинформативные заголовки или заголовки с ошибками;
- дубли метатегов и т.д.
Также парсер полезен при анализе SEO конкурентов. Вы можете проанализировать, под какие ключевые слова конкуренты оптимизируют страницы своих сайтов, что прописывают в title и description, как формируют заголовки.
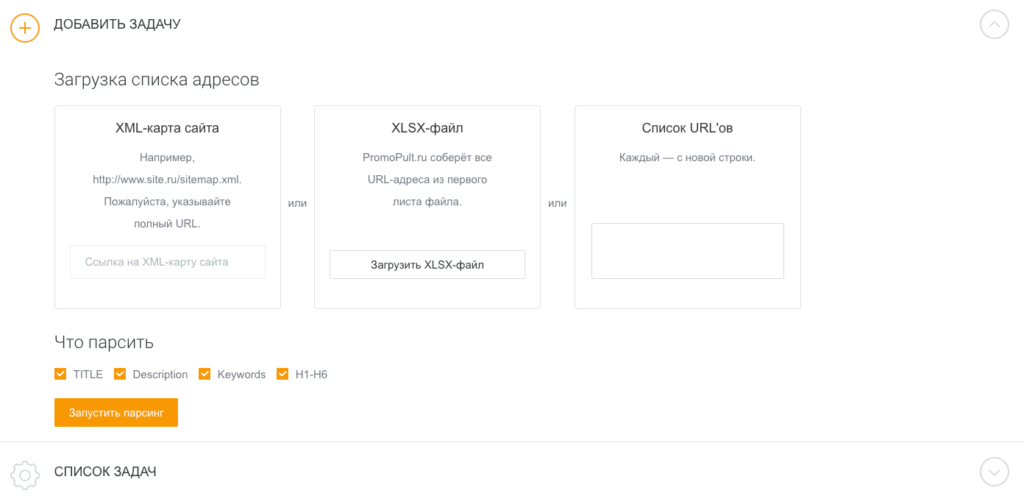
Сервис работает «в облаке». Для начала работы необходимо добавить список URL и указать, какие данные нужно спарсить. URL можно добавить вручную, загрузить XLSX-таблицу со списком адресов страниц, или вставить ссылку на карту сайта (sitemap.xml).
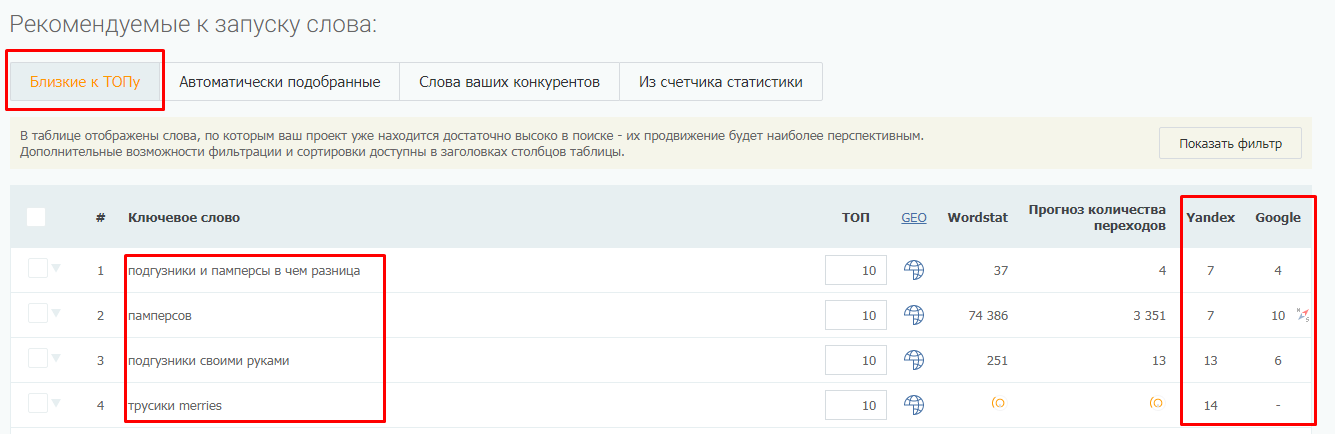
Парсер метатегов и заголовков — не единственный инструмент системы PromoPult для парсинга. В SEO-модуле системы можно бесплатно спарсить ключевые слова, по которым добавленный в систему сайт занимает ТОП-50 в Яндексе/Google.
