Парсинг любого сайта «для чайников»: ни строчки программного кода
Разбираем тонкости парсинга данных в Screaming Frog Seo Spider
Если вам нужно просто собрать с сайта мета-данные, можно воспользоваться бесплатным парсером системы Promopult. Но бывает, что надо копать гораздо глубже и добывать больше данных, и тут уже без сложных (и небесплатных) инструментов не обойтись.
Евгений Костин рассказал о том, как спарсить любой сайт, даже если вы совсем не дружите с программированием. Разбор сделан на примере Screaming Frog Seo Spider.
Что такое парсинг и зачем он вообще нужен
Парсинг нужен, чтобы получить с сайтов некую информацию. Например, собрать данные о ценах с сайтов конкурентов.
Одно из применений парсинга — наполнение каталога новыми товарами на основе уже существующих сайтов в интернете.
Что такое парсинг
Упрощенно, парсинг — это сбор информации. Есть более сложные определения, но так как мы говорим о парсинге «для чайников», то нет никакого смысла усложнять терминологию. Парсинг — это сбор, как правило, структурированной информации. Чаще всего — в виде таблицы с конкретным набором данных. Например, данных по характеристикам товаров.
Парсер — программа, которая осуществляет этот самый сбор. Она ходит по ссылкам на страницы, которые вы указали, и собирает нужную информацию в Excel-файл либо куда-то еще.
Парсинг работает на основе XPath-запросов. XPath — язык запросов, который обращается к определенному участку кода страницы и собирает из него заданную информацию.
ПО для парсинга
Здесь есть важный момент. Если вы введете в поисковике слово «парсинг» или «заказать парсинг», то, как правило, вам будут предлагаться некие услуги от компаний, они стоят относительно дорого и называется это так: «мы напишем вам парсер». То есть «мы создадим некую программу либо на Python, либо на каком-то еще языке, которая будет собирать эту информацию с нужного вам сайта». Эта программа нацелена только на сбор конкретных данных, она не гибкая и без знаний программирования вы не сможете ее самостоятельно перенастроить для других задач.
При этом есть готовые решения, которые можно под себя настраивать как угодно и собирать что угодно. Более того, если вы — SEO-специалист, возможно, одной из этих программ пользуетесь, но просто не знаете, что в ней такой функционал есть. Либо знаете, но никогда не применяли, либо применяли не в полной мере.
Вот две программы, которые являются аналогами.
Screaming Frog SEO Spider (есть только годовая лицензия).
Netpeak Spider (есть триал на 14 дней, лицензии на месяц и более).
Эти программы занимаются сбором информации с сайта. То есть они анализируют, например, его заголовки, какие-то коды, теги и все-все остальное. Помимо прочего, они позволяют собрать те данные, которые вы им зададите.
Профессиональные инструменты PromoPult: быстрее, чем руками, дешевле, чем у других, бесплатные опции.
Съем позиций, кластеризация запросов, парсер Wordstat, сбор поисковых подсказок, сбор фраз ассоциаций, парсер мета-тегов и заголовков, анализ индексации страниц, чек-лист оптимизации видео, генератор из YML, парсер ИКС Яндекса, нормализатор и комбинатор фраз, парсер сообществ и пользователей ВКонтакте.
Давайте смотреть на реальных примерах.
Пример 1. Как спарсить цену
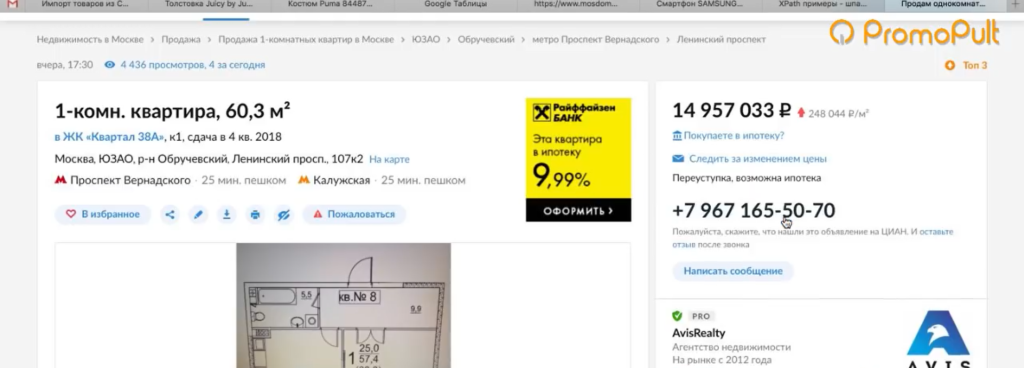
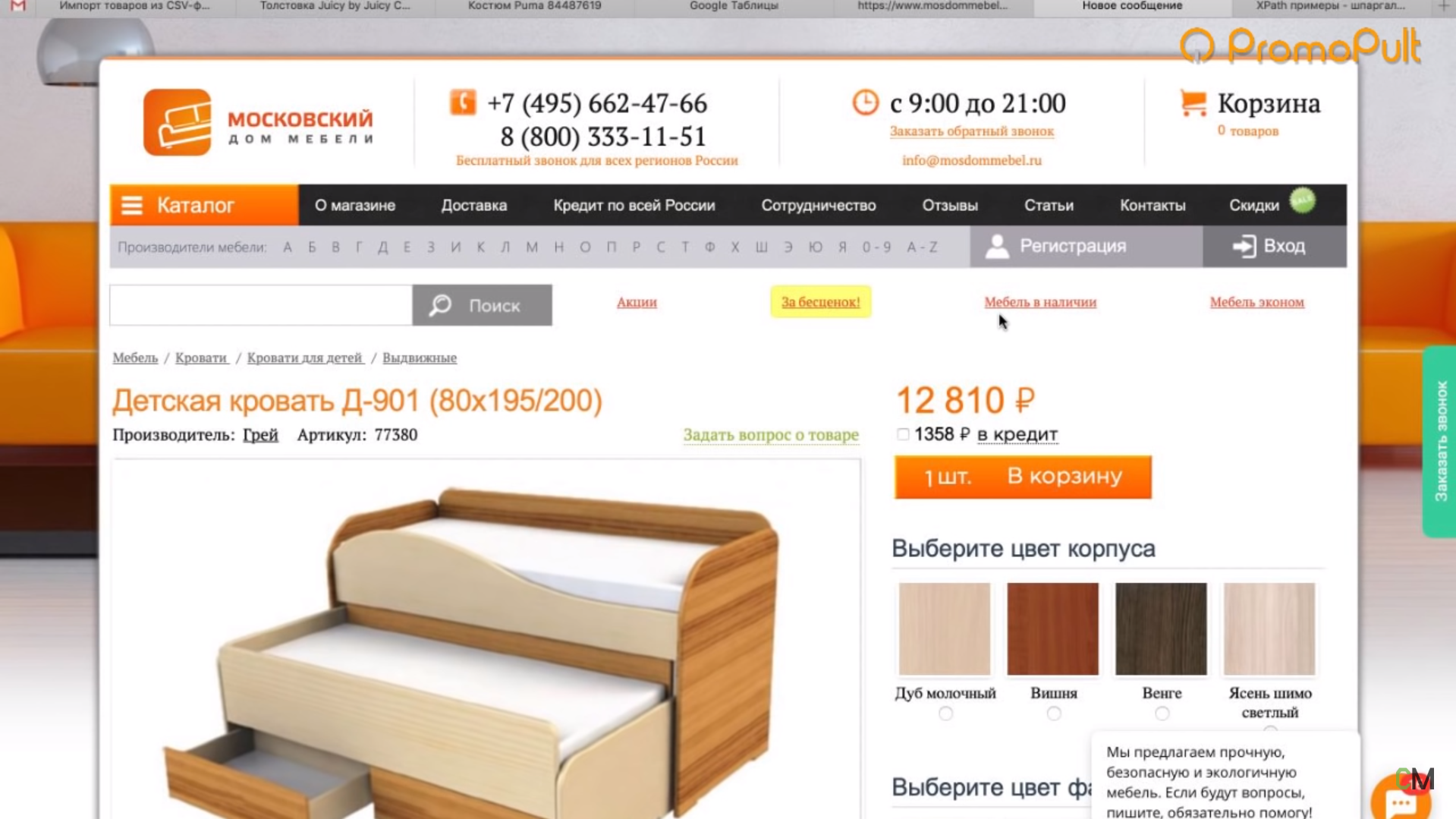
Предположим, вы хотите с некого сайта собрать все цены товаров. Это ваш конкурент, и вы хотите узнать — сколько у него стоят товары.
Возьмем для примера сайт mosdommebel.ru.
Вот у нас есть страница карточки товара, есть название и есть цена этого товара. Как нам собрать эту цену и цены всех остальных товаров?
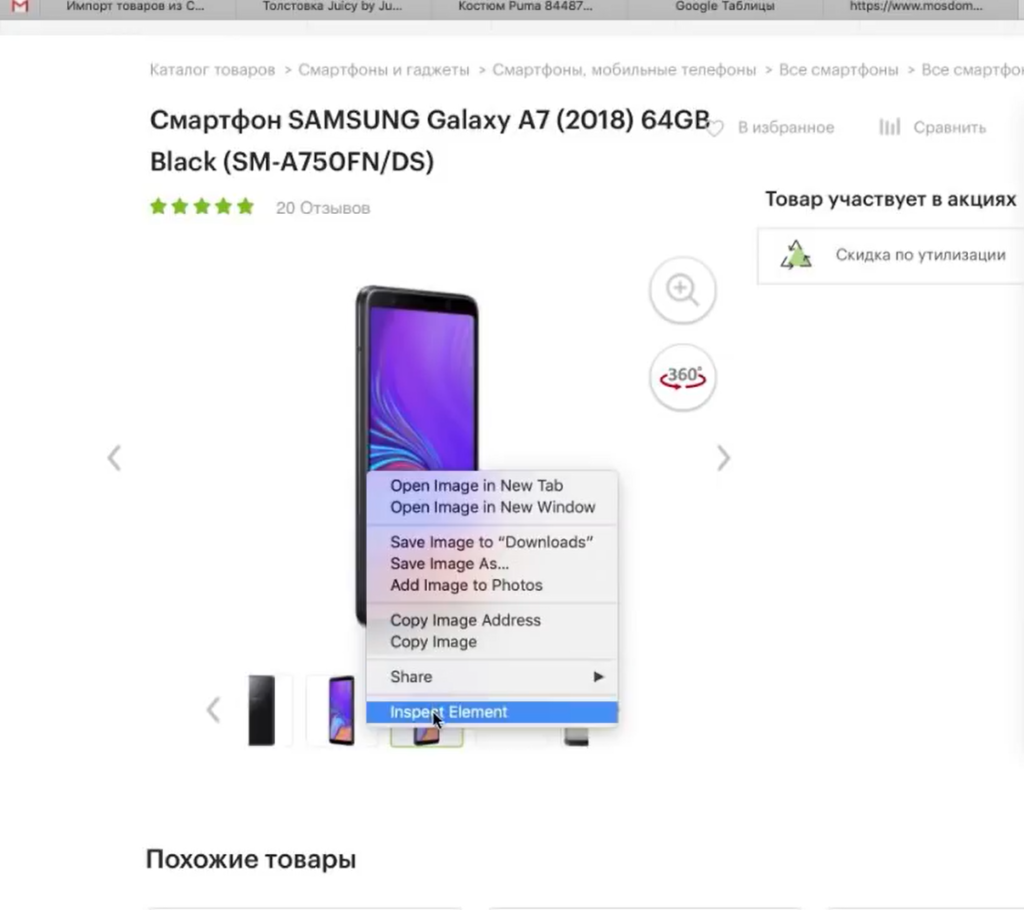
Мы видим, что цена отображается вверху справа, напротив заголовка H1. Теперь нам нужно посмотреть, как эта цена отображается в html-коде.
