
Четыре метода загрузки изображений с веб-сайта с помощью Python
Недавно пришлось по работе написать простенький парсер на питоне, который бы скачивал с сайта изображения (по идее тот же самый парсер может качать не только изображения, но и файлы других форматов) и сохранял их на диске. Всего я нашел в интернете четыре метода. В этой статье я их решил собрать все вместе.
1-ый метод
Первый метод использует модуль urllib (или же urllib2). Пусть имеется ссылка на некое изображение img. Метод выглядит следующим образом:
Здесь нужно обратить внимание, что режим записи для изображений — ‘wb’ (бинарный), а не просто ‘w’.
2-ой метод
Второй метод использует тот же самый urllib. В дальнейшем будет показано, что этот метод чуть медленнее первого (отрицательный оттенок фактора скорости парсинга неоднозначен), но достоин внимания из-за своей краткости:
Притом стоит заметить, что функция urlretrieve в библиотеке urllib2 по неизвестным мне причинам (может кто подскажет по каким) отсутствует.
3-ий метод
Третий метод использует модуль requests. Метод имеет одинаковый порядок скорости выгрузки картинок с первыми двумя методами:
При этом при работе с веб в питоне рекомендуется использовать именно requests вместо семейств urllib и httplib из-за его краткости и удобства обращения с ним.
4-ый метод
Четвертый метод по скорости кардинально отличается от предыдущих методов (на целый порядок). Основан на использовании модуля httplib2. Выглядит следующим образом:
Здесь явно используется кэширование. Без кэширования (h = httplib2.Http()) метод работает в 6-9 раза медленнее предыдущих аналогов.
Тестирование скорости проводилось на примере скачивания картинок с расширением *.jpg c сайта новостной ленты lenta.ru. Выбор картинок, подпадающих под этот критерий и измерение времени выполнения программы производились следующим образом:
Постоянно меняющиеся картинки на сайте не повлияли на чистоту измерений, поскольку методы отрабатывали друг за другом. Полученные результаты таковы:
| Метод 1, с | Метод 2, с | Метод 3, с | Метод 4, с (без кэширования, с) |
|---|---|---|---|
| 0.823 | 0.908 | 0.874 | 0.089 (7.625) |
Данные представлены как результат усреднения результатов семи измерений.
Просьба к тем, кто имел дело с библиотекой Grab (и с другими), написать в комментариях аналогичный метод по скачиванию изображений с помощью этой и других библиотек.
Редакторский дайджест
Присылаем лучшие статьи раз в месяц
Скоро на этот адрес придет письмо. Подтвердите подписку, если всё в силе.

Похожие публикации
Алгоритм подавления полос на изображении как инструмент улучшения качества томографической реконструкции
Загрузка и обработка изображений в .NET Core
Монитор объемного изображения
Заказы
AdBlock похитил этот баннер, но баннеры не зубы — отрастут
Комментарии 18




Я около полугода назад начал использовать python для аналогичных целей — массового парсинга страниц, поэтому мне тоже было интересно, какой способ работает быстрее. Для этого я набросал небольшой тест: pastebin.com/mH2ASEGX. Скрипт в 100 итераций получает главную страницу vk.com и ищет на ней наличие паттерна — типичные действия при парсинге. Резульаты следующие:
Из выводов: видно, что urllib-функции и httplib работают приблизительно в два раза медленнее, чем популярная библиотека Requests. Это вызвано тем, что urllib* не поддерживают keep-alive и на каждый запрос открывают-закрывают новый сокет (в третьей версии питона это исправили). Нужно скзаать, что с httplib кипэлайвы использовать, в принципе, можно, но контролировать их нужно вручную, через хедеры, тогда скорость работы будет приблизительно в 2 раза выше. Pycurl по скорости тоже ничем не отличается от других высокоуровневых библиотек, не знаю, правда, поддерживает ли он keep-alive.
Ну а сокеты, как самый низкоуровневый доступ к сети, рвут все библиотеки с огромным отрывом.
Поэтому если стоит вопрос максимальной производительности и нет сложных http-запросов, то лучше все оформить в виде какой-нибудь своей обертки над сокетами.
Источник статьи: http://habr.com/ru/post/210238/
Парсер картинок с сайта
Хочу написать парсер картинок с сайта (любого),
но не знаю с чего начать., так как в python куча библиотек : не пойму что читать и с какой стороны подойти.
Подскажите, для понимания того, как решить эту задачу, что лучше всего будет прочитать\посмотреть?
Вооружился этими книгами:
— Бизли — Python. Подробный справочник
— Майкл Доусон — Программируем на Python — 2014
— Саммерфилд — Программирование на Python 3
Но для обработки информации в интернете информация есть только у Бизли, и то сухо очень.