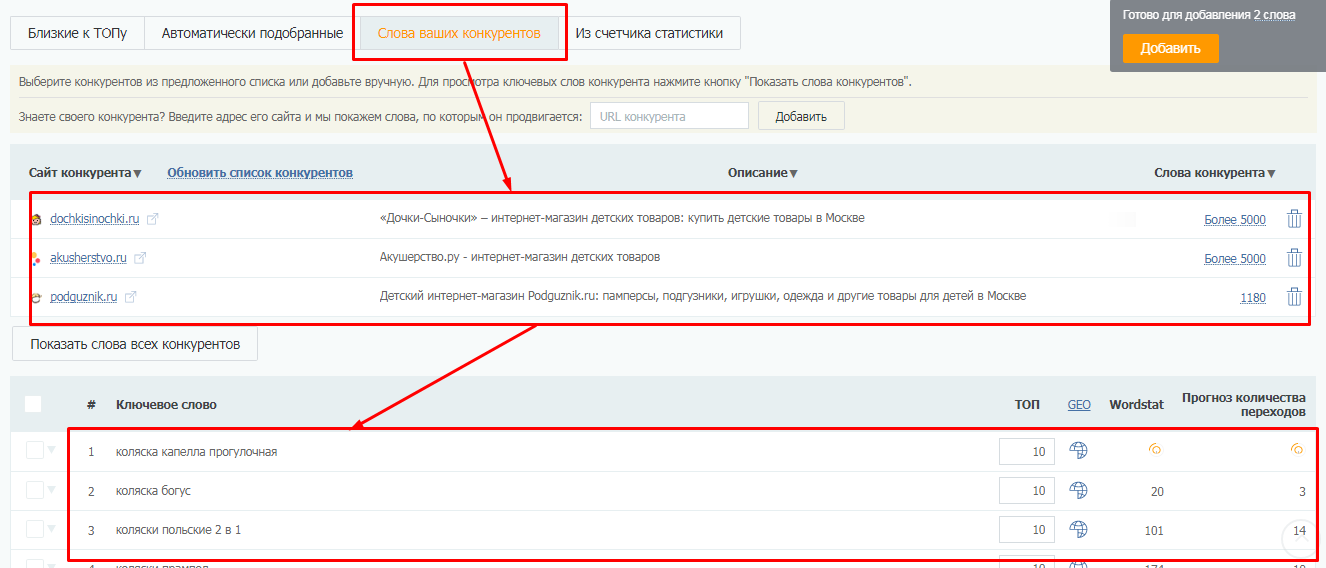
Здесь же на вкладке “Слова ваших конкурентов” вы можете выгрузить ключевые слова конкурентов (до 10 URL за один раз).
Подробно о работе с парсингом ключей в SEO-модуле PromoPult читайте здесь.
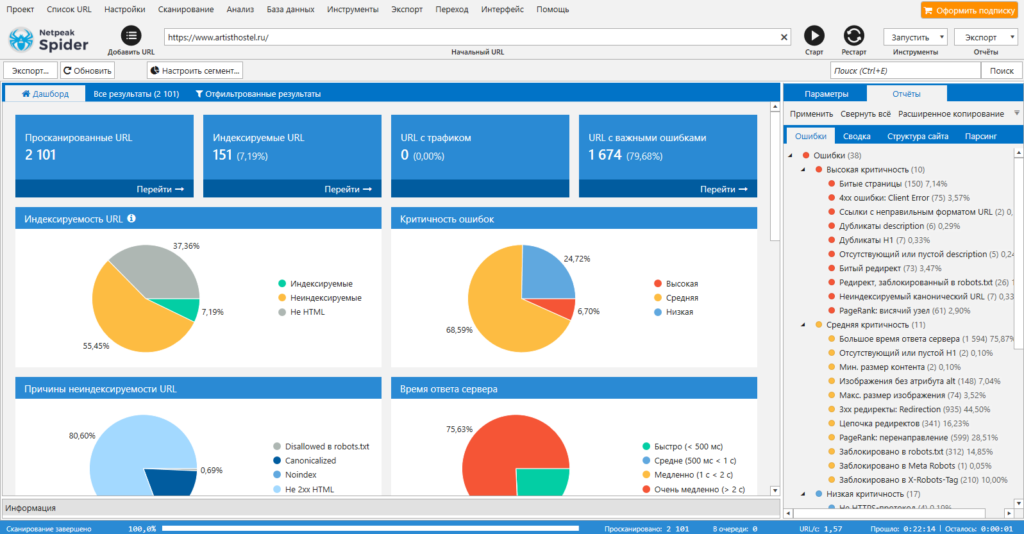
Netpeak Spider
Стоимость: от 19$ в месяц, есть 14-дневный пробный период.
