
Нейросеть в 11 строчек на Python
О чём статья
Лично я лучше всего обучаюсь при помощи небольшого работающего кода, с которым могу поиграться. В этом пособии мы научимся алгоритму обратного распространения ошибок на примере небольшой нейронной сети, реализованной на Python.
Дайте код!
Слишком сжато? Давайте разобьём его на более простые части.
Часть 1: Небольшая игрушечная нейросеть
Нейросеть, тренируемая через обратное распространение (backpropagation), пытается использовать входные данные для предсказания выходных.
Предположим, нам нужно предсказать, как будет выглядеть колонка «выход» на основе входных данных. Эту задачу можно было бы решить, подсчитав статистическое соответствие между ними. И мы бы увидели, что с выходными данными на 100% коррелирует левый столбец.
Обратное распространение, в самом простом случае, рассчитывает подобную статистику для создания модели. Давайте попробуем.
Нейросеть в два слоя
X — матрица входного набор данных; строки – тренировочные примеры
y – матрица выходного набора данных; строки – тренировочные примеры
l0 – первый слой сети, определённый входными данными
l1 – второй слой сети, или скрытый слой
syn0 – первый слой весов, Synapse 0, объединяет l0 с l1.
«*» — поэлементное умножение – два вектора одного размера умножают соответствующие значения, и на выходе получается вектор такого же размера
«-» – поэлементное вычитание векторов
x.dot(y) – если x и y – это вектора, то на выходе получится скалярное произведение. Если это матрицы, то получится перемножение матриц. Если матрица только одна из них – это перемножение вектора и матрицы.
И это работает! Рекомендую перед прочтением объяснения поиграться немного с кодом и понять, как он работает. Он должен запускаться прямо как есть, в ipython notebook. С чем можно повозиться в коде:
- сравните l1 после первой итерации и после последней
- посмотрите на функцию nonlin.
- посмотрите, как меняется l1_error
- разберите строку 36 – основные секретные ингредиенты собраны тут (отмечена . )
- разберите строку 39 – вся сеть готовится именно к этой операции (отмечена . )
Разберём код по строчкам
Импортирует numpy, библиотеку линейной алгебры. Единственная наша зависимость.
Наша нелинейность. Конкретно эта функция создаёт «сигмоиду». Она ставит в соответствие любое число значению от 0 до 1 и преобразовывает числа в вероятности, а также имеет несколько других полезных для тренировки нейросетей свойств.
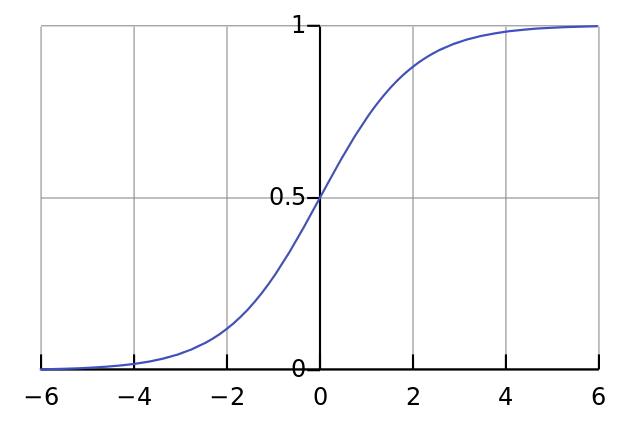
Эта функция также умеет выдавать производную сигмоиды (deriv=True). Это одно из её полезных свойств. Если выход функции – это переменная out, тогда производная будет out * (1-out). Эффективно.
Инициализация массива входных данных в виде numpy-матрицы. Каждая строка – тренировочный пример. Столбцы – это входные узлы. У нас получается 3 входных узла в сети и 4 тренировочных примера.
Инициализирует выходные данные. «.T» – функция переноса. После переноса у матрицы y есть 4 строки с одним столбцом. Как и в случае входных данных, каждая строка – это тренировочный пример, и каждый столбец (в нашем случае один) – выходной узел. У сети, получается, 3 входа и 1 выход.
Благодаря этому случайное распределение будет каждый раз одним и тем же. Это позволит нам проще отслеживать работу сети после внесения изменений в код.