Проблемный парсер сайта
Пмогите плизз, давно уже ломаю голову, хотел написать парсер сайта, чтобы выводил все, что.
Парсер сайта и ссылок с сайта
Добрый день. Подскажите, как реализовать парсер сайта, с которого парсятся все URL и в свою.
Парсер сайта
Здравствуйте, нужна помощь с парсером. Нужно спарсить https://bittrex.com/home/markets, допустим.
Парсер закрытого сайта
Нужна помощь с кодом! # coding: utf-8 import requests from bs4 import BeautifulSoup from.
1. Как в нужном языке делать http запросы и получать ответ
2. html, как в нем хранятся картинки и как и какие атрибуты задаются картинкам
3. О том как разбирается (парсится) html. Сразу оговорюсь, регулярки в этом деле очень плохой вариант. Их нужно использовать с понимаем дела и только там где это действительно нужно.
В python я бы запрашивал страницу сайта с помощью requests, парсил html с помощью lxml.html, а загружал картинки с помощью urllib.request.urlretrieve
Посмотрите на youtube видюшки по теме, там правда на английском, но все же.
Для парсинга неплохо было бы подучить XPath, для ваших целей хватит и часочка.
Для хрома есть пара отличных расширений, которые определяют XPath для элементов страницы (как абсолютный адрес, так и относительный). Их потом можно вставить в тело кода.
В общем-то правильно до меня сказали про requests (сам использую), urllib, beautifulsoup. Регулярку я бы советовал все же изучать по Mastering Python Regular Expressions от Packt Publishing — книжка компактная и хорошо читается. По Фридлю учиться — слишком толсто, я бы сказал, но можно, если есть время.
Азы Питона по Замерфельду — перебор конечно. Достаточно Интро из питон.докс почитать.
https://wiki.python.org/moin/IntroductoryBooks
Посмотрите по ссылке выше.
Python for Software Design: How to Think Like a Computer Scientist by Allen B. Downey, Olin College of Engineering, Massachusetts — Вот про эту книгу я говорю. Она начального уровня. Если до этого мало кодили вообще на любых языках — то в самый раз. Еще читал книжку от MIT (посмотрите на их сайте ocw.mit.edu).
ПС Все тех. книги я читаю только на английском и только на английском. На русском обычно можно найти косные неинтересные переводы.
Мой английский пока не позволяет читать техническую литературу, к сожалению,. но спасибо
Добавлено через 13 часов 22 минуты
Слушайте,
Я подключил urllib и BeautifulSoup.
Создал объект библиотеки urllib: понял, что он нужен, потому что содержит в себе код страницы.
Затем BeautifulSoup’ом мы парсим объект urllib : ищем картинки.
И По этим ссылкам затем скачиваем файлы с помощью той же urllib.
Есть пара моментов :
— как перемещаться между страницами? переходить с одной на другую?
или об этом есть в библиотеке urllib?
— файлы скачивать в цикле? Я в принципе понял , что если бы пользовался регулярными выражениями, то я бы в цикле просто прошёлся по всему «коду» — собирал нужные адреса и сразу их качал,.
но парсером пока не понял как это делается.
— думаю, что позже дойду до этого сам, но спрошу заранее: как можно проверять заранее размер файлов, которые собираюсь скачивать? ну, чтобы не качать мелочь, к примеру
Источник статьи: http://www.cyberforum.ru/python/thread1355511.html
Парсинг фотографий с сайта cian.ru с помощью Selenium
Здравствуйте дорогие хабровчане, в этом небольшом примере я хочу показать как можно распарсить страницу, данные на которую подгружаются с помощью javascript виджетов. Более того, даже если страницу в этом примере просто сохранить, то всё равно не получится спарсить из неё все нужные фотографии из-за этих виджетов. В данном случае я использую для примера сайт cian.ru, у которого есть свой api, который я использовать не буду, вместо этого я буду использовать Selenium. Я не работаю в cian.ru, просто использую этот сайт для примера. Код в парсере простой и расчитан на начинающих.
Небольшое вступление — когда на досуге я рассматривал примеры ремонтов в cian.ru, я подумал, что не плохо было бы сохранить понравившиеся мне фотографии, но вручную сохранять их было бы долго, к тому же это не наш метод, так я и решил написать этот парсер.
Парсер написан на языке python3 из дистрибутива Anaconda, Selenium и chromedriver binary я установил отдельно именно из этих ссылок. (Ну и конечно же в системе должен быть установлен барузер Google Chrome)
Ниже представлен полный код парсера, далее я разберу основные моменты отдельно.