Парсер для комплексного анализа сайтов. С Netpeak Spider можно:
- провести технический аудит сайта (обнаружить битые ссылки, проверить коды ответа страниц, найти дубли и т.д.). Парсер позволяет находить более 80 ключевых ошибок внутренней оптимизации;
- проанализировать основные SEO-параметры (файл robots.txt, проанализировать структуру сайта, проверить редиректы);
- парсить данные с сайтов с помощью регулярных выражений, XPath-запросов и других методов;
- также Netpeak Spider может импортировать данные из Google Аналитики, Яндекс.Метрики и Google Search Console.
Screaming Frog SEO Spider
Стоимость: лицензия на год — 149 фунтов, есть бесплатная версия.
Многофункциональный инструмент для SEO-специалистов, подходит для решения практически любых SEO-задач:
- поиск битых ссылок, ошибок и редиректов;
- анализ мета-тегов страниц;
- поиск дублей страниц;
- генерация файлов sitemap.xml;
- визуализация структуры сайта;
- и многое другое.

В бесплатной версии доступен ограниченный функционал, а также есть лимиты на количество URL для парсинга (можно парсить всего 500 url). В платной версии таких лимитов нет, а также доступно больше возможностей. Например, можно парсить содержимое любых элементов страниц (цены, описания и т.д.).
ComparseR
Стоимость: 2000 рублей за 1 лицензию. Есть демо-версия с ограничениями.
Еще один десктопный парсер. С его помощью можно:
- проанализировать технические ошибки на сайте (ошибки 404, дубли title, внутренние редиректы, закрытые от индексации страницы и т.д.);
- узнать, какие страницы видит поисковой робот при сканировании сайта;
- основная фишка ComparseR — парсинг выдачи Яндекса и Google, позволяет выяснить, какие страницы находятся в индексе, а какие в него не попали.

Анализ сайта от PR-CY
Стоимость: платный сервис, минимальный тариф — 990 рублей в месяц. Есть 7-дневная пробная версия с полным доступом к функционалу.
Онлайн-сервис для SEO-анализа сайтов. Сервис анализирует сайт по подробному списку параметров (70+ пунктов) и формирует отчет, в котором указаны:
- обнаруженные ошибки;
- варианты исправления ошибок;
- SEO-чеклист и советы по улучшению оптимизации сайта.
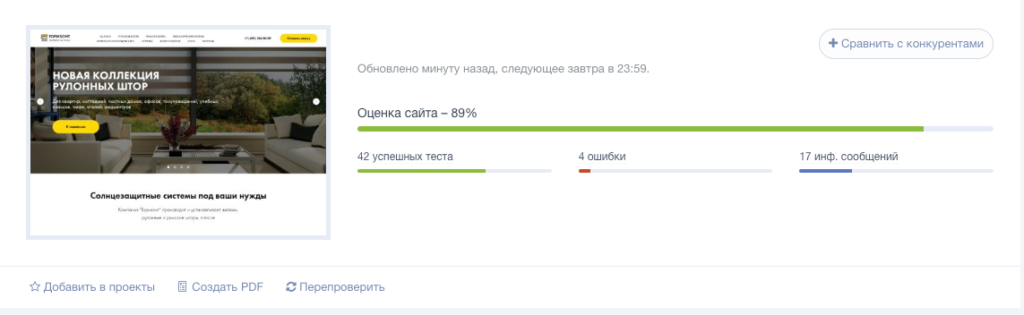
Анализ сайта от SE Ranking
Стоимость: платный облачный сервис. Доступно две модели оплаты: ежемесячная подписка или оплата за проверку.
Стоимость минимального тарифа — 7$ в месяц (при оплате годовой подписки).
Возможности:
- сканирование всех страниц сайта;
- анализ технических ошибок (настройки редиректов, корректность тегов canonical и hreflang, проверка дублей и т.д.);
- поиск страниц без мета-тегов title и description, определение страниц со слишком длинными тегами;
- проверка скорости загрузки страниц;
- анализ изображений (поиск неработающих картинок, проверка наличия заполненных атрибутов alt, поиск «тяжелых» изображений, которые замедляют загрузку страниц);
- анализ внутренних ссылок.