Матрица весов сети. syn0 означает «synapse zero». Так как у нас всего два слоя, вход и выход, нам нужна одна матрица весов, которая их свяжет. Её размерность (3, 1), поскольку у нас есть 3 входа и 1 выход. Иными словами, l0 имеет размер 3, а l1 – 1. Поскольку мы связываем все узлы в l0 со всеми узлами l1, нам требуется матрица размерности (3, 1).
Заметьте, что она инициализируется случайным образом, и среднее значение равно нулю. За этим стоит достаточно сложная теория. Пока просто примем это как рекомендацию. Также заметим, что наша нейросеть – это и есть эта самая матрица. У нас есть «слои» l0 и l1, но они представляют собой временные значения, основанные на наборе данных. Мы их не храним. Всё обучение хранится в syn0.
Тут начинается основной код тренировки сети. Цикл с кодом повторяется многократно и оптимизирует сеть для набора данных.
Первый слой, l0, это просто данные. В X содержится 4 тренировочных примера. Мы обработаем их все и сразу – это называется групповой тренировкой [full batch]. Итого мы имеем 4 разных строки l0, но их можно представить себе как один тренировочный пример – на этом этапе это не имеет значения (можно было загрузить их 1000 или 10000 без всяких изменений в коде).
Это шаг предсказания. Мы позволяем сети попробовать предсказать вывод на основе ввода. Затем мы посмотрим, как это у неё получается, чтобы можно было подправить её в сторону улучшения.
В строке содержится два шага. Первый делает матричное перемножение l0 и syn0. Второй передаёт вывод через сигмоиду. Размерности у них следующие:
Матричные умножения требуют, чтобы в середине уравнения размерности совпадали. Итоговая матрица имеет количество строк, как у первой, а столбцов – как у второй.
Мы загрузили 4 тренировочных примера, и получили 4 догадки (матрица 4х1). Каждый вывод соответствует догадке сети для данного ввода.
Поскольку в l1 содержатся догадки, мы можем сравнить их разницу с реальностью, вычитая её l1 из правильного ответа y. l1_error – вектор из положительных и отрицательных чисел, характеризующий «промах» сети.
А вот и секретный ингредиент. Эту строку нужно разбирать по частям.
l1 представляет три этих точки, а код выдаёт наклон линий, показанных ниже. Заметьте, что при больших значениях вроде x=2.0 (зелёная точка) и очень малые, вроде x=-1.0 (фиолетовая) линии имеют небольшой уклон. Самый большой угол у точки х=0 (голубая). Это имеет большое значение. Также отметьте, что все производные лежат в пределах от 0 до 1.
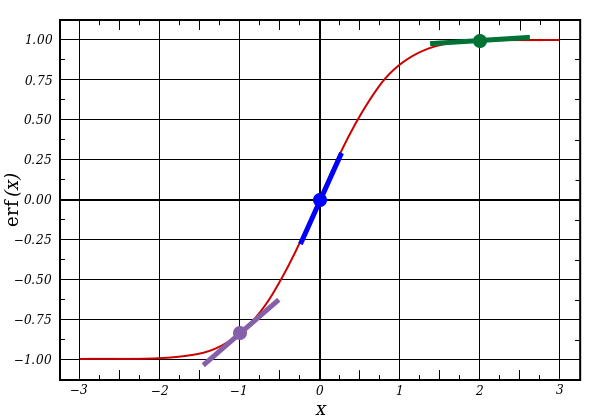
Полное выражение: производная, взвешенная по ошибкам
Математически существуют более точные способы, но в нашем случае подходит и этот. l1_error – это матрица (4,1). nonlin(l1,True) возвращает матрицу (4,1). Здесь мы поэлементно их перемножаем, и на выходе тоже получаем матрицу (4,1), l1_delta.
Умножая производные на ошибки, мы уменьшаем ошибки предсказаний, сделанных с высокой уверенностью. Если наклон линии был небольшим, то в сети содержится либо очень большое, либо очень малое значение. Если догадка в сети близка к нулю (х=0, у=0,5), то она не особенно уверенная. Мы обновляем эти неуверенные предсказания и оставляем в покое предсказания с высокой уверенностью, умножая их на величины, близкие к нулю.