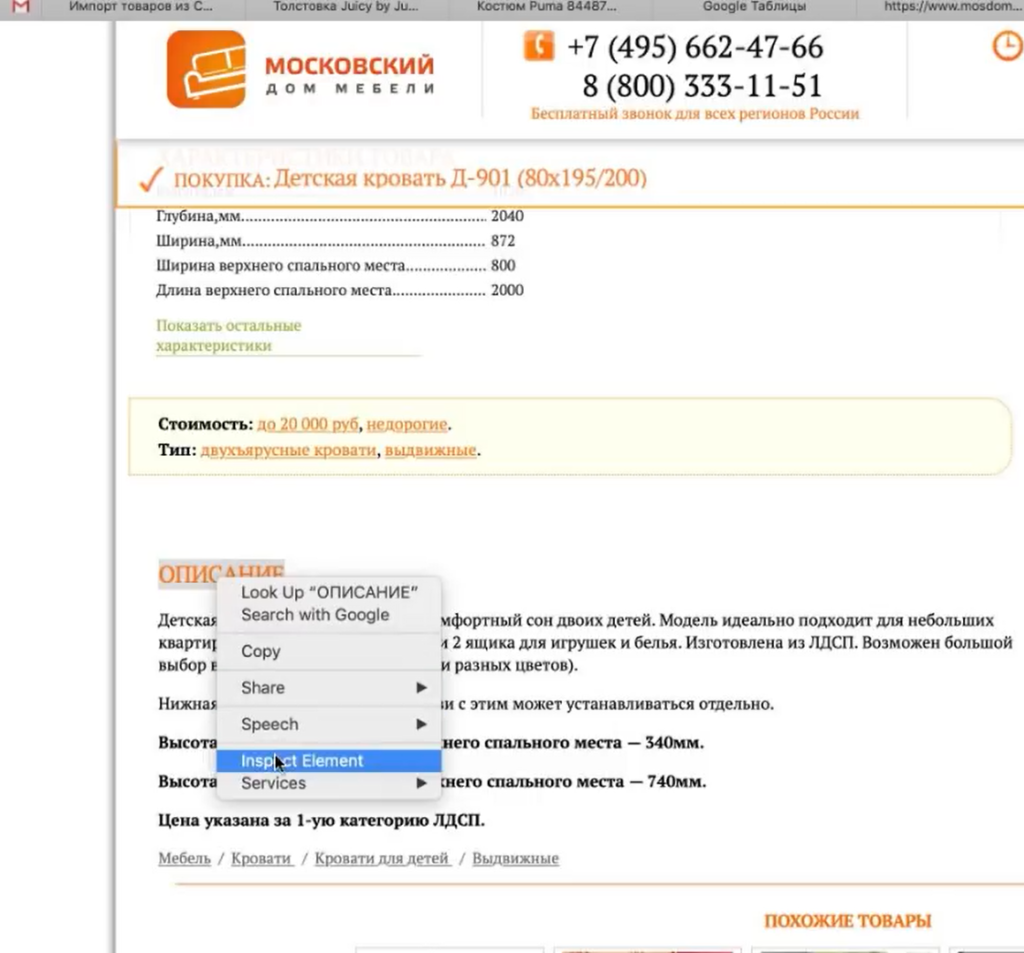
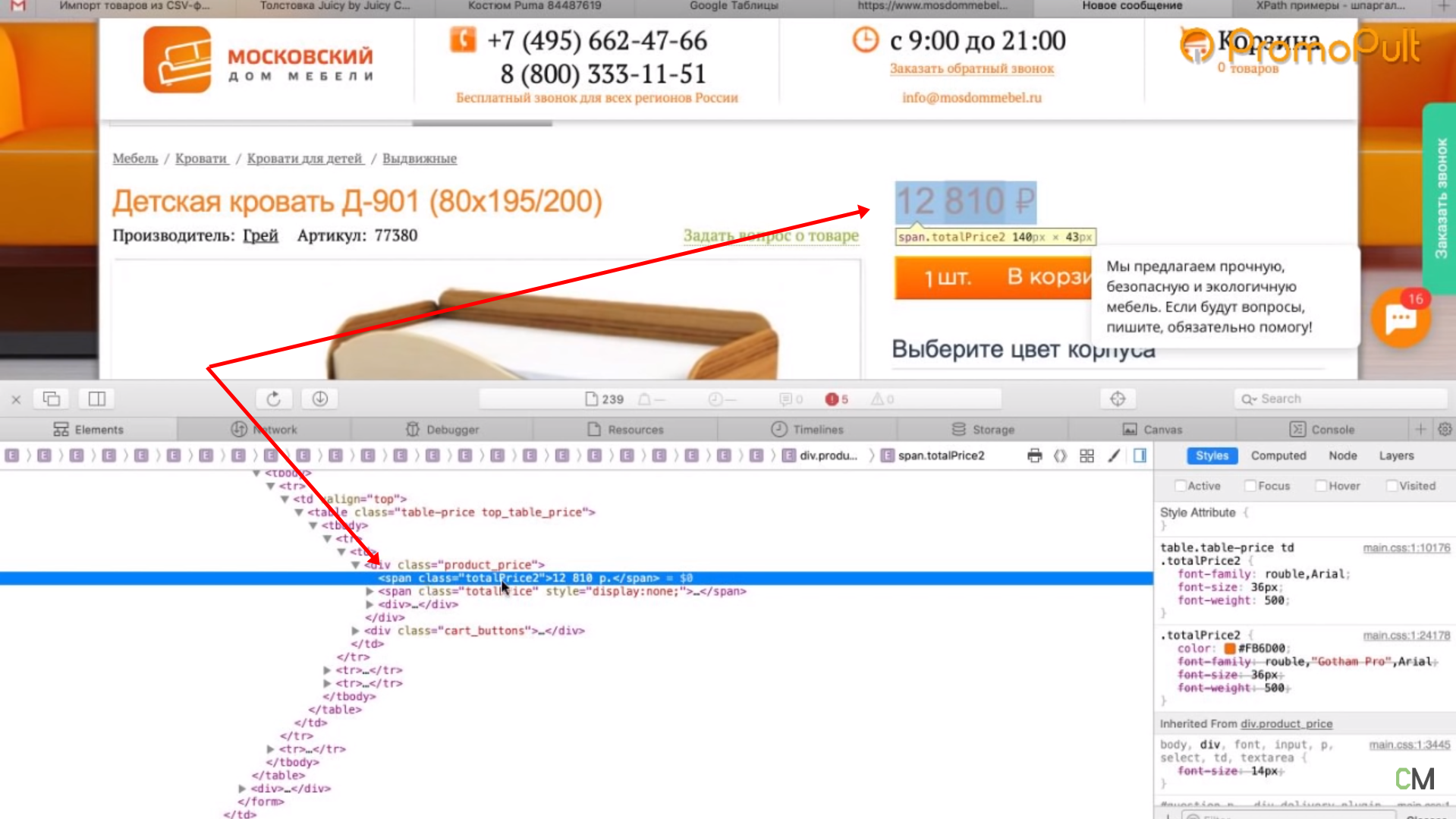
Нажимаем правой кнопкой мыши прямо на цену (не просто на какой-то фон или пустой участок). Затем выбираем пункт Inspect Element для того, чтобы в коде сразу его определить (Исследовать элемент или Просмотреть код элемента, в зависимости от браузера — прим. ред.).
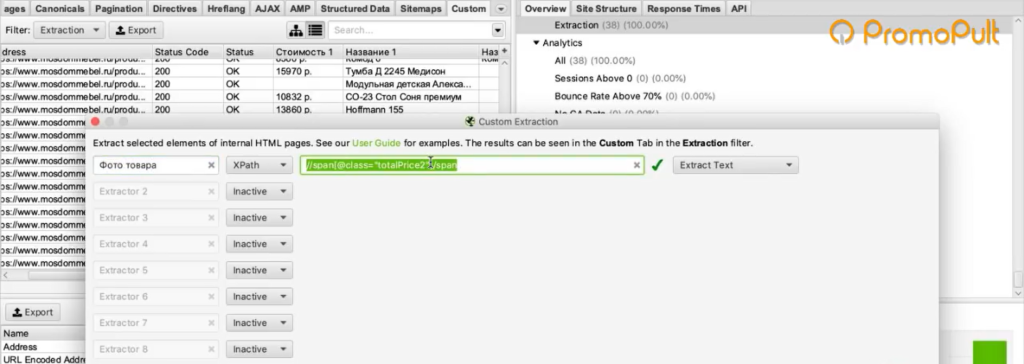
Мы видим, что цена у нас помещается в тег с классом totalPrice2. Так разработчик обозначил в коде стоимость данного товара, которая отображается в карточке. Фиксируем: есть некий элемент span с классом totalPrice2. Пока это держим в голове.
Есть два варианта работы с парсерами.
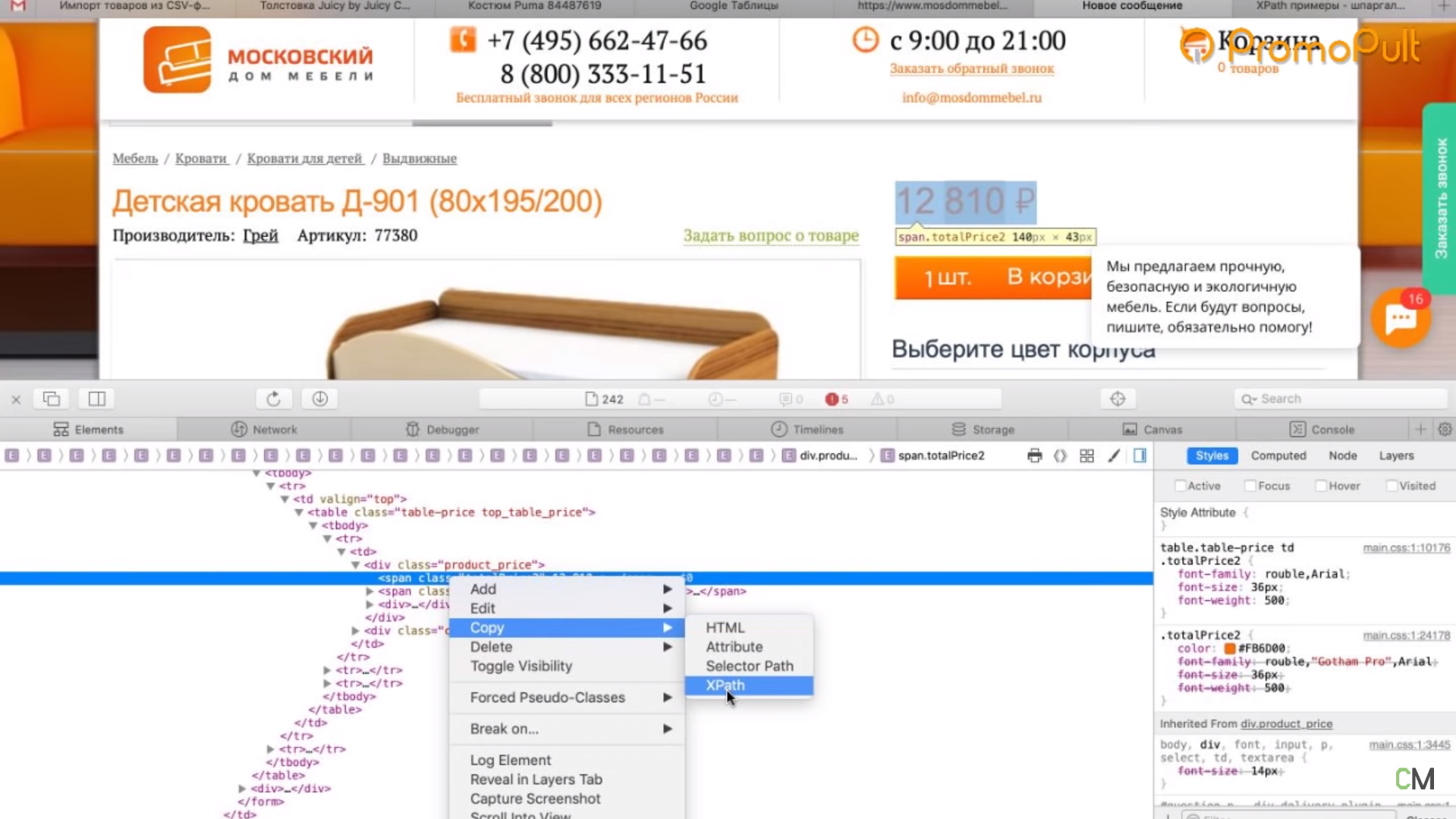
Первый способ. Вы можете прямо в коде (любой браузер) нажать правой кнопкой мыши на тег и выбрать Скопировать > XPath. У вас таким образом скопируется строка, которая обращается к данному участку кода.