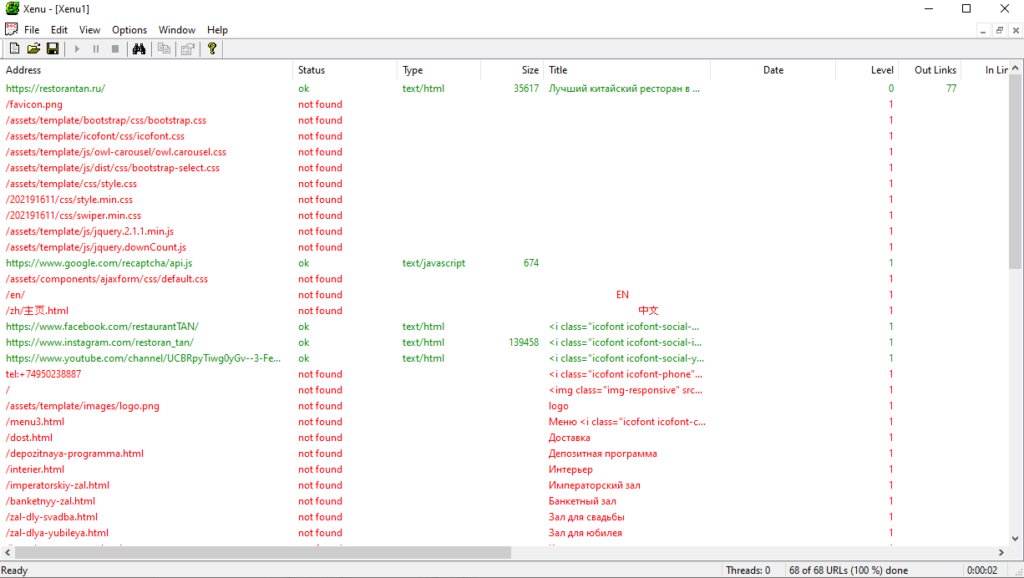
Xenu’s Link Sleuth
Стоимость: бесплатно.
Десктопный парсер для Windows. Используется для парсинга все url, которые есть на сайте:
- ссылки на внешние ресурсы;
- внутренние ссылки (перелинковка);
- ссылки на изображения, скрипты и другие внутренние ресурсы.
Часто применяется для поиска неработающих ссылок на сайте.
A-Parser
Стоимость: платная программа с пожизненной лицензией. Минимальный тарифный план — 119$, максимальный — 279$. Есть демо-версия.
Многофункциональный SEO-комбайн, объединяющий 70+ разных парсеров, заточенных под различные задачи:
- парсинг ключевых слов;
- парсинг данных с Яндекс и Google карт;
- мониторинг позиций сайтов в поисковых системах;
- парсинг контента (текст, изображения, видео) и т.д.
Кроме набора готовых инструментов, можно создать собственный парсер с помощью регулярных выражений, языка запросов XPath или Javascript. Есть доступ по API.

Чек-лист по выбору парсера
Краткий чек-лист, который поможет выбрать наиболее подходящий инструмент или сервис.
- Четко определите, для каких задач вам нужен парсер: анализ SEO конкурентов или мониторинг цен, сбор данных для наполнения каталога, съем позиций и т.д.
- Определите, какой объем данных и в каком виде нужно получать.
- Определите, как часто вам нужно собирать данные: единоразово или с определенной периодичностью (раз в день/неделю/месяц).
- Выберите несколько инструментов, которые подходят для решения ваших задач. Попробуйте демо-версии. Узнайте, предоставляется ли техническая поддержка (желательно даже протестировать ее — задать парочку вопросов и посмотреть, как быстро вы получите ответ и насколько он будет исчерпывающим).
- Выберите наиболее подходящий сервис по соотношению цена/качество.
Для крупных проектов, где требуется парсить большие объемы данных и производить сложную обработку, более выгодной может оказаться разработка собственного парсера под конкретные задачи.
Для большинства же проектов достаточно будет стандартных решений (возможно, вам может быть достаточно бесплатной версии любого из парсеров или пробного периода).
Источник статьи: http://habr.com/ru/company/click/blog/494020/