Мы готовы к обновлению сети. Рассмотрим один тренировочный пример. В нём мы будем обновлять веса. Обновим крайний левый вес (9.5)
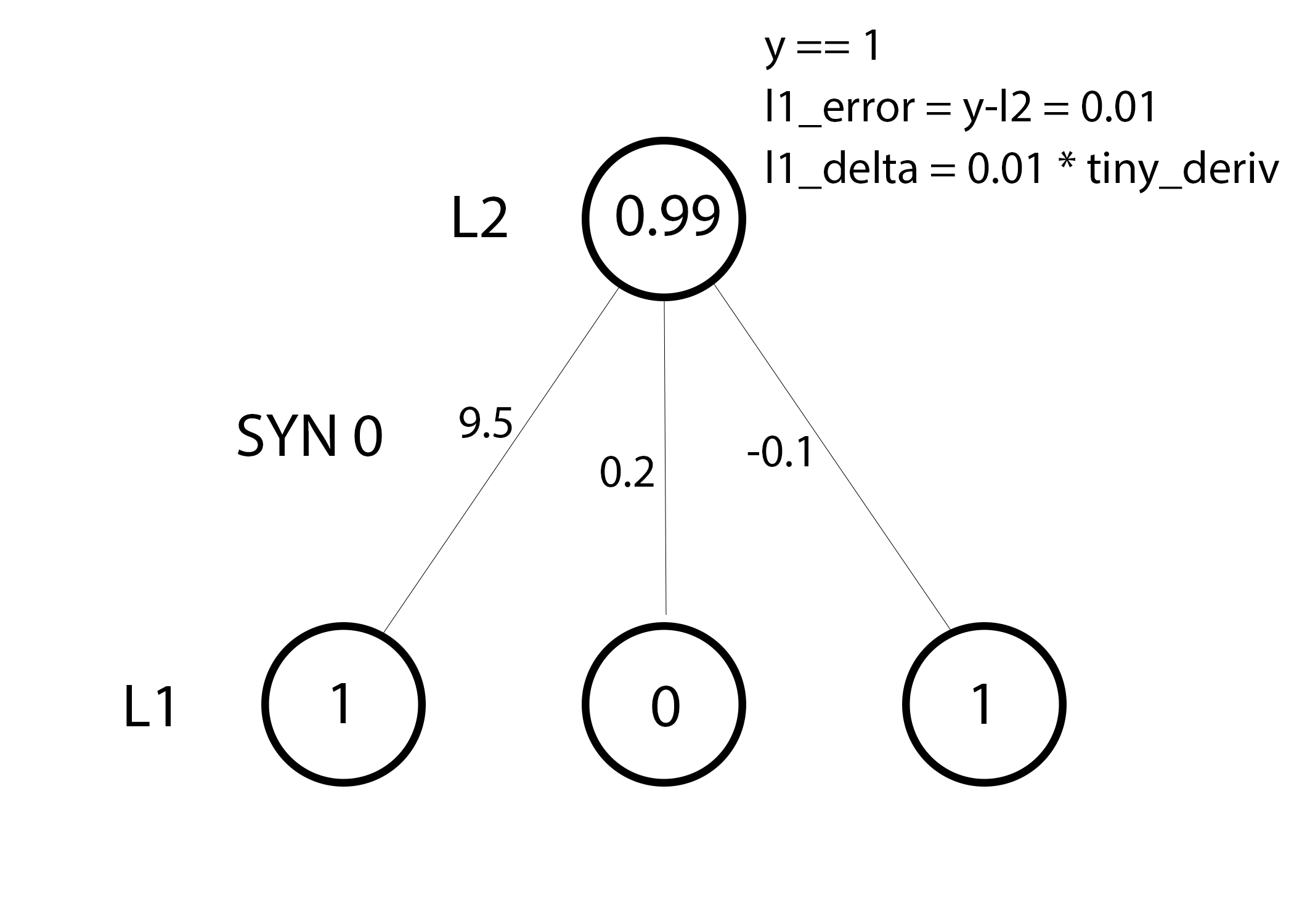
Для крайнего левого веса это будет 1.0 * l1_delta. Предположительно, это лишь незначительно увеличит 9.5. Почему? Поскольку предсказание было уже достаточно уверенным, и предсказания были практически правильными. Небольшая ошибка и небольшой наклон линии означает очень небольшое обновление.
