В старых простых телефонах отправить длинное смс было просто — оно разбивалось на несколько коротких сообщений и доставлялось адресату по частям. В смартфонах на андроиде длинное смс преобразуется в ммс и приходит адресату в виде мультимедийного сообщения.
Почему на анроиде смс преобразуются в ммс
Преобразование длинных смс в ммс происходит по разным причинам:
чтобы избежать ошибки приема-передачи сообщений на разных устройствах;
передача одного ммс может быть дешевле отправки нескольких смс;
ограничение мобильной сети.
Это неудобно. Не у каждого на телефоне настроен прием ммс. Да, есть Viber, Telegram и другие сервисы общения через интернет. Но как быть, если необходимо отправить длинное сообщение именно в виде sms?
Как отключить преобразование смс в ммс
Первое, что приходит в голову — покопаться в настройках телефона. Но ни в настройках приложения для отправки сообщений, ни в настройках самого андроида нет возможности отключить преобразование длинных смс в ммс.
Для этого в плей маркете есть альтернативные программы отправки сообщений. С их помощью Вы сможете отправить длинные смски, и, если программа понравиться, установить ее программой для приема-отправки сообщений по умолчанию.
Go SMS Pro
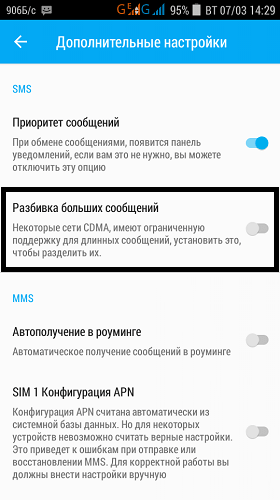
Одна из лучших альтернативных программ для приема-отправки сообщений на андроиде. Функционал богатый, но нам сейчас нужна только одна функция. Находится она по пути «Настройки — Основные — Дополнительные настройки — Разбивка больших сообщений».
Если функция выключена, SMS не будут преобразовываться в MMS.
Handcent SMS
Альтернатива GO SMS Pro — приложение Handcent. Оно тоже позволяет отправлять длинные сообщения без преобразования их в ммс. Но эта программа не настолько удобная. Хотя бы потому, что при первом запуске она предлагает скачать собственный языковой пакет для полноценной работы.
После установки программ надо будет установить их приложениями по умолчанию для работы с SMS. Если интерфейс и функции программ Вам понравятся больше, чем родное приложение, используйте их. Если нет, просто удалите их.
А Вы сталкивались с необходимостью отправить длинное собщение? Как Вы решали эту проблему?
Решил я тут как-то немного изменить свою программку для отправки SMS-сообщений, а именно – добавить возможность отправлять длинные SMS (больше 160 латинских или 70 русских символов). Поковырял иностранные источники, почесал репу, разобрался, сделал, работает. Теперь, в продолжение предыдущих своих статей на тему SMS и PDU, опишу как это делается, может кому пригодится.
Технически, отсылка длинных SMS почти ничем не отличается от отсылки коротких. Вся процедура сводится к разбиению длинного сообщения на короткие и добавлению дополнительного информационного блока в поле TP-UD (TP-User-Data) и отправка этих коротких кусочков. После того, как телефон получил все сообщения, по информации из дополнительного информационного блока он собирает отдельные SMS в одну длинную.
Для тех, кто забыл, что такое PDU и с чем его едят отсылаю к теории: Отправка SMS-сообщений в формате PDU, теория с примерами на C#, часть 1
Итак, приступим к формированию правильной PDU-строки для отправки длинного сообщения.
1. PDU-Type и TP-MR
PDU-Type – Поле флагов. Для отправки простого сообщения туда нужно было поставить “01”. В нашем случае, для отправки длинного сообщения в этом поле должно быть “41”. Т.е. если смотреть по битам, должен быть установлен бит TP-UDHI, который дает понять телефону, что сообщение содержит блок UDH (User Data Header), тот самый дополнительный информационный блок, в котором будет содержаться информация о частях сообщения.
TP-MR (TP-Message-Reference) — поле, следующее за PDU-Type. В случае ошибки доставки сообщение об ошибке будет содержать этот номер, чтобы мы знали, в каком из отосланных нами сообщений произошла ошибка. Наверное для того, чтобы переотправить, если что. Буржуйские источники пишут, что поле TP-MR должно быть разным у каждого короткого сообщения, на которые делится одно длинное. Лично я пробовал ставить везде одинаковое значение – все кусочки сообщения отправляет, длинное на телефон приходит. Однако если отправить следом еще одно сообщение модем отвечает какой-то ошибкой. В результате я тупо увеличиваю это поле на единичку для каждого следующего сообщения. В этом случае все хорошо.