Но этот вариант не очень надежен: если у вас в другой карточке товара верстка выглядит немного иначе (например, нет каких-то блоков или блоки расположены по-другому), то такой метод обращения может ни к чему не привести. И нужная информация не соберется.
Поэтому мы будем использовать второй способ. Есть специальные справки по языку XPath. Их очень много, можно просто загуглить «XPath примеры».
Здесь указано как что-то получить. Например, если мы хотим получить содержимое заголовка h1, нам нужно написать вот так:
Если мы хотим получить текст заголовка с классом productName, мы должны написать вот так:
То есть поставить «//» как обращение к некому элементу на странице, написать тег h1 и указать в квадратных скобках через символ @ «класс равен такому-то».
То есть не копировать что-то, не собирать информацию откуда-то из кода. А написать строку запроса, который обращается к нужному элементу. Куда ее написать — сейчас мы разберемся.
Куда вписывать XPath-запрос?
Мы идем в один из парсеров. В данном случае я воспользуюсь программой Screaming Frog Seo Spider.
Она бесплатна для анализа небольшого сайта — до 500 страниц.
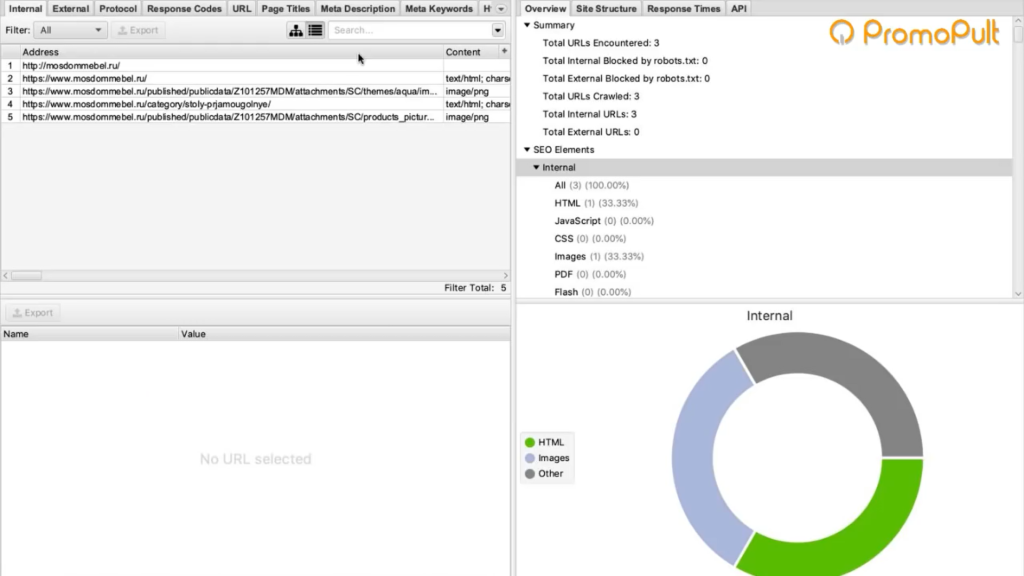
Интерфейс Screaming Frog Seo Spider
Например, мы можем — бесплатно — посмотреть заголовки страниц, проверить нет ли у нас каких-нибудь пустых тайтлов или дубликатов тега H1, незаполненных мета-тегов или каких-нибудь битых ссылок.
Но за функционал для парсинга в любом случае придется платить, он доступен только в платной версии.
Предположим, вы оплатили годовую лицензию и получили доступ к полному набору функций сервиса. Если вы серьезно занимаетесь анализом данных и регулярно нуждаетесь в функционале сервиса — это разумная трата денег.
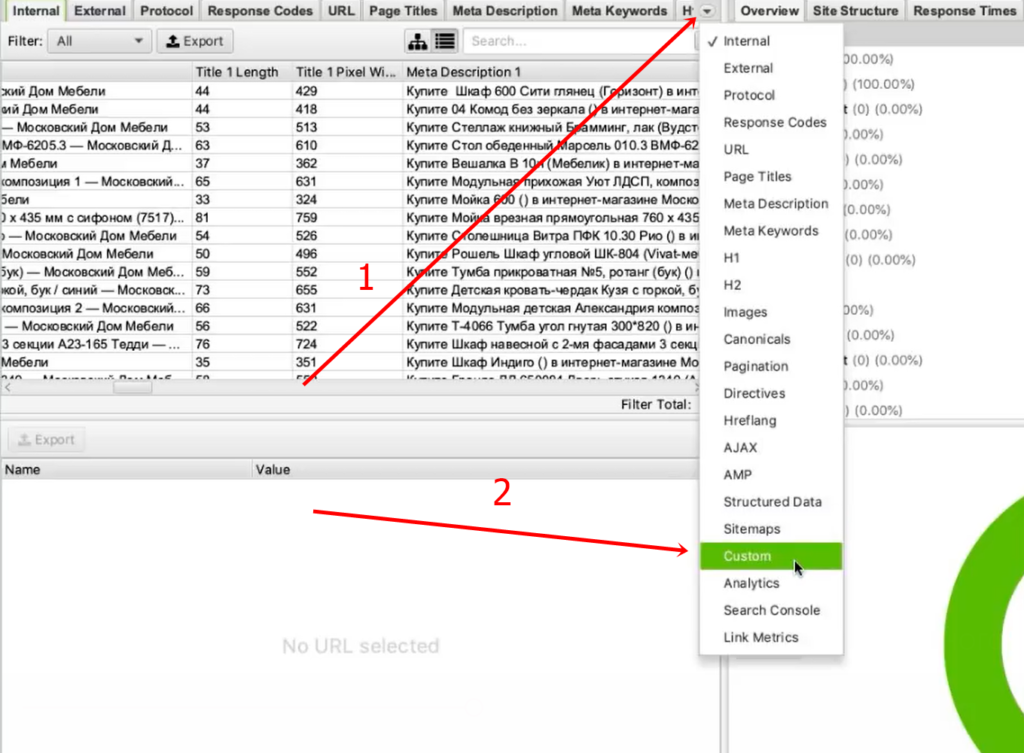
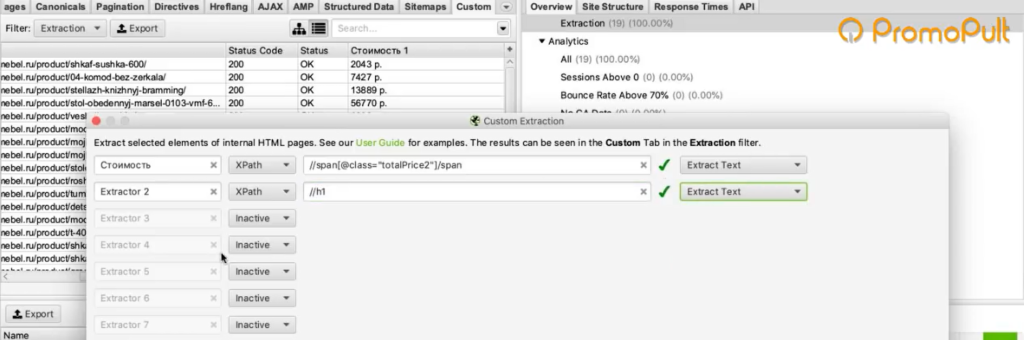
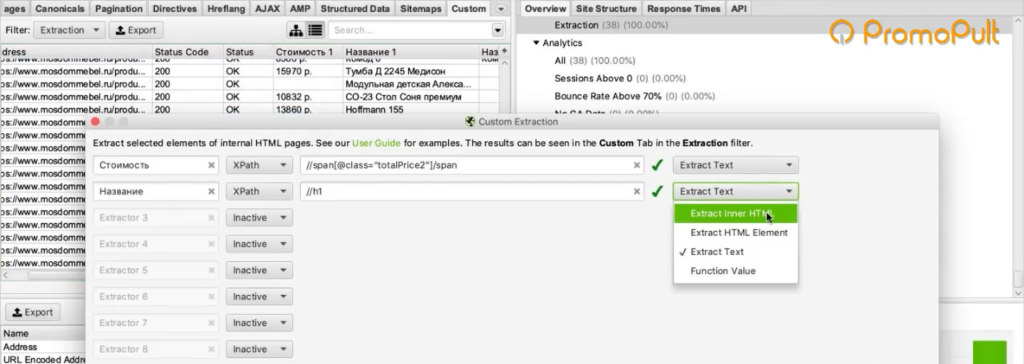
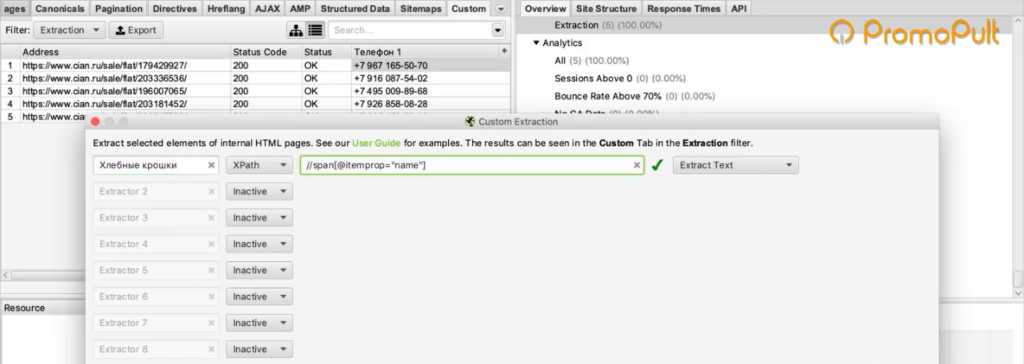
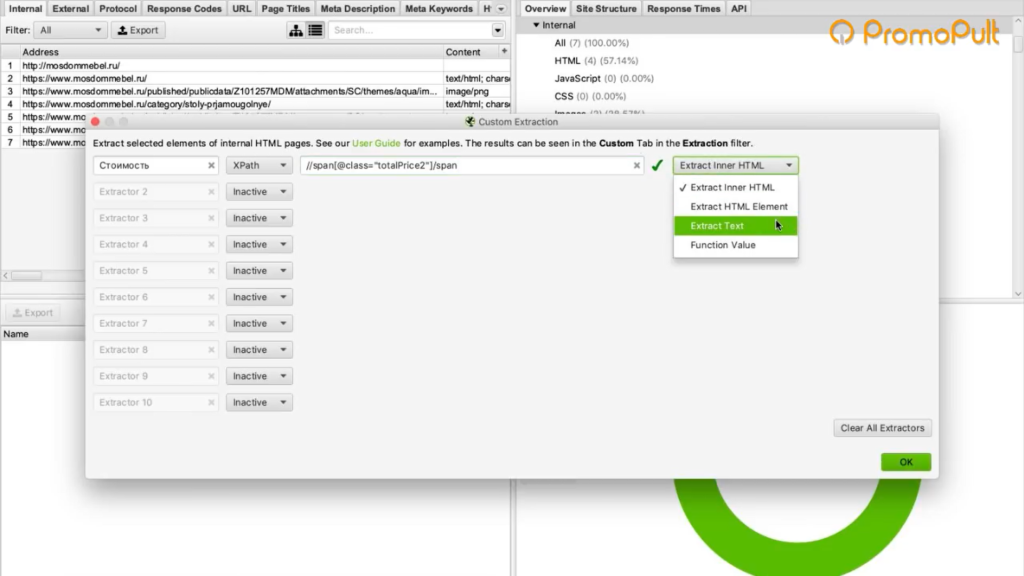
Во вкладке меню Configuration у нас есть подпункт Custom, и в нем есть еще один подпункт Extraction. Здесь мы можем дополнительно что-то поискать на тех страницах, которые мы укажем.
