
Учимся писать парсер сайта своими руками
Сегодня я приведу вам в пример, который возможно понадобиться начинающим парсерам и возможно вы найдете в нем ценную информацию. В комментариях очень хотелось бы увидеть возможные изменения для упрощения задачи, так что всегда рад услышать ваши мнения.
Передо мной стояла задача заполнить интернет магазин товарами в количестве свыше 50 тыс наименований. Оригиналы товаров лежали на сайтах поставщиков.
Особо заморачиваться с кодом и решением я не стал, поэтому сделал все максимально просто и быстро.
Прикрепленные файлы буду выкладывать на проекте моих друзей и партнеров 2file.ru Будьте уверены что все ссылки всегда будут действующими и вы всегда сможете скачать любой файл из данной инструкции. +размер файлов не ограничен, нет времени ожидания и нет рекламмы.
Первым делом я решил скачать полностью сайт себе чтобы в дальнейшем было проще работать с ним.
Для Windows нам потребуется программа wget (КАЧАЕМ)
Распаковываем например на диск С и для удобства переименовываем в wget.
Далее нажимаем пуск-выполнить-cmd и там вводим CD C:\wget\. Далее нам нужно запустить команду wget.exe -c -p -r -l0 -np -N -k -nv АДРЕС САЙТА 2>wget.log. Описание команд -c -p -r -l0 -np -N -k -nv можно подробно почитать ТУТ. Нажимаем enter и начинается скачивание. В папке wget появляется папка с названием сайта, куда сливается сайт. ВНИМАНИЕ, при больших объемах, сайт может скачиваться даже несколько дней.
. Прошло несколько дней…
Вот мы и дождались загрузки сайта на наш компьютер. В моем случаи в корне находились страницы с подробным описанием товаров, так что буду следовать отсюда.
Нам понадобится установленный на компьютере сервер apache+php. Для удобства и быстроты настройки можно использовать например xampp, который можно взять бесплатно на ЭТОМ сайте, где так-же приведен процесс инсталяции.
Ок, теперь у нас стоит апач, есть скачанный сайт. Далее для удобства я перенес все скачанные странички в папку xampp для дальнейшей работы с ними. Чтобы не усложнять код, я переименовал все страницы в порядковые номера чтобы получилось 1.html, 2.html… и так далее. Сделать это очень просто. Например через total commender в меню файлы-групповое переименование. Далее в папке с переименованными страницами я создал index.php файл. Теперь начнем разбираться в коде:
(.+?.) #is’, $html, $matches );
foreach ( $matches[1] as $value ) echo $value.’<br>’;
?>
Первой строчкой я указываю на открытие 132.html, в котором будет осуществляться выборка данных.
Открыв любую скачанную страницу, мы видим что интересующая нас информация находится между тегами.
Один из моих примеров это
preg_match_all( ‘#(.+?.)#is’, $html, $matches );
Далее осуществляется вывод полученных данных на экран и спуск на строчку вниз br.
Для выдирания нескольких результатов из одной страницы, можно использовать код на подобии:
(.+?.) #is’, $html, $matches );
preg_match_all( ‘# (.+?.) #is’, $html, $matches1 );
preg_match_all( ‘# (.+?.) #is’, $html, $matches2 );
foreach ( $matches[1] as $value ) echo $value.’ ‘;
foreach ( $matches1[1] as $value ) echo $value.’ ‘;
foreach ( $matches2[1] as $value ) echo $value.’<br>’;
?>
Должно получится что-то вроде (значение1, значение2, значение3 <br>)
Теперь немного дополним наш код чтобы прогнать все наши скачанные страницы. Решил сделать с помощью цикла и получилось что-то вроде этого:
(.+?.) #is’, $html, $matches );
preg_match_all( ‘# (.+?.) #is’, $html, $matches1 );
preg_match_all( ‘# (.+?.) #is’, $html, $matches2 );
foreach ( $matches[1] as $value ) echo $value.’ ‘;
foreach ( $matches1[1] as $value ) echo $value.’ ‘;
foreach ( $matches2[1] as $value ) echo $value.’<br>’;
Отлично, теперь мы видим что-то вроде этого:
значение#значение#значение
значение#значение#значение