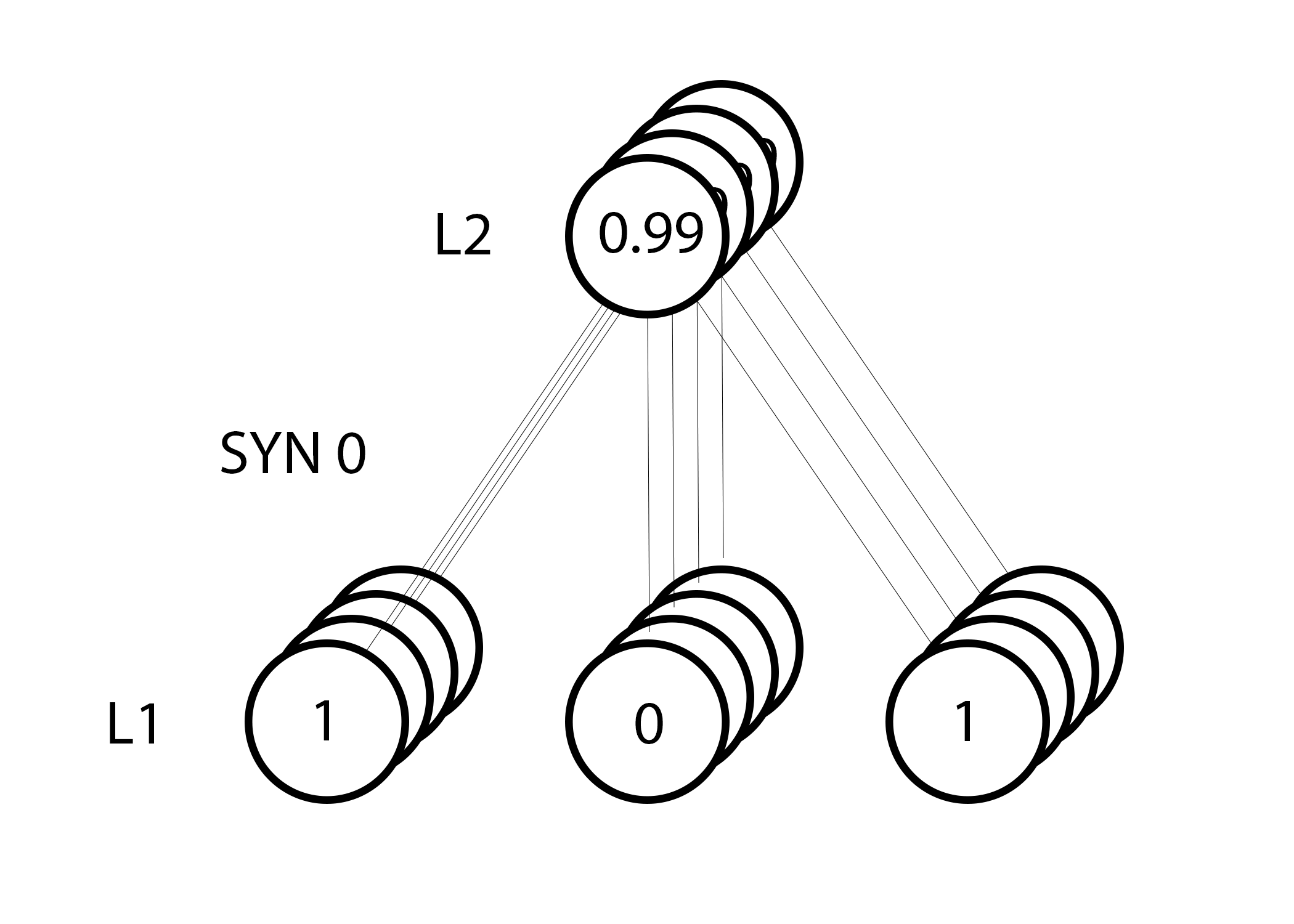
Но поскольку мы делаем групповую тренировку, указанный выше шаг мы повторяем для всех четырёх тренировочных примеров. Так что это выглядит очень похоже на изображение вверху. Так что же делает наша строчка? Она подсчитывает обновления весов для каждого веса, для каждого тренировочного примера, суммирует их и обновляет все веса – и всё одной строкой.