Заходим в Extraction. И напоминаю, что мы хотели с сайта (в данном случае с сайта Московский дом мебели) собрать цены товаров.
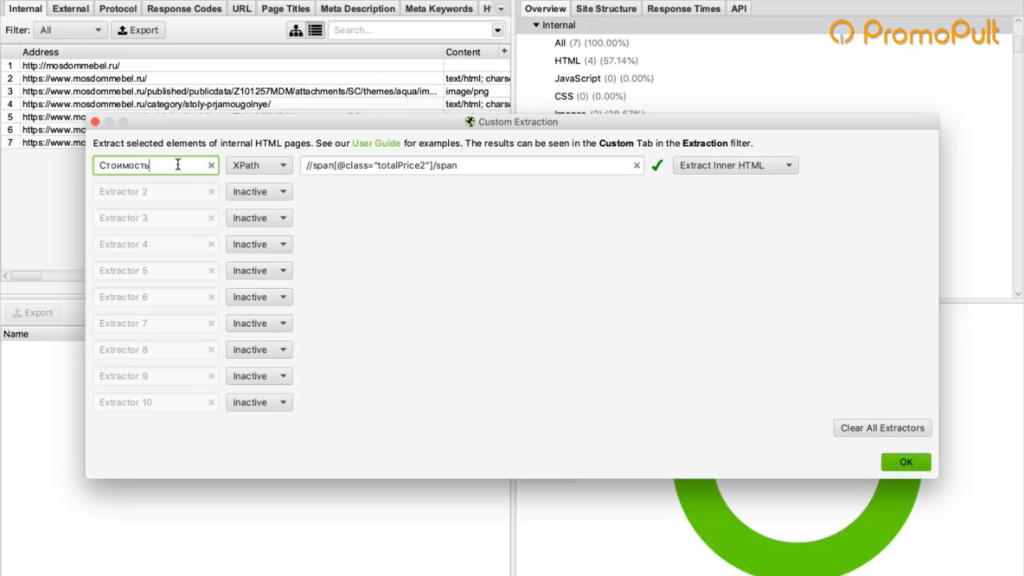
Мы выяснили в коде, что у нас все цены на карточках товара обозначаются тегом с классом totalPrice2. Формируем вот такой XPath запрос:
И указываем его в разделе Configuration > Custom > Extractions. Для удобства можем еще назвать как-нибудь колонку, которая у нас будет выгружаться. Например, «стоимость»:
Таким образом мы будем обращаться к коду страниц и из этого кода вытаскивать содержимое стоимости.
Также в настройках мы можем указать, что парсер будет собирать: весь html-код или только текст. Нам нужен только текст, без разметки, стилей и других элементов.
Нажимаем ОК. Мы задали кастомные параметры парсинга.
Как подобрать страницы для парсинга
Дальше есть еще один важный этап. Это, собственно, подбор страниц, по которым будет осуществляться парсинг.
Если мы просто укажем адрес сайта в Screaming Frog, парсер пойдет по всем страницам сайта. На инфостраницах и страницах категорий у нас нет цен, а нам нужны именно цены, которые указаны на карточках товара. Чтобы не тратить время, лучше загрузить в парсер конкретный список страниц, по которым мы будем ходить, — карточки товаров.
Как правило, на любом сайте есть карта сайта XML, и находится она чаще всего по адресу: «адрес сайта/sitemap.xml». В случае с сайтом из нашего примера — это адрес
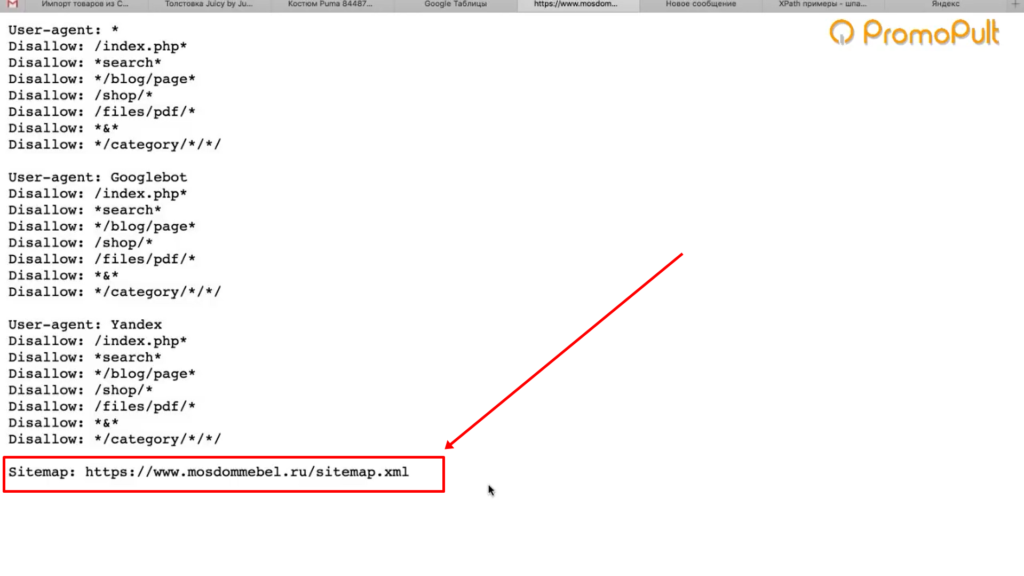
Либо вы можете зайти в robots.txt (site.ru/robots.txt) и посмотреть. Чаще всего в этом файле внизу содержится ссылка на карту сайта.
Ссылка на карту сайта в файле robots.txt
Даже если карта называется как-то странно, необычно, нестандартно, вы все равно увидите здесь ссылку.
Но если не увидите — если карты сайта нет — то нет никакого решения для отбора карточек товара. Тогда придется запускать стандартный режим в парсере — он будет ходить вообще по всему сайту, по всем разделам. Но нужную вам информацию соберет только на карточках товара. Минус здесь в том, что вы потратите больше времени и дольше придется ждать нужных данных.
У нас карта сайта есть, поэтому мы переходим по ссылке https://www.mosdommebel.ru/sitemap.xml и видим, что сама карта разделяется на несколько карт. Отдельная карта по статичным страницам, по категориям, по продуктам (карточкам товаров), по статьям и новостям.
Ссылки на отдельные sitemap-файлы под все типы страниц
Нас интересует карта продуктов, то есть карточек товаров.
Ссылка на sitemap-файл для карточек товара
Что с этим делать дальше. Возвращаемся в Screaming Frog Seo Spider. Сейчас он запущен у нас в стандартном режиме, в режиме Spider (паук), который ходит по всему сайту и анализирует все-все страницы. Нам нужно его запустить в режиме List.
Мы загрузим ему конкретный список страниц, по которому он будет ходить. Нажимаем на вкладку Mode и выбираем List.
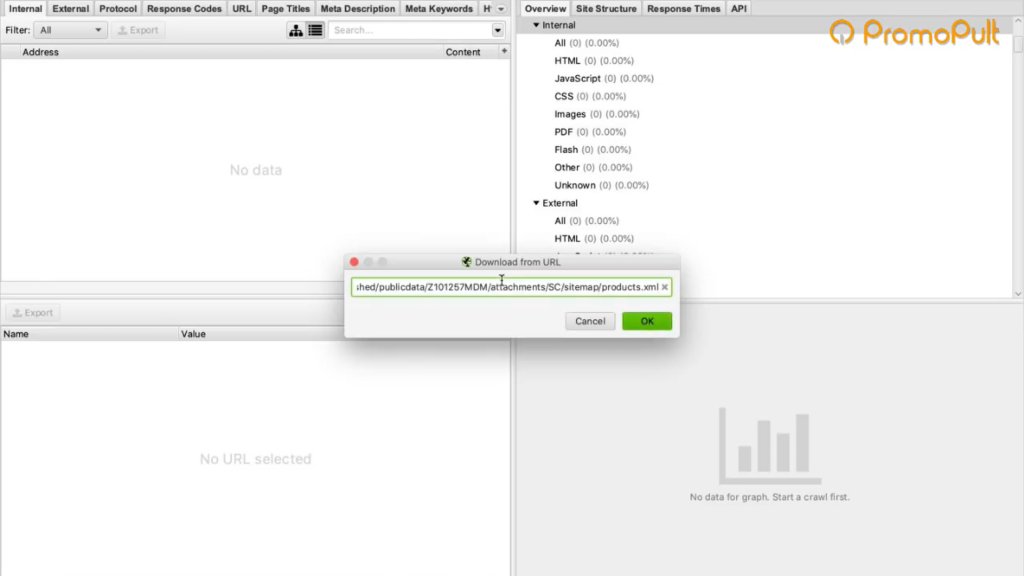
Жмем кнопку Upload и кликаем по Download Sitemap.
Указываем ссылку на Sitemap карточек товара, нажимаем ОК.
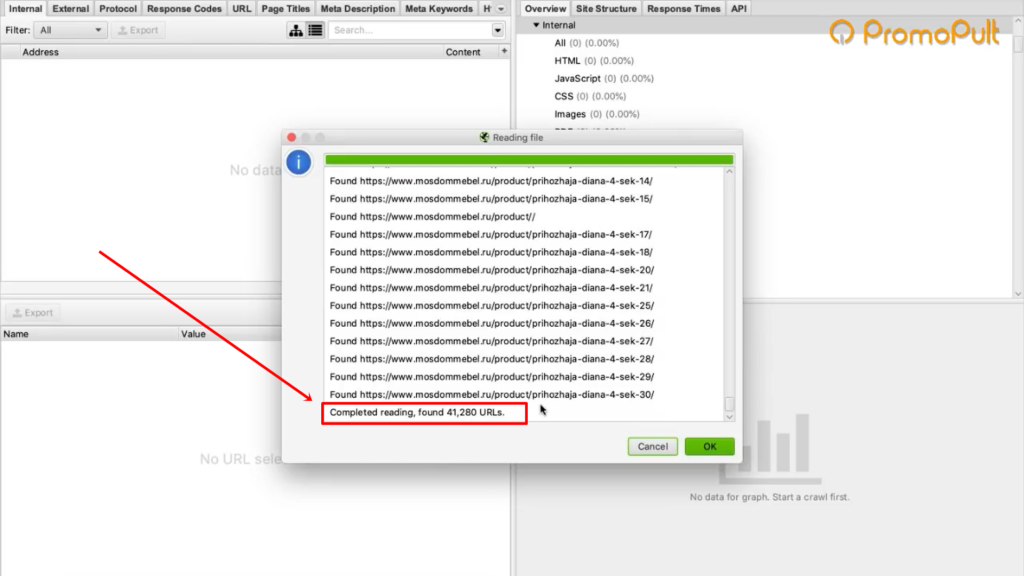
Программа скачает все ссылки, указанные в карте сайта. В нашем случае Screaming Frog обнаружил более 40 тысяч ссылок на карточки товаров:
Нажимаем ОК и у нас начинается парсинг сайта.
После завершения парсинга на первой вкладке Internal мы можем посмотреть информацию по всем характеристикам: код ответа, индексируется/не индексируется, title страницы, description и все остальное.
Это все полезная информация, но мы шли за другим.
Вернемся к исходной задаче — посмотреть стоимость товаров. Для этого в интерфейсе Screaming Frog нам нужно перейти на вкладку Custom. Чтобы попасть на нее, нужно нажать на стрелочку, которая находится справа от всех вкладок. Из выпадающего списка выбрать пункт Custom.