Для удобства дальнейшей работы я использовал #. Теперь копируем все что получилось, загоняем в excel, нажимаем данные-текст по столбцам и ставим # в качестве разделителя столбцов. Отлично, мы получили таблицу с результатами нашего парсинга. УРА
Дальнейшая работа зависит от вашей фантазии и цели. Спасибо за внимания, надеюсь на инвайт.
Данная статья не подлежит комментированию, поскольку её автор ещё не является полноправным участником сообщества. Вы сможете связаться с автором только после того, как он получит приглашение от кого-либо из участников сообщества. До этого момента его username будет скрыт псевдонимом.
Источник статьи: http://habr.com/ru/sandbox/30536/
Как я html-парсер на php писал, и что из этого вышло. Заключительная часть
Представляю вам заключительную главу цикла. В ней пойдет речь о реализации самого парсера, его модулей, вроде функции анализа, построения стека и dom дерева. Помимо этого поговорим и об обработке комментариев. Как оказалось, комментарии могут обрабатываться по разному.
Напишем свой поиск элементов, подробнее поговорим о поиске по классам и идентификаторам. И многое другое!
Введение
Если вы не знакомы с устройством html парсеров и не прочитали предыдущею главу, рекомендую почитать. Я обновил в ней картинки, так что теперь воспринимать информацию там приятнее.
В этой статье будет введен новый ряд терминов:
- Цепочка — последовательность любых символов.
- Состояние — условие, от которого будет зависеть дальнейшая обработка цепочки парсером.
- Токен — массив, содержащий информацию о теге, комментарии или тексте. Также токен часто называют “Словом”.
- Стек — массив, содержащий токены.
- Разграничительный символ — символ, после которого следующая цепочка обрабатывается как новая цепочка.
- Алфавит — список символов, которые имеют первостепенную важность для парсера.
Если термины из списка вам не понятны, не волнуйтесь: в контексте все станет ясно.
Главные переменные парсера
Перед тем как писать парсер, следует определится с главными переменными, чтобы потом отталкиваться от них при дальнейшем написании.
- $__SOURCE_TEXT — Содержит в себе текст исходного документа.
- $__DOM — Содержит в себе полученный в результате парсинга массив с dom деревом.
- $__ENABLE_COMMENTS — Означает, включена ли функция отображения комментариев или нет.
- $__ESCAPE_SYMBOLS — Массив со специальными символами и пробелом.
- $__MANDATORY_OPEN_ELEMENTS — Массив из четырех ячеек, обозначающие наличие обязательных открывающих тегов в документе.
- $__MANDATORY_CLOSE_ELEMENTS — Массив из трёх ячеек, обозначающие наличие обязательных закрывающих тегов в документе.
Класс парсера и его конструктор
Для того, чтобы потом было легче добавлять функционал, напишем класс парсера. В начале там будет функция отправки запросов, но постепенно туда будет записываться новый функционал.
Давайте кратко вспомним, как работает анализ
Как вы помните, в первой части статьи, работа парсера была разделена на два этапа. Так вот, в начале я буду говорить о первом этапе, об отделении текста от тегов.
Чтобы дальше было проще, первый этап я буду называть «Анализом».
Итак, как работает анализ в парсере. Сначала, он берет символ. Если этот символ равен » , и . Если таковых нет в документе, либо присутствуют только закрывающие или открывающие обязательные теги, они ставятся в определенных местах. Давайте посмотрим, в каких:
- — Этот тег ставиться в конце и начале документа(после ), если после него не идет комментарий. В ином случаи поставиться ровно после комментария.
- — Ставится в месте, где есть теги
- , ,
Источник статьи: http://habr.com/ru/post/505392/
Как я html-парсер на php писал, и что из этого вышло. Вводная часть