2. Теория поля UDH
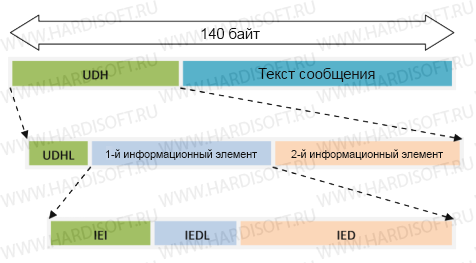
Новое поле UDH, которое содержит информацию о частях сообщения, должно находиться сразу после поля TP-UDL (TP-User-Data-Length – длина сообщения). Т.е. поле UDH по сути является частью поля TP-UD (TP-User-Data), т.е. частью текста сообщения, для которого отводится 140 байт.
UDH–поле предназначено не только для отправки длинных сообщений, однако далее я буду рассматривать его именно применительно к нашей задаче. Итак, из чего же состоит UDH? Смотрим на таблички и вникаем в пояснения:
Общий формат UDH для текста, закодированного 7-битной кодировкой (символы ASCII, т.е. только латинские символы):
UDHL
1 байт
Длина блока UDH в байтах
UDH
n байт
Непосредственно UDH-данные
filler
0-6 бит
Наполнитель, который выравнивает text по границе септета
text
m септетов
непосредственно 7-битные символы сообщения
Пояснение: Этот формат UDH, как уже было написано выше, применяется для сообщений, написанных в ASCII кодировке, т.е. латинскими символами. В этом случае сообщение кодируется в 7-битную кодировку. Принцип этой кодировки я уже объяснял в предыдущей статье, повторяться не буду. Скажу лишь, что в 7-битной упаковке (за счет смещения битов) каждый 8 байт является началом отдельного блока, с которого можно начинать нормально декодировать символы. Символы при кодировании как бы “размазываются” по соседним байтам, начало в одном, конец в другом. Вот поэтому и нужен наполнитель (filler) – чтобы после блока UDH выровнять границу начала текста по границе начала септета.
А зачем это нужно? А для совместимости. Если вы будете отправлять длинную SMS на телефон, который с ними работать не умеет, то он сразу начнет декодировать UDH как текст сообщения! Естественно, он из UDH получит бессвязную белиберду, однако если не выровнять символы последующего текста по границе байта – то он вообще весь текст как белиберду декодирует. А правильно выровненный после UDH текст он декодирует нормально, и получится “[белиберда вместо UDH] текст сообщения”.
В общем, это сильно замороченный вопрос, однако решается он достаточно просто, как будет видно ниже.
Общий формат UDH для текста, закодированного UCS-2 кодировкой (символы юникода, т.е. на любом языке):
UDHL
1 байт
Длина блока UDH в байтах
UDH
n байт
Непосредственно UDH-данные
text
m байт
непосредственно символы в кодировке UCS-2
Пояснение: Здесь все гораздо проще – поскольку 7-битного сжатия нет, не нужно извращаться с выравниванием текста по границам байта. Главное не забывать, что в UCS-2 один символ кодируется двумя байтами.
Теперь рассмотрим, из чего состоит блок UDH из вышеуказанных табличек. А состоит он из идентификатора, длины и одного или нескольких информационных элементов (IE):
IEI
1 байт
Идентификатор информационного элемента
IEDL
1 байт
Длина данных информационного элемента
IED
n байт
Данные информационного элемента
Вот картинка, дающая наглядное представление:
Как я уже говорил, UDH–поле предназначено не только для отправки длинных сообщений. Однако нам оно нужно только для этого, посему упрощаем задачу и рассмотрим информационные элементы именно с точки зрения длинных сообщений. Итак, для отправки длинных сообщений поле UDH будет содержать всего один информационный элемент и выглядеть так:
IEI
0х00 или 0х08
Для отправки длинных сообщений всегда равен либо 0х00, либо 0х08. Если 0х00 – то IED1 занимает 1 байт, если 0х08 – то IED1 занимает 2 байта.
IEDL
0х03 или 0х04
Длина данных информационного элемента – 3 или 4 байта, в зависимости от длины поля IED1
IED1
1 или 2 байта
Номер-ссылка. Должен быть одинаков для всех частей сообщения
IED2
1 байт
Количество частей в сообщении
IED3
1 байт
Порядковый номер части сообщения
Проясним вышесказанное. Итак, у нас есть длинное сообщение. Допустим, разбиваем его на 3 коротких. Тогда IED2 будет равно “03”. Первое сообщение будет иметь IED3 равное “01”, второе “02” и третье, соответственно, “03”.