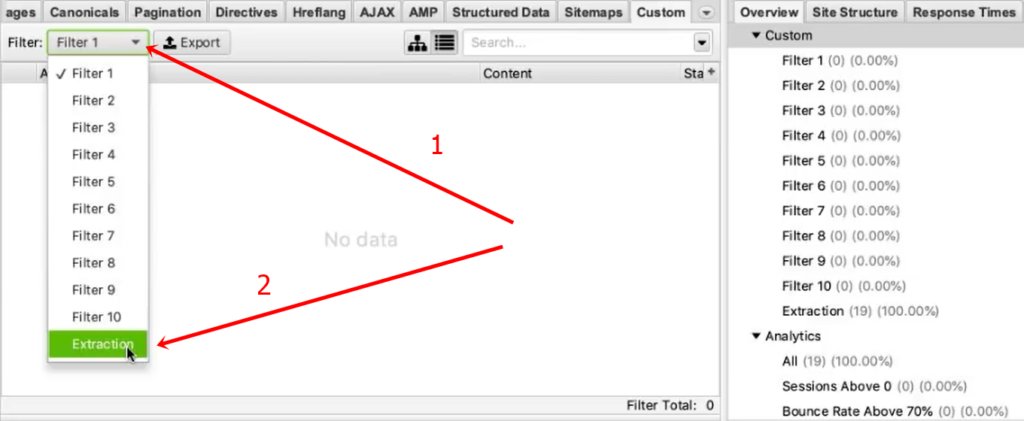
И на этой вкладке из выпадающего списка фильтров (Filter) выберите Extraction.
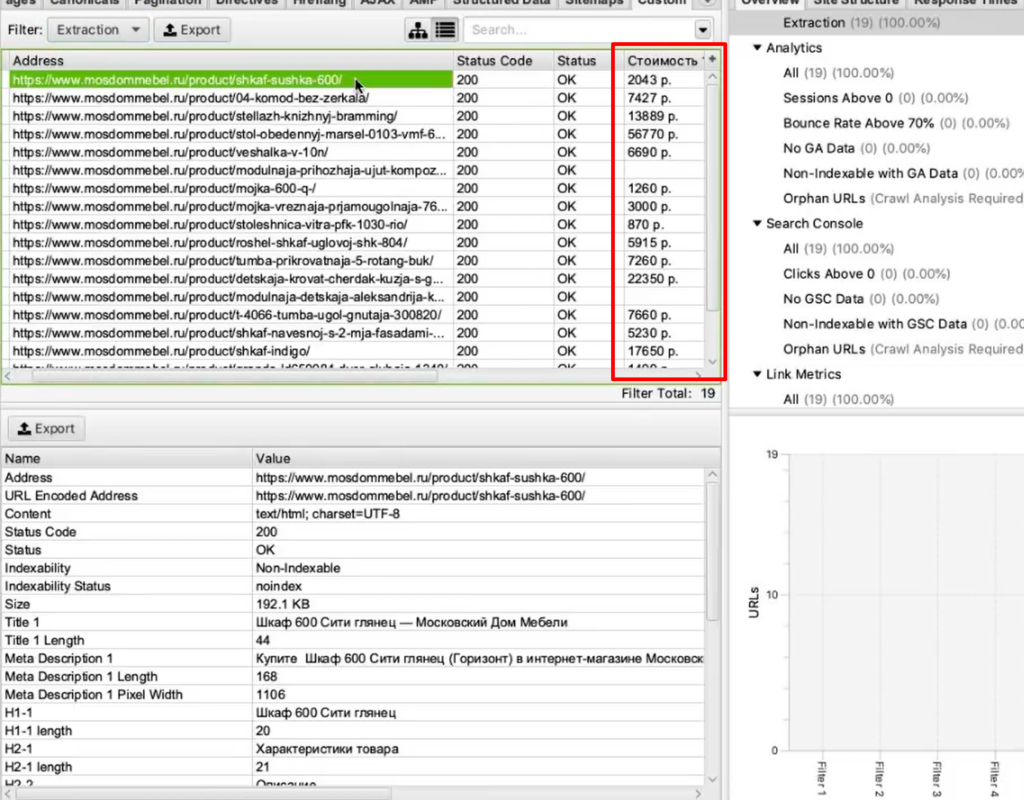
Вы как раз и получите ту самую информацию, которую хотели собрать: список страниц и колонка «Стоимость 1» с ценами в рублях.
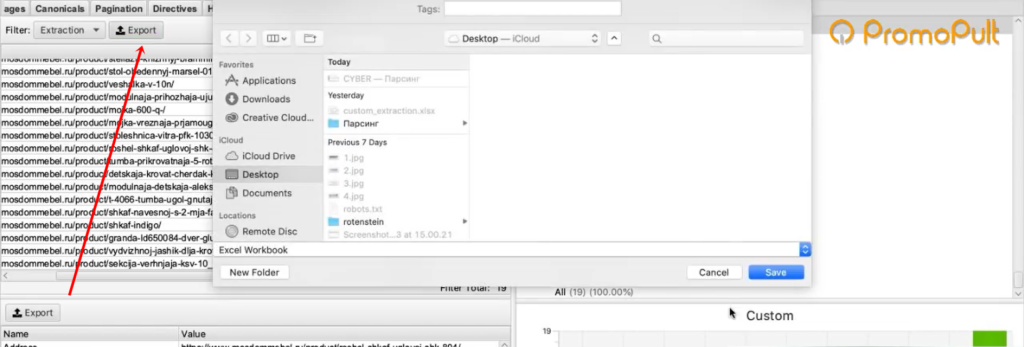
Задача выполнена, теперь все это можно выгрузить в xlsx или csv-файл.
После выгрузки стандартной заменой вы можете убрать букву «р», которая обозначает рубли. Просто, чтобы у вас были цены в чистом виде, без всяких там пробелов, буквы «р» и прочего.
Таким образом, вы получили информацию по стоимости товаров у сайта-конкурента.
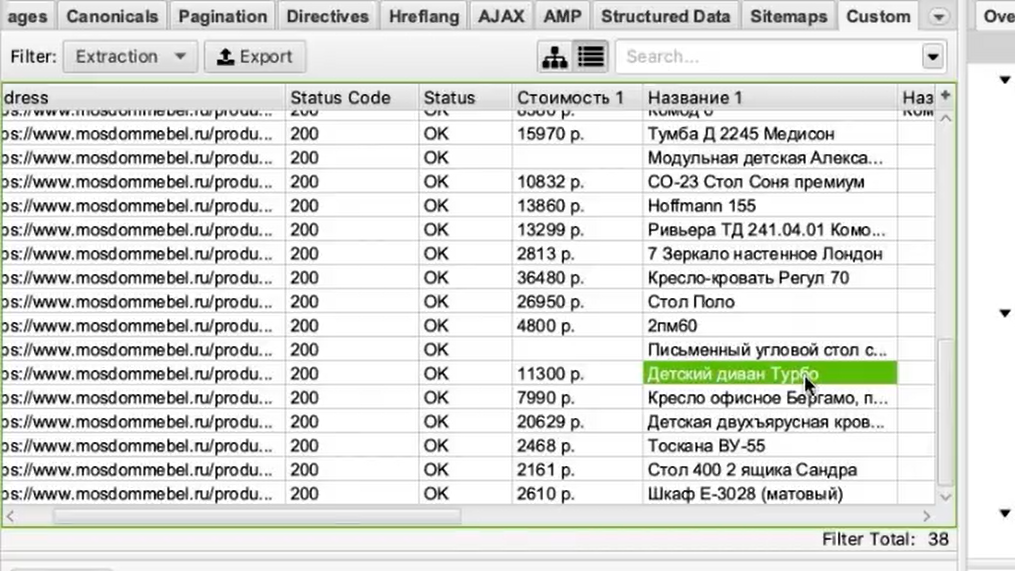
Если бы мы хотели получить что-нибудь еще, например дополнительно еще собрать названия этих товаров, то нам нужно было бы зайти снова в Configuration > Custom > Extraction. И выбрать после этого еще один XPath-запрос и указать, например, что мы хотим собрать тег
Просто запустив еще раз парсинг, мы собираем уже не только стоимость, но и названия товаров.
Вот у нас теперь связка такая: url товара, его стоимость и название этого товара.
Если мы хотим получить описание или что-то еще — продолжаем в том же духе. Единственное, что нужно всегда помнить, что H1 собрать легко. Это стандартный элемент html-кода и для его парсинга можно использовать стандартный XPath-запрос (посмотрите в справке). В случае же с описанием или другими элементами нам нужно всегда возвращаться в код страницы и смотреть: как называется сам тег, какой у него класс/id либо какие-то другие атрибуты, к которым мы можем обратиться с помощью XPath-запроса.
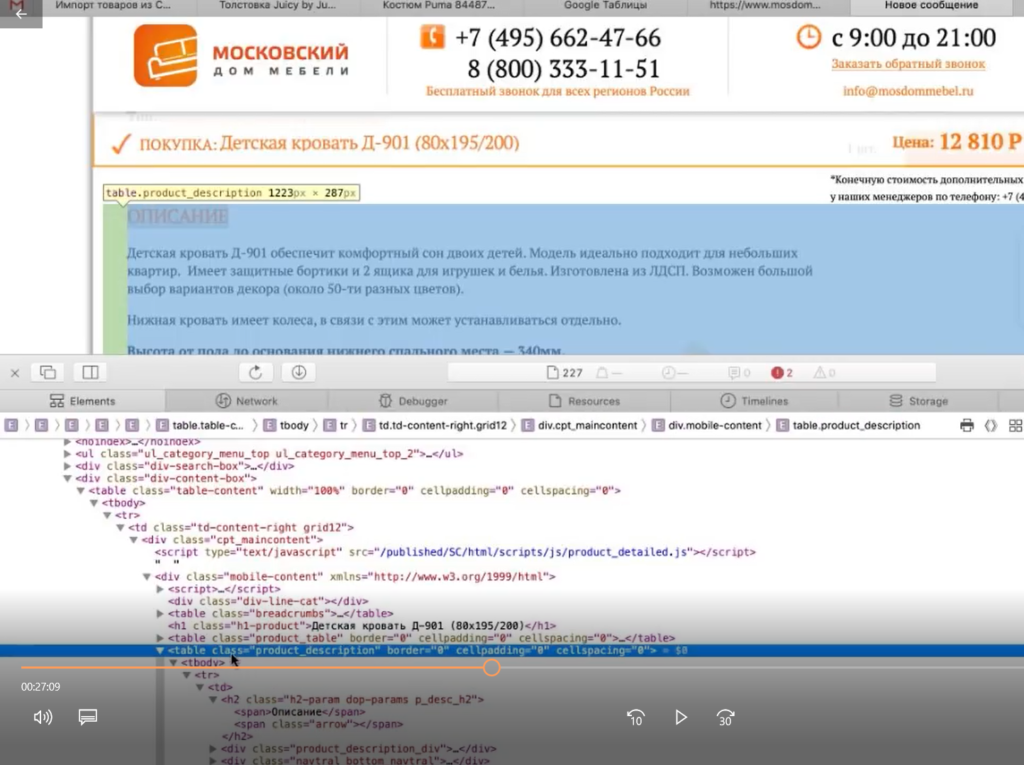
Например, мы хотим собрать описание. Нужно снова идти в Inspect Element.
Оказывается, все описание товара лежит в теге
с классом product_description. Если мы его соберем, то у нас в таблицу выгрузится полное описание.
Здесь есть нюанс. Текст описания на странице сайта сделан с разметкой. Например, здесь есть переносы на новую строчку, что-то выделяется жирным.
Если вам нужно спарсить текст описания с уже готовой разметкой, то в настройках Extraction в парсере мы можем выбрать парсинг с html-кодом.
Если вы не хотите собирать весь html-код (потому что он может содержать какие-то классы, которые к вашему сайту никакого отношения не имеют), а нужен текст в чистом виде, выбираем только текст. Но помните, что тогда переносы строк и все остальное придется заполнять вручную.
Собрав все необходимые элементы и прогнав по ним парсинг, вы получите таблицу с исчерпывающей информацией по товарам у конкурента.
Такой парсинг можно запускать регулярно (например, раз в неделю) для отслеживания цен конкурентов. И сравнивать, у кого что стоит дороже/дешевле.
Пример 2. Как спарсить фотографии
Рассмотрим вариант решения другой прикладной задачи — парсинга фотографий.
На сайте Эльдорадо у каждого товара есть довольно таки немало фотографий. Предположим, вы их хотите взять — это универсальные фото от производителя, которые можно использовать для демонстрации на своем сайте.
Задача: собрать в эксель адреса всех картинок, которые есть у разных карточек товара. Не в виде файлов, а в виде ссылок. Потом по ссылкам вы сможете их скачать либо напрямую загрузить на свой сайт. Большинство движков интернет-магазинов, таких как Битрикс и Shop-Script, поддерживают загрузку фотографий по ссылке. Если вы в CSV-файле, который используете для импорта-экспорта, укажете ссылки на фотографии, то по ним движок сможет загрузить эти самые фотографии.