Понаблюдав за обновлением сети, вернёмся к нашим тренировочным данным. Когда и вход, и выход равны 1, мы увеличиваем вес между ними. Когда вход 1, а выход – 0, мы уменьшаем вес.
Таким образом, в наших четырёх тренировочных примерах ниже, вес первого входа по отношению к выходу будет постоянно увеличиваться или оставаться постоянным, а два других веса будут увеличиваться и уменьшаться в зависимости от примеров. Этот эффект и способствует обучению сети на основе корреляций входных и выходных данных.
Часть 2: задачка посложнее
Попробуем предсказать выходные данные на основе трёх входных столбцов данных. Ни один из входных столбцов не коррелирует на 100% с выходным. Третий столбец вообще ни с чем не связан, поскольку в нём всю дорогу содержатся единицы. Однако и тут можно увидеть схему – если в одном из двух первых столбцов (но не в обоих сразу) содержится 1, то результат также будет равен 1.
Это нелинейная схема, поскольку прямого соответствия столбцов один к одному не существует. Соответствие строится на комбинации входных данных, столбцов 1 и 2.
Интересно, что распознавание образов является очень похожей задачей. Если у вас есть 100 картинок одинакового размера, на которых изображены велосипеды и курительные трубки, присутствие на них определённых пикселей в определённых местах не коррелирует напрямую с наличием на изображении велосипеда или трубки. Статистически их цвет может казаться случайным. Но некоторые комбинации пикселей не случайны – те, что формируют изображение велосипеда (или трубки).

Стратегия
Чтобы скомбинировать пиксели в нечто, у чего может появиться однозначное соответствие с выходными данными, нужно добавить ещё один слой. Первый слой комбинирует вход, второй назначает соответствие выходу, используя в качестве входных данных выходные данные первого слоя. Обратите внимание на таблицу.
Случайным образом назначив веса, мы получим скрытые значения для слоя №1. Интересно, что у второго столбца скрытых весов уже есть небольшая корреляция с выходом. Не идеальная, но есть. И это тоже является важной частью процесса тренировки сети. Тренировка будет только усиливать эту корреляцию. Она будет обновлять syn1, чтобы назначить её соответствие выходным данным, и syn0, чтобы лучше получать данные со входа.
Нейросеть в три слоя
Переменные и их описания
X — матрица входного набор данных; строки – тренировочные примеры
y – матрица выходного набора данных; строки – тренировочные примеры
l0 – первый слой сети, определённый входными данными
l1 – второй слой сети, или скрытый слой
l2 – финальный слой, это наша гипотеза. По мере тренировки должен приближаться к правильному ответу
syn0 – первый слой весов, Synapse 0, объединяет l0 с l1.
syn1 – второй слой весов, Synapse 1, объединяет l1 с l2.
l2_error – промах сети в количественном выражении
l2_delta – ошибка сети, в зависимости от уверенности предсказания. Почти совпадает с ошибкой, за исключением уверенных предсказаний
l1_error – взвешивая l2_delta весами из syn1, мы подсчитываем ошибку в среднем/скрытом слое
l1_delta – ошибки сети из l1, масштабируемые по увеернности предсказаний. Почти совпадает с l1_error, за исключением уверенных предсказаний
Код должен быть достаточно понятным – это просто предыдущая реализация сети, сложенная в два слоя один над другим. Выход первого слоя l1 – это вход второго слоя. Что-то новое есть лишь в следующей строке.
Использует ошибки, взвешенные по уверенности предсказаний из l2, чтобы подсчитать ошибку для l1. Получаем, можно сказать, ошибку, взвешенную по вкладам – мы подсчитываем, какой вклад в ошибки в l2 вносят значения в узлах l1. Этот шаг и называется обратным распространением ошибок. Затем мы обновляем syn0, используя тот же алгоритм, что и в варианте с нейросетью из двух слоёв.