Сегодня я хочу рассказать, как написать html парсер, а также с какими проблемами я столкнулся, разрабатывая подобный парсер на php. А проблем было много. И в первой части я расскажу о проектировании парсера, и о возникших проблемах, ведь html парсер отличается от парсера привычных всем языков программирования.
Введение
Я старался написать текст этой статьи максимально понятно, чтобы любой, кто даже не знаком с общим устройством парсеров мог понять то, как работает html парсер.
Здесь и далее в статье я буду называть документ, содержащий html просто «Документ».
Dom дерево, находящееся в элементе, будет называться «Подмассив».
Что должен делать парсер?
Давайте сначала определимся, что должен делать парсер, чтобы в будущем отталкиваться от этого при разработке. А именно, парсер должен:
- Проектировать dom-дерево на основе документа
- Если есть ошибки в документе, то он должен их решать
- Находить элементы в dom-дереве
- Находить children элементы
- Находить текст
Это самый простой список того, что должен уметь парсер. По-хорошему, он еще должен отправлять информацию об ошибках, если таковые были найдены в исходном документе.
Впрочем, это мелочи. Основного функционала вполне хватит, чтобы поломать голову пару ночей напролет.
Но тут есть проблема, с которой я столкнулся сразу же: Html — это не просто язык, это язык гипертекста. У такого языка свой синтаксис, и обычный парсер не подойдет.
Разделяй и властвуй
Для начала, нужно разделить работу парсера на два этапа:
- Отделение обычного текста от тегов
- Сортировка всех полученных тегов в dom дерево
Это что касается непосредственно парсинга документа. Про поиск элементов я буду говорить чуть позже далее в этой главе.
Для описания первого этапа я нарисовал схему, которая наглядно показывает, как обрабатываются данные на первом этапе:
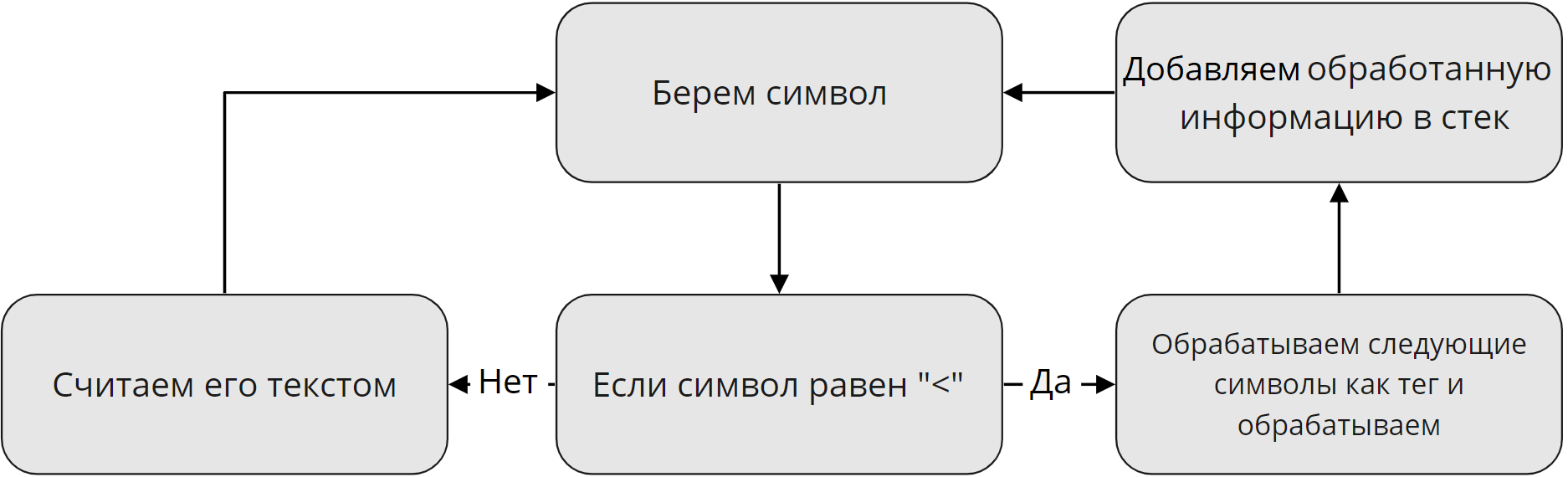
Я решил опустить все мелкие детали. Например, как отличить, что после открывающего » » не был найден
Такая ошибка будет возникать в том случаи, если парсер дошел до конца документа и не нашел закрывающего символа «>».
Неизвестное значение атрибута
Данная ошибка сигнализирует о том, что была проведена попытка передачи значения атрибуту когда закрывающий тег был найден.
Данная ошибка возникает в двух случаях: Либо у атрибута тега в названии есть » Теги:
- парсер
- синтаксический анализатор
- html5
- php
Добавить метки Хабы:
- PHP
- HTML
Источник статьи: http://habr.com/ru/post/505264/
Пишем парсер контента на PHP
Чтобы написать хороший и работоспособный скрипт для парсинга контента нужно потратить немало времени. А подходить к сайту-донору, в большинстве случаев, стоит индивидуально, так как есть масса нюансов, которые могут усложнить решение нашей задачи. Сегодня мы рассмотрим и реализуем скрипт парсера при помощи CURL, а для примера получим категории и товары одного из популярных магазинов.
Если вы попали на эту статью из поиска, то перед вами, наверняка, стоит конкретная задача и вы еще не задумывались над тем, для чего ещё вам может пригодится парсер. Поэтому, перед тем как вдаваться в теорию и непосредственно в код, предлагаю прочесть предыдущею статью – парсер новостей, где был рассмотрен один из простых вариантов, да и я буду периодически ссылаться на неё.
Работать мы будем с CURL, но для начала давайте разберёмся, что эта аббревиатура обозначает. CURL – это программа командной строки, позволяющая нам общаться с серверами используя для этого различные протоколы, в нашем случаи HTTP и HTTPS. Для работы с CURL в PHP есть библиотека libcurl, функции которой мы и будем использовать для отправки запросов и получения ответов от сервера.
Двигаемся дальше и определяемся с нашей целью. Для примера я выбрал наверняка всем известный магазин svyaznoy . Для того, чтобы спарсить категории этого магазина, предлагаю перейти на страницу каталога:

Как можно увидеть из скриншота все категории находятся в ненумерованном списке, а подкатегории:

Внутри отельного элемента списка в таком же ненумерованном. Структура несложная, осталось только её получить. Товары мы возьмем из раздела «Все телефоны»:

На странице получается 24 товара, у каждого мы вытянем: картинку, название, ссылку на товар, характеристики и цену.
Пишем скрипт парсера
Если вы уже прочли предыдущею статью, то из неё можно было подчеркнуть, что процесс и скрипт парсинга сайта состоит из двух частей:
- Нужно получить HTML код страницы, которой нам необходим;
- Разбор полученного кода с сохранением данных и дальнейшей обработки их (как и в первой статье по парсингу мы будем использовать phpQuery, в ней же вы найдете, как установить её через composer).
Для решения первого пункта мы напишем простой класс с одним статическим методом, который будет оберткой над CURL. Так код можно будет использовать в дальнейшем и, если необходимо, модифицировать его. Первое, с чем нам нужно определиться — как будет называться класс и метод и какие будут у него обязательные параметры:
Основной метод, который у нас будет – это getPage() и у него всего один обязательный параметр URL страницы, которой мы будем парсить. Что ещё будет уметь наш замечательный метод, и какие значения мы будем обрабатывать в нем:
- $useragent – нам важно иметь возможность устанавливать заголовок User-Agent, так мы сможем сделать наши обращения к серверу похожими на обращения из браузера;
- $timeout – будет отвечать за время выполнения запроса на сервер;
- $connecttimeout – так же важно указывать время ожидания соединения;
- $head – если нам потребуется проверить только заголовки, которые отдаёт сервер на наш запрос этот параметр нам просто будет необходим;
- $cookie_file – тут всё просто: файл, в который будут записывать куки нашего донора контента и при обращении передаваться;
- $cookie_session – иногда может быть необходимо, запрещать передачу сессионных кук;
- $proxy_ip – параметр говорящий, IP прокси-сервера, мы сегодня спарсим пару страниц, но если необходимо несколько тысяч, то без проксей никак;
- $proxy_port – соответственно порт прокси-сервера;
- $proxy_type – тип прокси CURLPROXY_HTTP, CURLPROXY_SOCKS4, CURLPROXY_SOCKS5, CURLPROXY_SOCKS4A или CURLPROXY_SOCKS5_HOSTNAME;
- $headers – выше мы указали параметр, отвечающий за заголовок User-Agent, но иногда нужно передать помимо его и другие, для это нам потребуется массив заголовков;
- $post – для отправки POST запроса.
Конечно, обрабатываемых значений много и не всё мы будем использовать для нашей сегодняшней задачи, но разобрать их стоит, так как при парсинге больше одной страницы многое выше описанное пригодится. И так добавим их в наш скрипт:
Как видите, у всех параметров есть значения по умолчанию. Двигаемся дальше и следующей строчкой напишем кусок кода, который будет очищать файл с куками при запросе:
Так мы обезопасим себя от ситуации, когда по какой-либо причине не создался файл.
Для работы с CURL нам необходимо вначале инициализировать сеанс, а по завершению работы его закрыть, также при работе важно учесть возможные ошибки, которые наверняка появятся, а при успешном получении ответа вернуть результат, сделаем мы это таким образам:
Первое, что вы могли заметить – это статическое свойство $error_codes, к которому мы обращаемся, но при этом его ещё не описали. Это массив с расшифровкой кодов функции curl_errno(), давайте его добавим, а потом разберем, что происходит выше.
После того, как мы инициализировали соединения через функцию curl_setopt(), установим несколько параметров для текущего сеанса:
- CURLOPT_URL – первый и обязательный — это адрес, на который мы обращаемся;
- CURLINFO_HEADER_OUT –массив с информацией о текущем соединении.
Используя функцию curl_exec(), мы осуществляем непосредственно запрос при помощи CURL, а результат сохраняем в переменную $content, по умолчанию после успешной отработки результат отобразиться на экране, а в $content упадет true. Отследить попутную информацию при запросе нам поможет функция curl_getinfo(). Также важно, если произойдет ошибка — результат общения будет false, поэтому, ниже по коду мы используем строгое равенство с учетом типов. Осталось рассмотреть ещё две функции это curl_error() – вернёт сообщение об ошибке, и curl_errno() – код ошибки. Результатом работы метода getPage() будет массив, а чтобы его увидеть давайте им воспользуемся, а для теста сделаем запрос на сервис httpbin для получения своего IP.
Кстати очень удобный сервис, позволяющий отладить обращения к серверу. Так как, например, для того что бы узнать свой IP или заголовки отправляемые через CURL, нам бы пришлось бы писать костыль.
Если вывести на экран, то у вас должна быть похожая картина:

Если произойдет ошибка, то результат будет выглядеть так:

При успешном запросе мы получаем заполненную ячейку массива data с контентом и информацией о запросе, при ошибке заполняется ячейка error. Из первого скриншота вы могли заметить первую неприятность, о которой я выше писал контент сохранился не в переменную, а отрисовался на странице. Чтобы решить это, нам нужно добавить ещё один параметр сеанса CURLOPT_RETURNTRANSFER.
Обращаясь к страницам, мы можем обнаружить, что они осуществляют редирект на другие, чтобы получить конечный результат добавляем:
Теперь можно увидеть более приятную картину:

Двигаемся далее, мы описали переменные $useragent, $timeout и $connecttimeout. Добавляем их в наш скрипт:
Для того, чтобы получить заголовки ответа, нам потребуется добавить следующий код:
Мы отключили вывод тела документа и включили вывод шапки в результате:

Для работы со ссылками с SSL сертификатом, добавляем:
Уже получается весьма неплохой скрипт парсера контента, мы добрались до кук и тут стоит отметить — частая проблема, когда они не сохраняются. Одной из основных причин может быть указание относительного пути, поэтому нам стоит это учесть и написать следующие строки:
Предлагаю проверить, а для этого я попробую вытянуть куки со своего сайта:

Всё получилось, двигаемся дальше и нам осталось добавить в параметры сеанса: прокси, заголовки и возможность отправки запросов POST:
Это малая доля параметров, с которыми можно работать, все остальные находятся в официальной документации PHP . Вот мы завершили с нашей оберткой, и пришло время, что-нибудь спарсить!
Парсим категории и товары с сайта
Теперь, при помощи нашего класса Parser, мы можем сделать запрос и получить страницу с контентом. Давайте и поступим:
Следующим шагом разбираем пришедший ответ и сохраняем название и ссылку категории в результирующий массив:
Чуть более подробно работу с phpQuery я разобрал в первой статье по парсингу контента. Если вкратце, то мы пробегаемся по DOM дереву и вытягиваем нужные нам данные, их я решил протримить, чтобы убрать лишние пробелы. А теперь выведем категории на экран:

В результате мы получили все ссылки на категории. Для получения товаров используем тот же принцип:
Получаем страницу, тут я увеличил время соединения, так как 5 секунд не хватило, и разбираем её, парся необходимый контент:
Теперь проверим, что у нас получилось, и выведем на экран:

Вот мы и написали парсер контента PHP, как видите, нет нечего сложного, при помощи этого скрипта можно легко спарсить страницы любого сайта, но перед тем, как заканчивать статью, хотелось пояснить некоторые моменты. Во-первых, если вы хотите парсить более одной страницы, то не стоит забывать, что сам процесс парсинга ресурса затратная операция, поэтому в идеале лучше, чтобы скрипт был вынесен на отдельный сервер, где и будет запускаться по крону. Ещё один момент — к каждому донору стоит подходить индивидуально, так как, во-первых: у них разный HTML код и он, с течением времени, может меняться, во-вторых: могут быть различные защиты от парсинга и проверки, поэтому для подбора необходимого набора заголовков и параметров может потребоваться отладочный прокси (я пользуюсь Fiddler). И последние, что я добавлю — используйте для парсинга прокси и чем больше, тем лучше, так как, когда на сервер донора полетят тысячи запросов, то неизбежно IP, с которого осуществляется обращение будет забанен, поэтому стоит прогонять свои запросы через прокси-сервера.
Полный пример с библеотекай phpQuery вы найдете на github .
Источник статьи: http://falbar.ru/article/pishem-parser-kontenta-na-php