Ищем свойства картинок
Для начала нам нужно понять, где в коде пишутся свойства, адрес фотографии на каждой карточке товара.
Нажимаем правой клавишей на фотографию, выбираем Inspect Element, начинаем исследовать.
Смотрим, в каком элементе и с каким классом у нас находится данное изображение, что оно из себя представляет, какая у него ссылка и т.д.
Изображения лежат в элементе , у которого id — firstFotoForma. Чтобы спарсить нужные нам картинки, понадобится вот такой XPath-запрос:
У нас здесь обращение к элементам с идентификатором firstFotoForma, дальше есть какие-то вложенные элементы (поэтому прописана звездочка), дальше тег img, из которого нужно получить содержимое атрибута src. То есть строку, в которой и прописан URL-адрес фотографии.
Давайте попробуем это сделать.
Берем XPath-запрос, в Screaming Frog переходим в Configuration > Custom > Extraction, вставляем и жмем ОК.
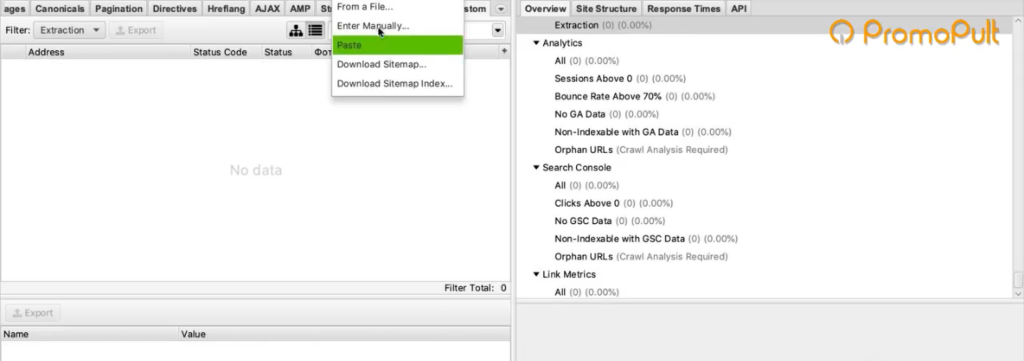
Для начала попробуем спарсить одну карточку. Нужно скопировать ее адрес и добавить в Screaming Frog таким образом: Upload > Paste
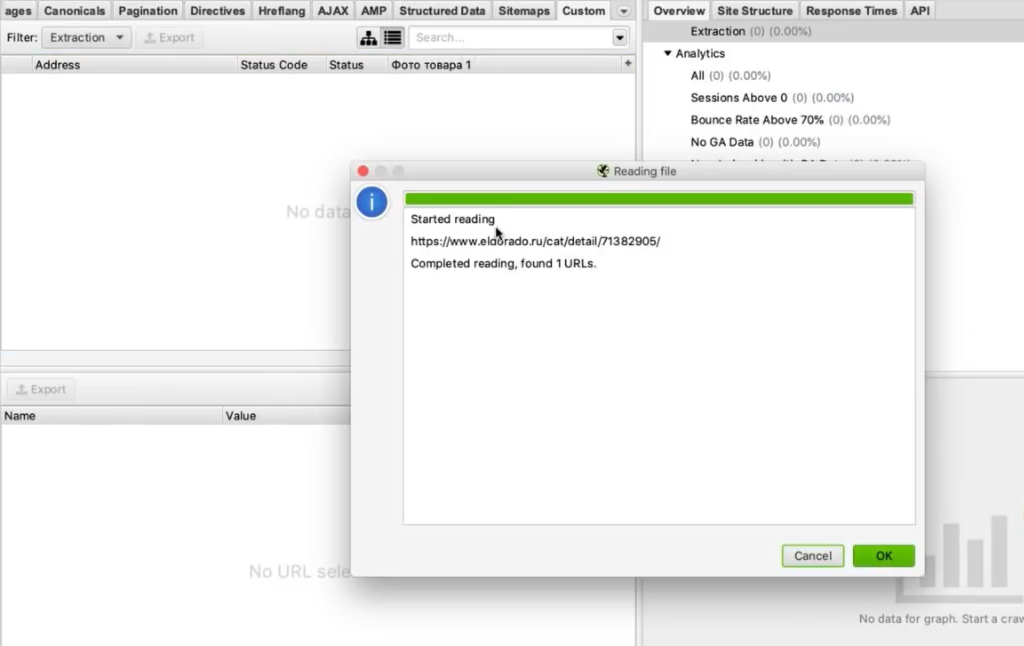
Нажимаем ОК. У нас начинается парсинг.
Screaming Frog спарсил одну карточку товара и у нас получилась такая табличка. Рассмотрим ее подробнее.
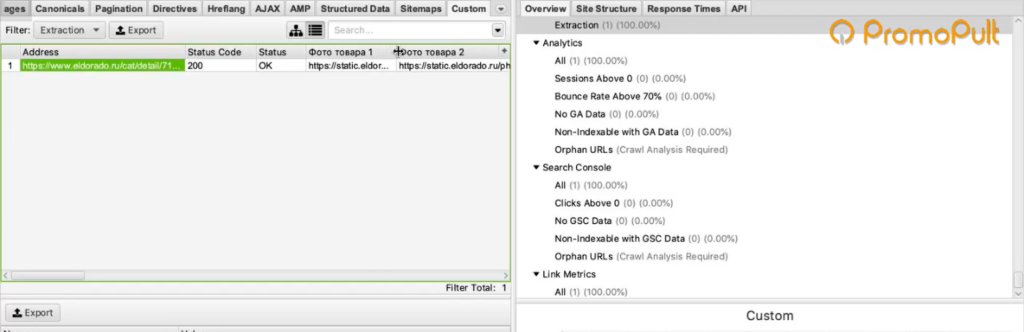
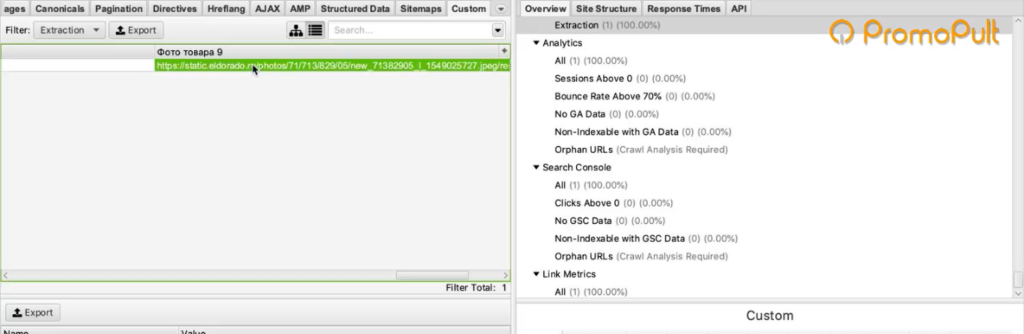
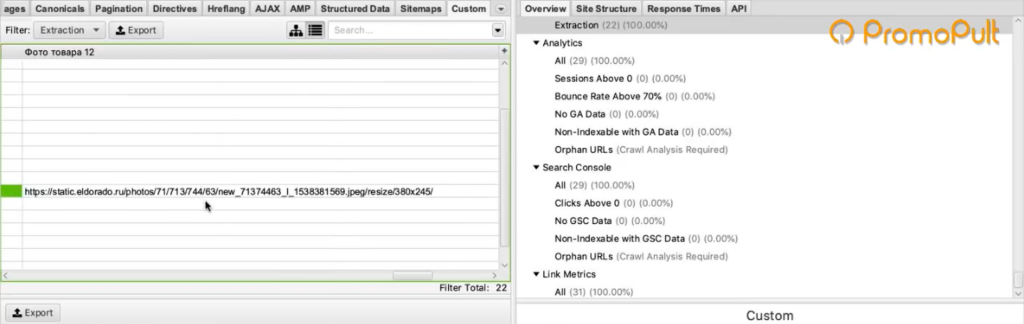
Мы загрузили один URL на входе, и у нас автоматически появилось сразу много столбцов «фото товара». Мы видим, что по этому товару собралось 9 фотографий.
Для проверки попробуем открыть одну из фотографий. Копируем адрес фотографии и вставляем в адресной строке браузера.
Фотография открылась, значит парсер сработал корректно и вытянул нужную нам информацию.
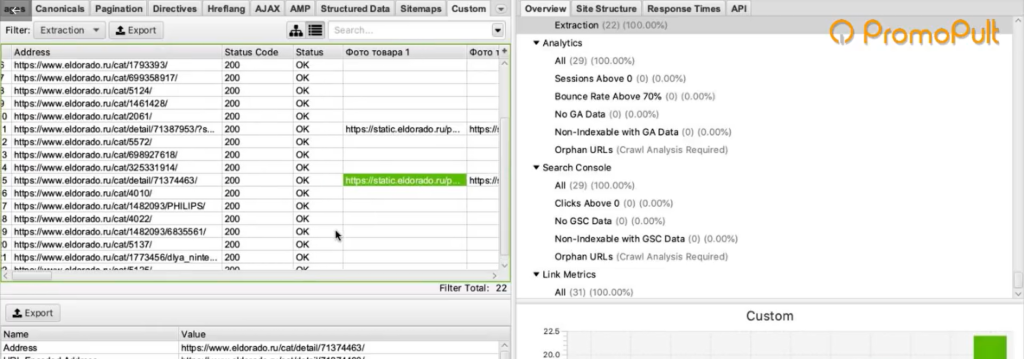
Теперь пройдемся по всему сайту в режиме Spider (для переключения в этот режим нужно нажать Mode > Spider). Укажем адрес https://www.eldorado.ru, нажимаем старт и запускаем парсинг.
Так как программа парсит весь сайт, то по страницам, которые не являются карточками товара, ничего не находится.
А там, где у нас карточки товаров — собираются ссылки на все фотографии.
Таким образом мы сможем собрать их и положить в Excel-таблицу, где будут указаны ссылки на все фотографии для каждого товара.
Если бы мы собирали артикулы, то еще раз зашли бы в Configuration > Custom > Extraction и добавили бы еще два XPath-запроса: для парсинга артикулов, а также тегов h1, чтобы собрать еще названия. Так мы бы убили сразу двух зайцев и собрали бы связку: название товара + артикул + фото.