Источник статьи: http://habr.com/ru/post/271563/
Простая нейронная сеть в 9 строк кода на Python
Из статьи вы узнаете, как написать свою простую нейросеть на python с нуля, не используя никаких библиотек для нейросетей. Если у вас еще нет своей нейронной сети, вот всего лишь 9 строчек кода:
Перед вами перевод поста How to build a simple neural network in 9 lines of Python code, автор — Мило Спенсер-Харпер. Ссылка на оригинал — в подвале статьи.
В статье мы разберем, как это получилось, и вы сможете создать свою собственную нейронную сеть на python. Также будут показаны более длинные и красивые версии кода.
 Диаграмма 1
Диаграмма 1
Но для начала, что же такое нейронная сеть? Человеческий мозг состоит из 100 миллиарда клеток, называемых нейронами, соединенных синапсами. Если достаточное количество синаптичеких входов возбуждены, то и нейрон тоже становится возбужденным. Этот процесс также называется “мышление”.
Мы можем смоделировать этот процесс, создав нейронную сеть на компьютере. Не обязательно моделировать всю сложную модель человеческого мозга на молекулярном уровне, достаточно только высших правил мышления. Мы используем математические техники называемые матрицами, то есть просто сетки с числами. Чтобы сделать все максимально просто, построим модель из трех входных сигналов и одного выходного.
Мы будем тренировать нейрон на решение задачи, представленной ниже.
Первые четыре примера назовем тренировочной выборкой. Вы сможете выделить закономерность? Что должно стоять на месте “?”
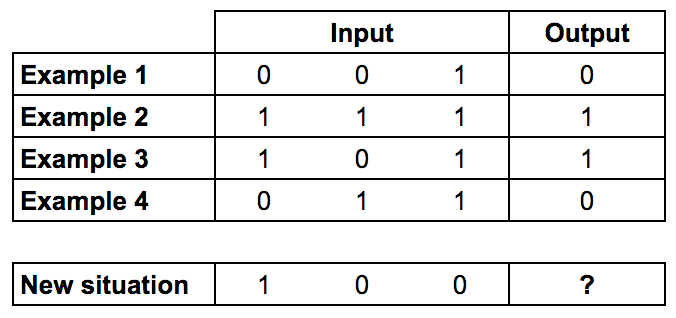 Диаграмма 2. Input — входный сигнал, Output — выходной сигнал.
Диаграмма 2. Input — входный сигнал, Output — выходной сигнал.
Вероятно вы заметили, что выходной сигнал всегда равен самой левой входной колонке. Таким образом ответ будет 1.
Процесс обучения нейронной сети
Как же должно происходить обучение нашего нейрона, чтобы он смог ответить правильно? Мы добавим каждому входу вес, который может быть положительным или отрицательным числом. Вход с большим положительным или большим отрицательным весом сильно повлияет на выход нейрона. Прежде чем мы начнем, установим каждый вес случайным числом. Затем начнем обучение:
- Берем входные данные из примера обучающего набора, корректируем их по весам и передаем по специальной формуле для расчета выхода нейрона.
- Вычисляем ошибку, которая является разницей между выходом нейрона и желаемым выходом в примере обучающего набора.
- В зависимости от направления ошибки слегка отрегулируем вес.
- Повторите этот процесс 10 000 раз.
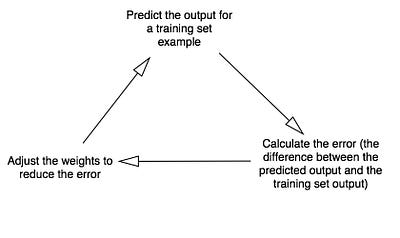 Диаграмма 3
Диаграмма 3
В конце концов вес нейрона достигнет оптимального значения для тренировочного набора. Если мы позволим нейрону «подумать» в новой ситуации, которая сходна с той, что была в обучении, он должен сделать хороший прогноз.