Первым делом я загрузил страницу https://www.cian.ru/sale/flat/222059642/ с понравившимися мне фотографиями. Для этого я создал объект driver браузера и передал ему ссылку через метод get . Обратите внимание, что я использую Headless Chrome, т.е. передаю в webdriver.Chrome() параметры опций браузера с аргументом —headless , благодаря этому браузер не будет реально отрисовывать содержимое страницы, если вы захотите посмотреть на отрисовку, то не передавайте аргументы chrome_options и тогода вы сможете увидеть, что происходит на самом деле.
Далее в цикле я начал парсить фотографии, логика парсера работет также, как если бы я сам скачивал их вручную, т.е. сохраняю текущую фотографию и нажимаю на стрелку «next».
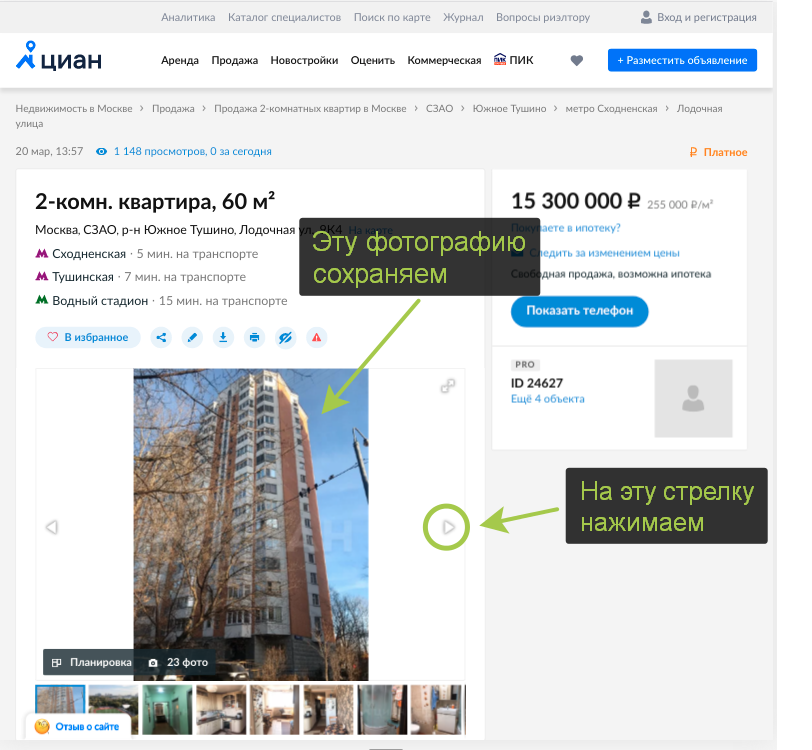
Код ниже сохраняет в переменную url ссылку на фотографию, блок try/except отслеживает ошибку NoSuchElementException , эта ошибка возникает, когда все фотографии скачаны и Selenium больше не находит ссылку.
Слудующий блок кода буквально кликает по стрелке для перехода к следующей фотографии.
Далее сохраняем фотографию по ссылке на диск через библиотеку urllib .
И в конце простой но важный код, задержка позволяет полностью подгрузиться странтице после клика по стрелке. (здесь можно сделать код почище организовав задержку средствами Selenium)
Вот такой пример парсера фоторграфий на Selenium, не утверждаю, что это лучший подход, если кто-то знает как сделать лучше напишите свои идеи в комментах.
Источник статьи: http://habr.com/ru/post/494544/
Пишем простой парсер файлов (для начинающих)
В этой статье я хотел бы рассказать как написать простой парсер на примере сайтов aimp.ru и geekbrains.ru. Статья предназначена строго для тех, кто уже имеет базовые знания о языке программирования C# и уже написал свой первый «Hello world».
Мне всегда нравился аудиоплеер Aimp (нет, это не реклама), но встроенных скинов у него слишком мало, а заходить на сайт, смотреть скины, скачивать и пробовать как они будут смотреться на деле не было никакого желания. Поэтому я решил написать парсер скинов с данного сайта. Немного посмотрев сайт, я заметил, что скины там хранятся последовательно с присвоенным id. Т.к. до недавнего времени я знал только 1С и немного командную строку, то недолго думая я решил написать его в командной строке. Но при тестировании обнаружил, что если скачивать большое количество файлов, то во-первых часть может просто не скачаться, а во-вторых может произойти переполнение оперативной памяти. В итоге я тогда бросил эту затею.
Не так давно начав изучать C# я решил вернуться к этой идее, дабы попрактиковаться немного. Что из этого получилось читайте под катом.
Для разработки нам понадобится только среда разработки, я использовал Visual Studio, вы можете использовать любую другую на ваш вкус.
Я не буду углубляться в базовые понятия C#, для этого написано множество различных книг и отснято бесчисленное количество роликов.