Пример 3. Как спарсить характеристики товаров
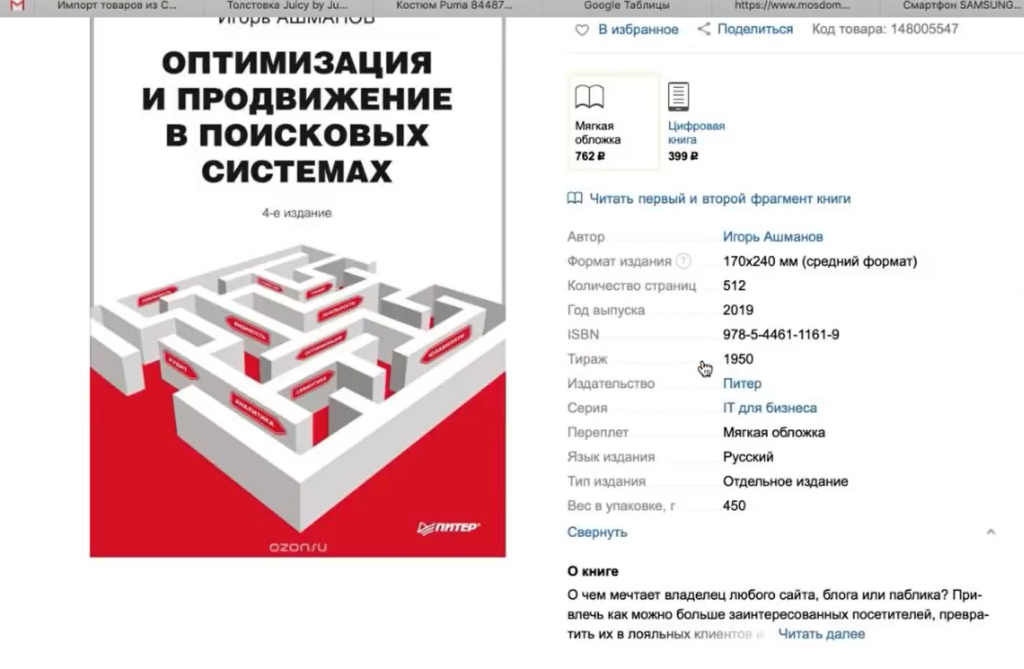
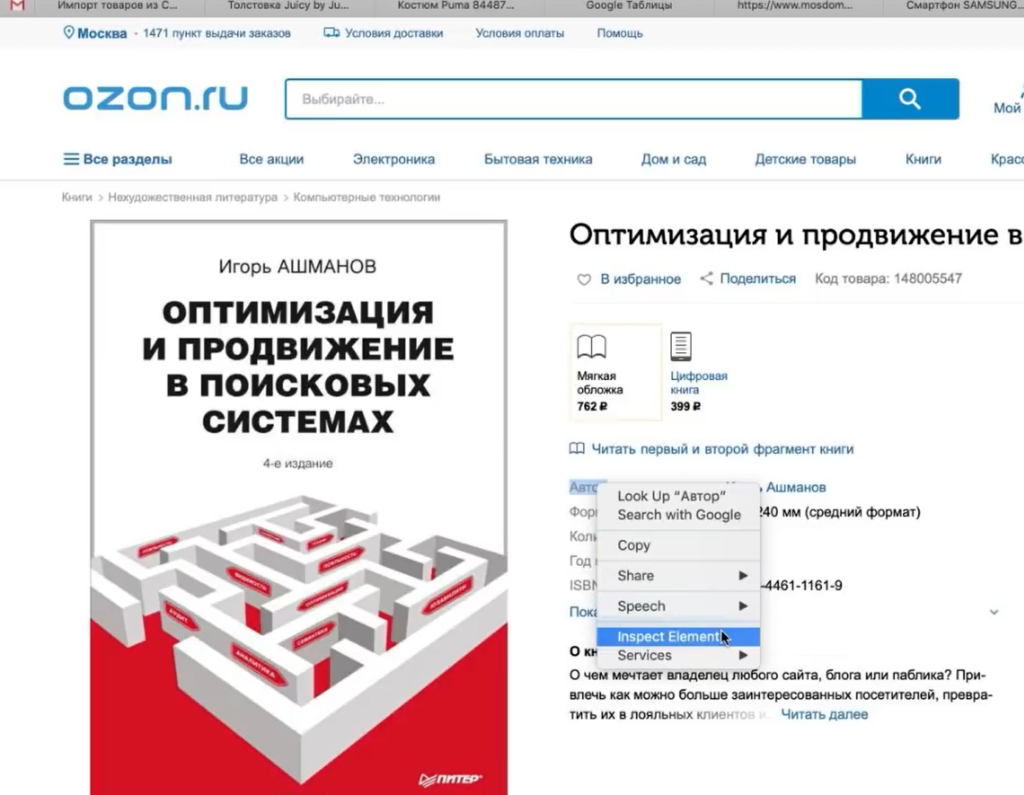
Следующий пример — ситуация, когда нам нужно насытить карточки товаров характеристиками. Представьте, что вы продаете книжки. Для каждой книги у вас указано мало характеристик — всего лишь год выпуска и автор. А у Озона (сильный конкурент, сильный сайт) — у него характеристик много.
Вы хотите собрать в эксель все эти данные с Озона и использовать их для своего сайта. Это техническая информация, вопросов с авторским правом нет.
Изучаем характеристики
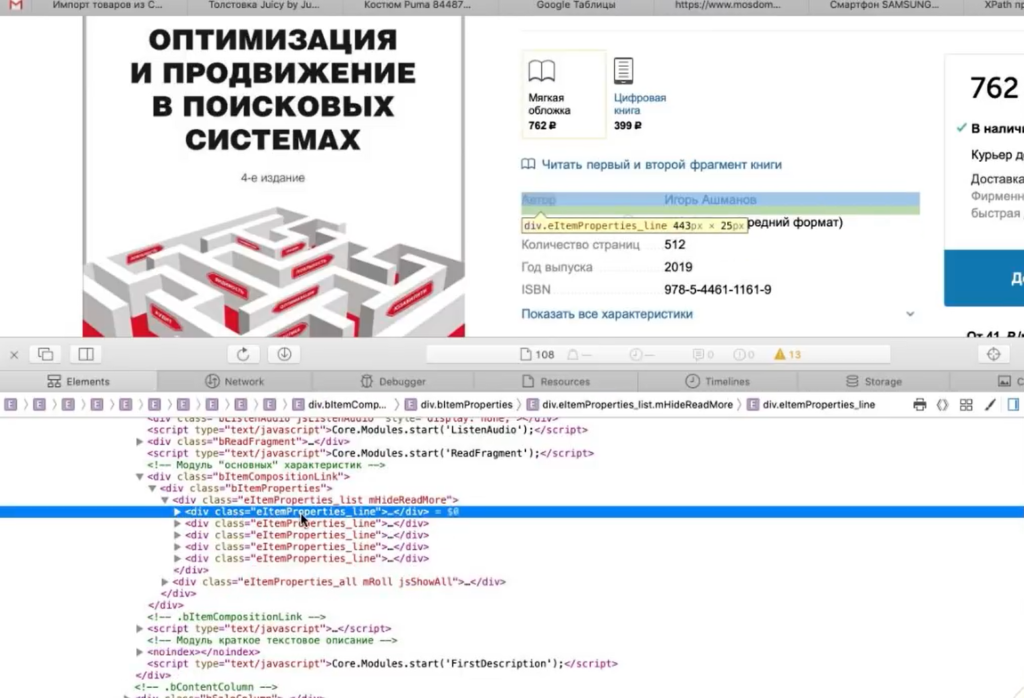
Нажимаете правой кнопкой по данной характеристике, выбираете Inspect Element и смотрите, как называется элемент, который содержит каждую характеристику.
И дальше внутри каждого такого элемента
Значит, нам нужно собирать элементы
Для парсинга нам понадобится вот такой XPath-запрос:
Идем в Screaming Frog. Configuration > Custom > Extraction. Вставляем XPath-запрос, выбираем Extract Text (так как нам нужен только текст в чистом виде, без разметки), нажимаем ОК.
Переключаемся в режим Mode > List. Нажимаем Upload, указываем адрес страницы, с которой будем собирать характеристики, нажимаем ОК.
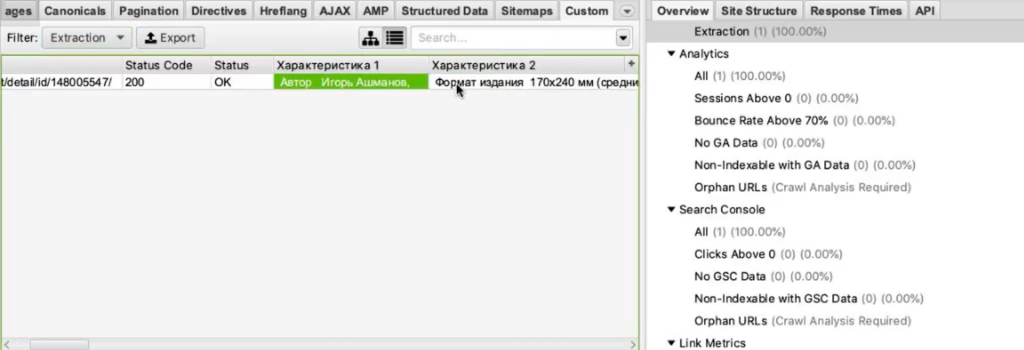
После завершения парсинга переключаемся на вкладку Custom, в списке фильтров выбираем Extraction.
И видим — парсер собрал нам все характеристики. В каждой ячейке находится название характеристики (например, «Автор») и ее значение («Игорь Ашманов»).
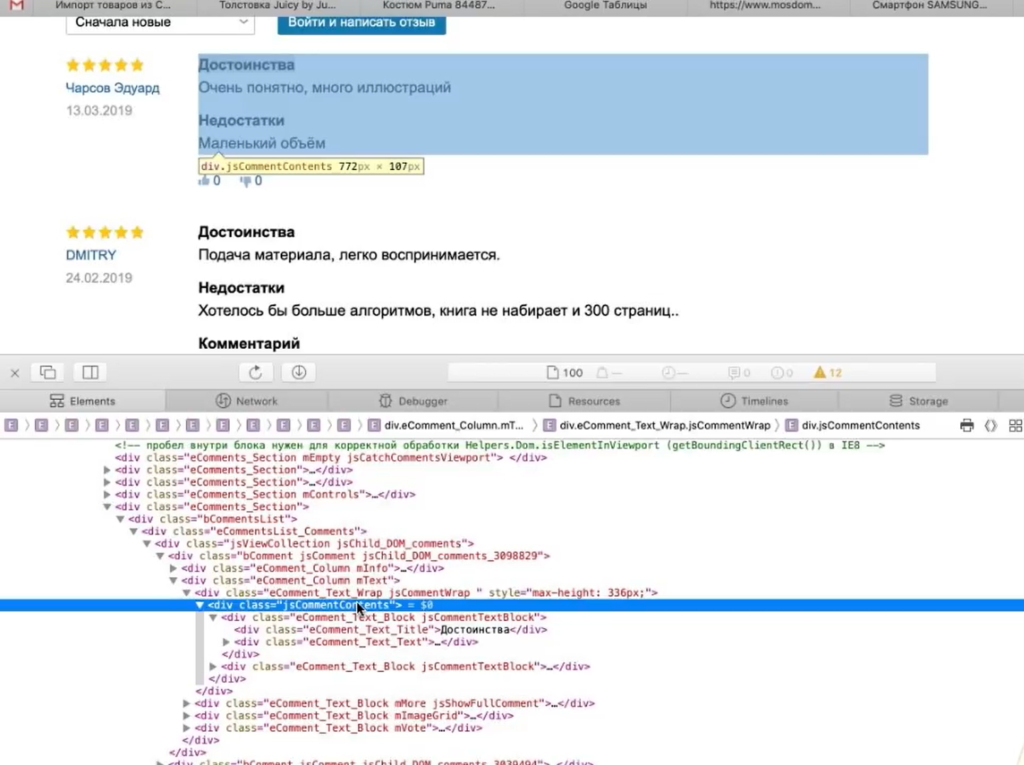
Пример 4. Как парсить отзывы (с рендерингом)
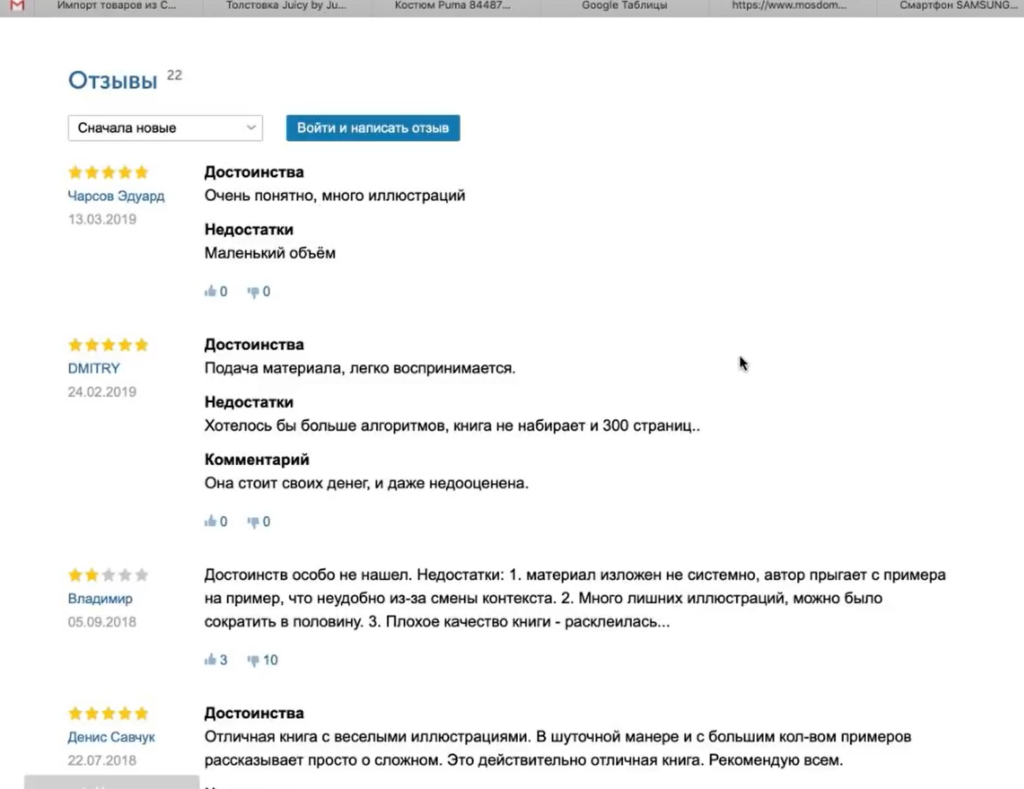
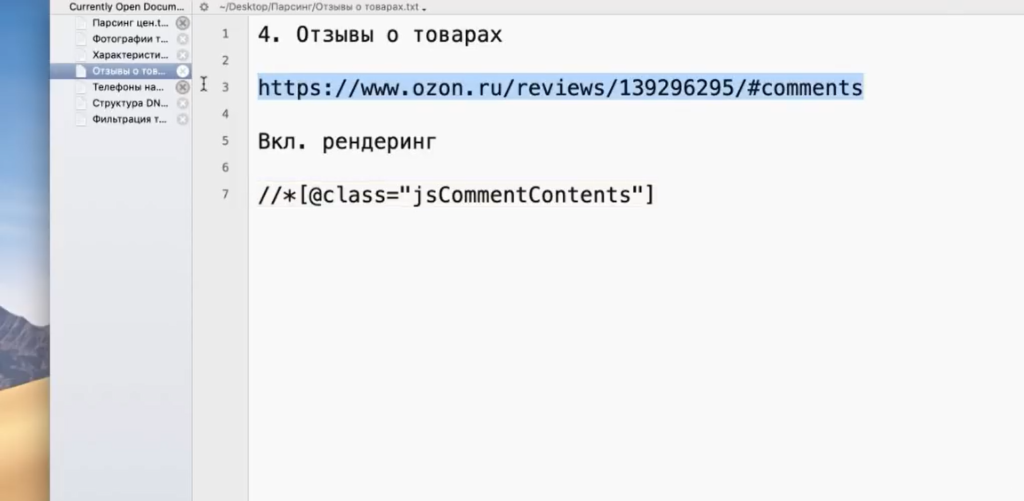
Следующий пример немного нестандартен — на грани «серого» SEO. Это парсинг отзывов с того же Озона. Допустим, мы хотим собрать и перенести на свой сайт тексты отзывов ко всем книгам.