Формула для расчета выхода нейрона
Вам может быть интересно, какова специальная формула для расчета выхода нейрона? Сначала мы берем взвешенную сумму входов нейрона, которая:
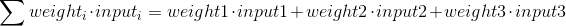
Затем мы нормализуем это, поэтому результат будет между 0 и 1. Для этого мы используем математически удобную функцию, называемую функцией Sigmoid:
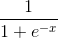
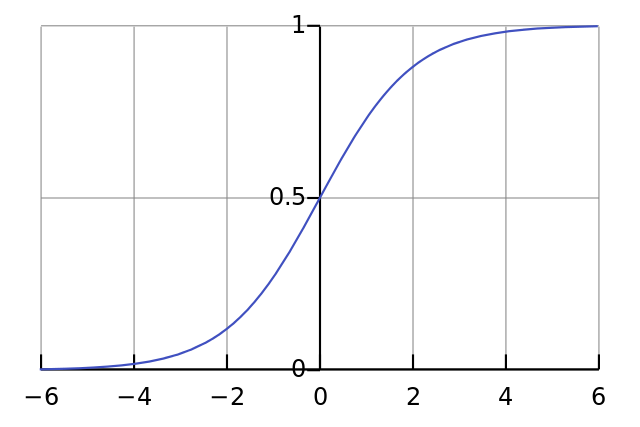
Если график нанесен на график, функция Sigmoid рисует S-образную кривую.
Подставляя первое уравнение во второе, получим окончательную формулу для выхода нейрона:
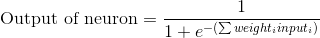
Возможно, вы заметили, что мы не используем пороговый потенциал для простоты.
Формула для корректировки веса
Во время тренировочного цикла (Диаграмма 3) мы корректируем веса. Но насколько мы корректируем вес? Мы можем использовать формулу «Взвешенная по ошибке» формула
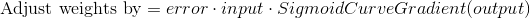
Почему эта формула? Во-первых, мы хотим сделать корректировку пропорционально величине ошибки. Во-вторых, мы умножаем на входное значение, которое равно 0 или 1. Если входное значение равно 0, вес не корректируется. Наконец, мы умножаем на градиент сигмовидной кривой (диаграмма 4). Чтобы понять последнее, примите во внимание, что:
-
- Мы использовали сигмовидную кривую для расчета выхода нейрона.
- Если выходной сигнал представляет собой большое положительное или отрицательное число, это означает, что нейрон так или иначе был достаточно уверен.
- Из Диаграммы 4 мы можем видеть, что при больших числах кривая Сигмоида имеет небольшой градиент.
- Если нейрон уверен, что существующий вес правильный, он не хочет сильно его корректировать. Умножение на градиент сигмовидной кривой делает именно это.
Градиент Сигмоды получается, если посчитать взятием производной:
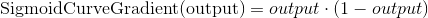
Вычитая второе уравнение из первого получаем итоговую формулу:
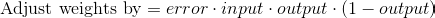
Существуют также другие формулы, которые позволяют нейрону учиться быстрее, но приведенная имеет значительное преимущество: она простая.
Написание Python кода
Хоть мы и не будем использовать библиотеки с нейронными сетями, мы импортируем 4 метода из математической библиотеки numpy. А именно:
- exp — экспоненцирование
- array — создание матрицы
- dot — перемножения матриц
- random — генерация случайных чисел
Например, мы можем использовать array() для представления обучающего множества, показанного ранее.
“.T” — функция транспонирования матриц. Итак, теперь мы готовы для более красивой версии исходного кода. Заметьте, что на каждой итерации мы обрабатываем всю тренировочную выборку одновременно.
Код также доступен на гитхабе. Если вы используете Python3 нужно заменить xrange на range.
Заключительные мысли
Попробуйте запустить нейросеть, используя команду терминала:
Итоговый должен быть похож на это:
У нас получилось! Мы написали простую нейронную сеть на Python!
Сначала нейронная сеть присваивала себе случайные веса, а затем обучалась с использованием тренировочного набора. Затем нейросеть рассмотрела новую ситуацию [1, 0, 0] и предсказала 0.99993704. Правильный ответ был 1. Так очень близко!
Традиционные компьютерные программы обычно не могут учиться. Что удивительного в нейронных сетях, так это то, что они могут учиться, адаптироваться и реагировать на новые ситуации. Так же, как человеческий разум.
Конечно, это был только 1 нейрон, выполняющий очень простую задачу. А если бы мы соединили миллионы этих нейронов вместе?
Источник статьи: http://neurohive.io/ru/tutorial/prostaja-nejronnaja-set-python/