Теперь о IED1: этот номер-ссылка (reference number) нужен для того, чтобы телефон при приеме наших трех коротких сообщений знал, что они принадлежат к одному и тому же большому. Для всех частей одного большого сообщения IED1 должен быть одинаковым! Например, вы посылаете на телефон длинное сообщение разбитое на 3 коротких, а в это же время кто-то еще посылает на этот же телефон длинное сообщение. Короткие сообщения приходят в телефон вперемешку, и для того, чтобы телефон в них не запутался как раз и применяется поле IED1. Оно будет разное у двух длинных сообщений, но одинаковое в пределах частей каждого из них. Таким образом телефон не перепутает кусочки. IED1 может быть абсолютно любым. Я применяю для его формирования датчик случайных чисел.
Еще один момент, связанный с полем IED1 – это его размерность. Она может быть либо 1 либо 2 байта. А зависит это от поля IEI: если IEI = “00”, то размерность IED1 1 байт, т.е. число от 0 до 255. Если IEI = “08”, то размерность IED1 2 байта, т.е. от 0 до 65535. Этот момент нам позже пригодится, из него получится отличная военная хитрость.
Ну и, соответственно, IEDL это длина данных, либо 3 байта (если IEI = “00”) либо 4 байта, (если IEI = “08”).
Таким образом, можно подсчитать длину IE-блока: она равна 5 байт, если reference number кодируется одним байтом, или 6 байт, если reference number кодируется двумя байтами.
Отсюда получается длина UDH-блока: что перед IE-блоком идет байт UDHL, указывающий его длину. Таким образом, полная длина блока UDH составит 6 или 7 байт соответственно.
3. Практика
Переходим к водным процедурам. А именно: будем отправлять длинное сообщение.
3.1 Для начала формируем весь заголовок PDU как обычно, только PDU-Type ставим не “01” а “41”. Не забываем и про TP-MR – просто увеличиваем его на единичку для каждого следующего сообщения.
3.2 Разбиваем длинное сообщение на короткие. Здесь надо определить количество символов, которые можно отправить коротким сообщением. Вариантов тут всего два: либо наше сообщение в ASCII-кодировке, либо в USC-2. На текст сообщения отводится всего 140 байт. Соответственно, в ASCII кодировке мы можем отправить всего 160 символов (за счет 7-битной кодировки), а в USC-2 всего 70.
Однако, следует учесть, что блок UDH располагается именно вначале тех 140 байт, которые отведены для текста сообщения, поэтому, на текст остается уже не 160 и 70 символов а меньше. А сколько именно – будем считать:
Сначала вспомним, что полная длина UDH-блока может быть 6 или 7 байт. Далее:
Для ASCII-сообщения: 7-битное кодирование позволяет упаковать 8 символов в 7 байт, отсюда и получается упомянутая мной выше военная хитрость: мы возьмем UDH-блок равный 7 байтам. А следом пойдет кодированный текст. Это дает нам большой выигрыш: не нужно выравнивать текст по границе септета. И это же означает, что мы теряем 8 байт текста. Значит считаем: 160 – 8 = 152. Итого 152 символа на сообщение.
Для кодировки USC-2: Здесь у нас текст не сжатый, а наоборот: каждый символ текста кодируется двумя байтами. Если мы возьмем длину UDH равную 7 байтам, то получим 140-7=133. А 133 на 2 нацело не делится. Значит, берем длину UDH равную 6 байтам. Тогда все в шоколаде: 140-6=134, 134/2=67. Итого 67 символов на сообщение.
3.3 Теперь мы знаем необходимое количество сообщений. Формируем блок UDH для каждого сообщения в отдельности, в зависимости от типа текста и от количества сообщений:
Для ASCII-сообщения: “06” (длина поля UDH) + “08” (IEI) + ”04” (IEDL) + “XXXX” (reference number, случайное двухбайтовое шестнадцатеричное число) + “ХХ” (IED2, Количество частей в сообщении) + “ХХ” (IED3, Порядковый номер сообщения)
Для кодировки USC-2: “05” (длина поля UDH) + “00” (IEI) + ”03” (IEDL) + “XX” (reference number, случайное однобайтовое шестнадцатеричное число) + “ХХ” (IED2, Количество частей в сообщении) + “ХХ” (IED3, Порядковый номер сообщения)
3.4 Все. Компонуем все вместе, отправляем все сообщения и наслаждаемся жизнью. Если все сделано правильно – сообщение склеится как положено.