Для начала запустим Visual Studio и создадим консольное приложение (т.к. мне лень делать формы нам не нужен интерфейс). Среда разработки нам сама подготовит шаблон проекта. У нас получится что-то вроде этого:
Удаляем директивы которыми мы пользоваться сейчас не будем:
И добавляем те директивы, которыми будем пользоваться:
После чего в методе Main объявляем переменную:
Парсим Aimp скины
Далее мы пишем саму функцию:
Все скины скачиваются в директорию, заданную в настройках браузера. Конструкции try/catch нам нужны для того, чтобы программа не «вываливалась» из-за ошибок. Хотя можно было обойтись и без них.
Вы могли заметить функцию GetNameOfSkin. Она нужна для того, чтобы получить название скина, который мы скачиваем. Можно обойтись и без неё, она нужна только для красоты, но раз мы только учимся, то напишем и её:
Далее в методе Main нужно вызвать скачивание на выполнение:
Парсим сертификаты Geekbrains
Сертификаты на сайте хранятся в открытом виде, и открыв их через сайт, как скины aimp мы сможем их скачать только вручную нажав кнопку скачать. Но это не дело, мы же программисты.
Тут нам на помощь приходит класс WebClient, а именно его метод DownloadFile. Ему мы просто передаем путь для скачивания и путь для сохранения и он все делает за нас. Звучит легко, попробуем сделать:
И после чего точно также вызываем эту функцию из метода Main.
Вообще обе эти функции ещё есть куда дорабатывать, но я думаю для ознакомления и самых базовых функций парсинга они вполне подойдут. Кому лень все это собирать в один проект — вот ссылка на GitHub.
Спасибо за внимание и надеюсь, кому-нибудь это поможет.
Источник статьи: http://habr.com/ru/post/282119/
Парсер картинок с сайта
Рассмотрим детали работы парсера фото или картинок с сайта. Фото будут скачиваться и сохраняться на ваш компьютер или сервер, на котором запускается PHP скрипт парсера. Скачивать будем картинки из карточки товара интернет-магазина gearbest.com.
Для начала нужно собрать URL фото товаров из HTML кода карточки товара.

Для этого можно применить простой парсер HTML, который рассматривался в первой статье цикла.
После получения списка ссылок на фото товара мы скачиваем сами картинки с помощью той же функции получения данных от сервера на основе cURL. Можно было бы даже воспользоваться стандартной функцией PHP file_get_contents(). Но в нашей функции curl_get_contents() реализована возможность повторной попытки скачать файл и пауза между запросами к серверу. Это бывает полезно, когда попадаются сайты с защитой от множественных загрузок или просто слабые сервера, которые не выдерживают повышенные нагрузки.

Парсер фото товара с сайта
В результате получаем простой парсер фото товаров с сайта на примере gearbest.com. Код парсера размещён в одном файле, часть возможных ошибок не обрабатывается для краткости кода.
Рассмотрим основные особенности. Парсер собирает фото с одной карточки товара. Но нам ничего не мешает при необходимости добавить ещё один цикл и спарсить картинки по списку страниц.
Обратите внимание на функцию preg_match_all(), она возвращает массив соответствий регулярному выражению. В этом её основное отличие от функции preg_match(), которая работает до первого совпадения.
С помощью встроенной в PHP функции file_put_contents() можно сохранить фото на свой сервер по нужному пути. Соответственно предварительно мы проверяем наличие нужного нам каталога и при его отсутствии создаём его.
Также при попытке достать из URL фото имя файла я показал пример работы с PHP функциями обработки строк mb_strpos() и mb_substr(). Ими полезно пользоваться в качестве альтернативы регулярным выражениям, работают быстрее. Префикс mb_ указывает на то, что данные функции корректно работают с многобайтными кодировками, в частности со строками на русском языке.
В результате работы парсера получаем список фото на своём жёстком диске в заданной папке и с заданными именами файлов.

Конечно, можно было бы организовать парсер по AJAX технологии, но у применённого подхода есть свои плюсы. Например, при большом количестве картинок и длительной работе парсера нам необязательно держать вкладку браузера открытой. PHP скрипт сможет долго работать на сервере и сохранять картинки в нужную директорию. При этом, правда, мы не увидим результаты выполнения скрипта. Но то же окончание работы парсера можно будет заметить по прекращению создания новых файлов с фото.
В следующих статьях из цикла про парсеры мы рассмотрим обработку CSV данных и парсинг с помощью специальных библиотек для работы с DOM данными в PHP на примере PHPquery. Оставайтесь на связи.
Источник статьи: http://seorubl.ru/moi-proekty/php-parser-kartinok-s-sayta/