Пример 1. Сообщение в кодировке USC-2
Будем отправлять сообщение “ Ночь. Улица. Фонарь. Аптека. Я покупаю вазелин. За мной стоят два человека: армян и сумрачный грузин. Вот скрипнула в подъезд пружина и повторилось все как встарь: пустая банка вазелина, аптека, улица, фонарь. ” на номер 0(000)000-00-00
Сообщение длинное, 209 символов, что дает при разбивке 4 коротких SMS(209/67). Смотрим внимательно:
050003FF0401 – UDH: 05 – общая длина UDH, 0003 – идентификатор и длина IE, FF – случайный reference number, 04 – всего 4 сообщения, 01 – это первое сообщение
050003FF0402 – UDH: 05 – общая длина UDH, 0003 – идентификатор и длина IE, FF – случайный reference number, 04 – всего 4 сообщения, 02 – это второе сообщение
050003FF0403 – UDH: 05 – общая длина UDH, 0003 – идентификатор и длина IE, FF – случайный reference number, 04 – всего 4 сообщения, 03 – это третье сообщение
050003FF0404 – UDH: 05 – общая длина UDH, 0003 – идентификатор и длина поля данных, FF – случайный reference number, 04 – всего 4 сообщения, 04 – это четвертое сообщение
Итак, что мы тут видим?
PDU-Type везде 41, т.к. это составное сообщение.
TP-MR просто увеличивается на единичку, ну это я так сделал, главное, чтобы они не совпадали.
TP-UDL – Длину я выделил просто так, на всякий случай.
UDH начинается для всех одинаково: 05 — общая длина UDH, 00 – идентификатор IE, 03 – длина IE-данных, FF – reference number, случайное число, одинаковое для всех коротких сообщений, составляющих одно длинное (у меня случайно получилось FF), 04 – всего 4 сообщения и дальше – для каждого сообщения свой порядковый номер. Все просто, не так ли?
Пример 2: Сообщение в кодировке ASCII
Отправляем то же сообщение, но в транслите: “ Noch’. Ulica. Fonar’. Apteka. Ja pokupaju vazelin. Za mnoj stojat dva cheloveka: armjan i sumrachnyj gruzin. Vot skripnula v pod#ezd pruzhina i povtorilos’ vse kak vstar’: pustaja banka vazelina, apteka, ulica, fonar’. ”
060804BD010201 – UDH: 06 – общая длина UDH, 0804 – идентификатор и длина IE, BD01 – случайный reference number, 02 – всего 2 сообщения, 01 – это первое сообщение
060804BD010202 – UDH: 06 – общая длина UDH, 0804 – идентификатор и длина IE, BD01 – случайный reference number, 02 – всего 2 сообщения, 02 – это второе сообщение
Итак, что мы тут видим? Да все то же самое:
PDU-Type везде 41, т.к. это составное сообщение.
TP-MR просто увеличивается на единичку
TP-UDL – Длину я выделил просто так, на всякий случай.
UDH начинается для всех одинаково: 06 — общая длина UDH, 08 – идентификатор IE, 04 – длина IE-данных, BD01 – reference number, двухбайтовое случайное число, одинаковое для всех коротких сообщений, составляющих одно длинное, 02 – всего 2 сообщения и дальше – для каждого сообщения свой порядковый номер.
Заключение
Вот собственно и все, что я хотел сказать, да и пиво кончилось :). На самом деле особо сложного тут нет ничего. Надеюсь кому-нибудь пригодится этот материал. Если будут вопросы – задавайте, отвечу.
Исходный код
Для тех, кто по каким-либо причинам не может разобраться с данной темой, я выложил исходные коды программы SMSSender. Там реализована отправка длинных сообщений, и код, формирующий PDU-текст достаточно понятно комментирован.
Ссылки
Если интересно, приведу несколько ссылок на источники, которыми я пользовался:
http://mobiletidings.com/2009/02/18/combining-sms-messages/ http://mobiletidings.com/2009/02/11/more-on-the-sms-pdu/ Send Long SMS/Multipart SMS/Concatenated SMS http://isms.ru/article.shtml?art_12
Благодарности
Special Thanx моему читателю ТимЫчу, который несколько месяцев назад пытался сподвигнуть меня на вникание в данный вопрос и даже высылал мне ссылки на некоторые статьи. К сожалению время мне тогда не позволяло заняться этим вопросом, а его ссылки я потерял в груде ежедневной корреспонденции. Но мысль во мне он зародил правильную, и, как только появилось время, я эту мысль реализовал.