Я покажу на одном примере — загружу один URL. Начнем с того, что посмотрим, где они лежат в коде.
Следовательно, нам нужен такой XPath-запрос:
Добавляем его в Screaming Frog. Теперь копируем адрес страницы, которую будем анализировать, и загружаем в парсер.
Жмем ОК и видим, что никакие отзывы у нас не загрузились:
Почему так? Разработчики Озона сделали так, что текст отзывов грузится в момент, когда вы докручиваете до места, где отзывы появляются (чтобы не перегружать страницу). То есть они изначально в коде нигде не видны.
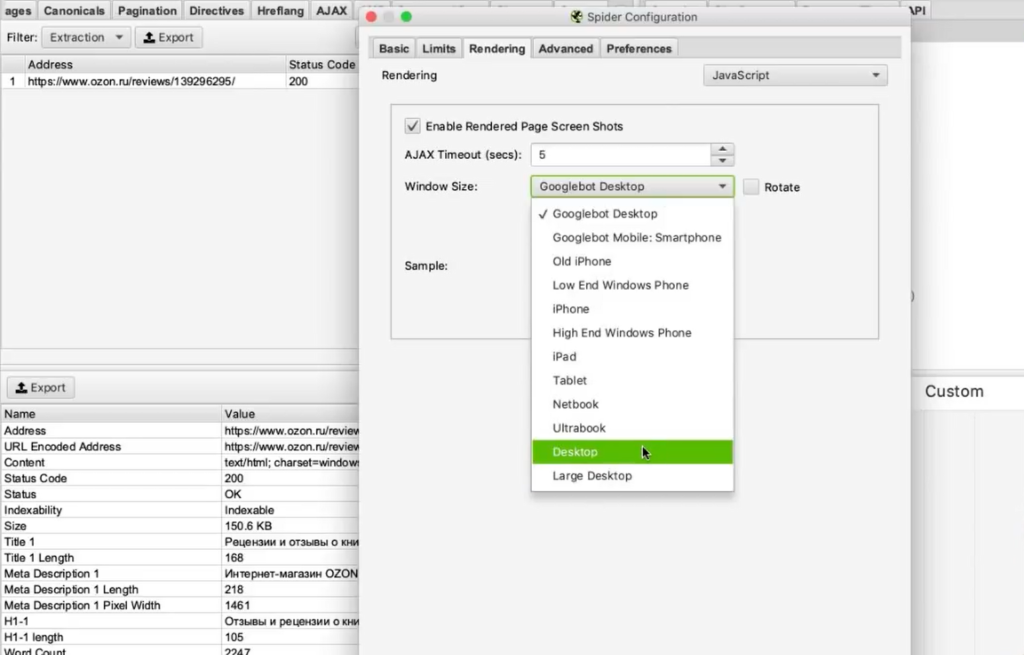
Чтобы с этим справиться, нам нужно зайти в Configuration > Spider, переключиться на вкладку Rendering и выбрать JavaScript. Так при обходе страниц парсером будет срабатывать JavaScript и страница будет отрисовываться полностью — так, как пользователь увидел бы ее в браузере. Screaming Frog также будет делать скриншот отрисованной страницы.
Мы выбираем устройство, с которого мы якобы заходим на сайт (десктоп). Настраиваем время задержки, перед тем как будет делаться скриншот — одну секунду.
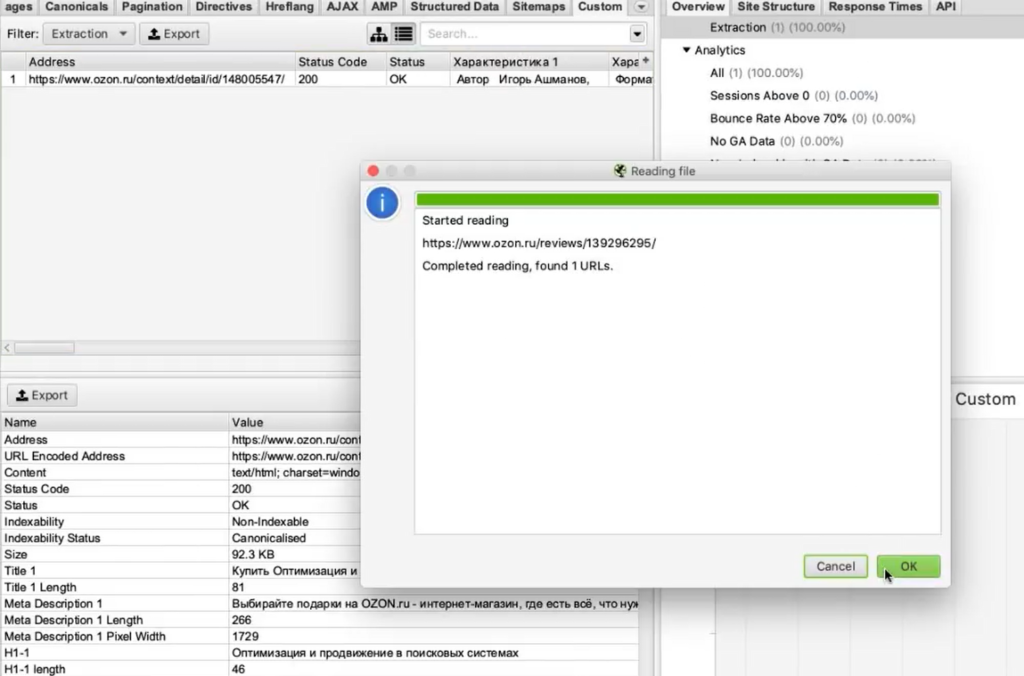
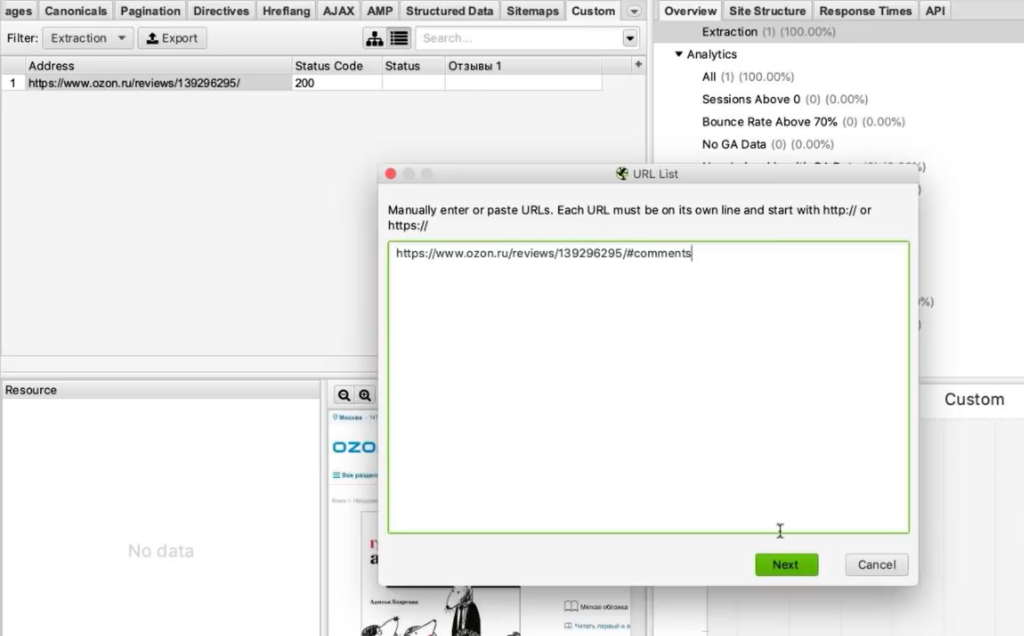
Нажимаем ОК. Введем вручную адрес страницы, включая #comments (якорная ссылка на раздел страницы, где отображаются отзывы).
Для этого жмем Upload > Enter Manually и вводим адрес:
Обратите внимание. При рендеринге (особенно, если страниц много) парсер может работать очень долго.
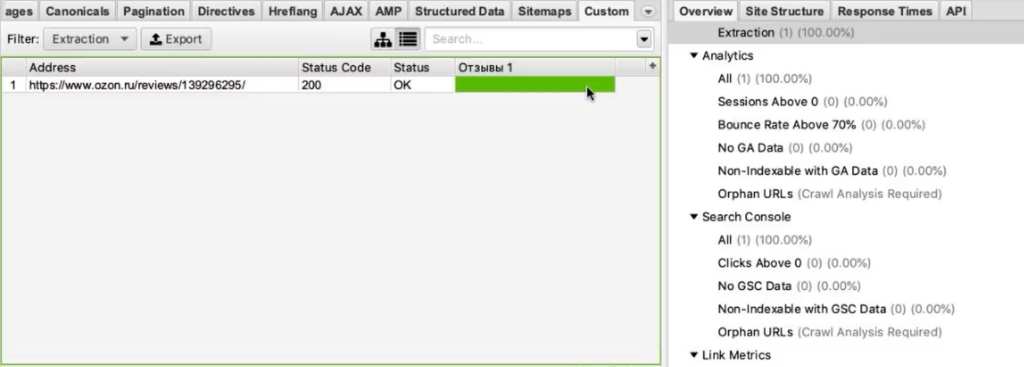
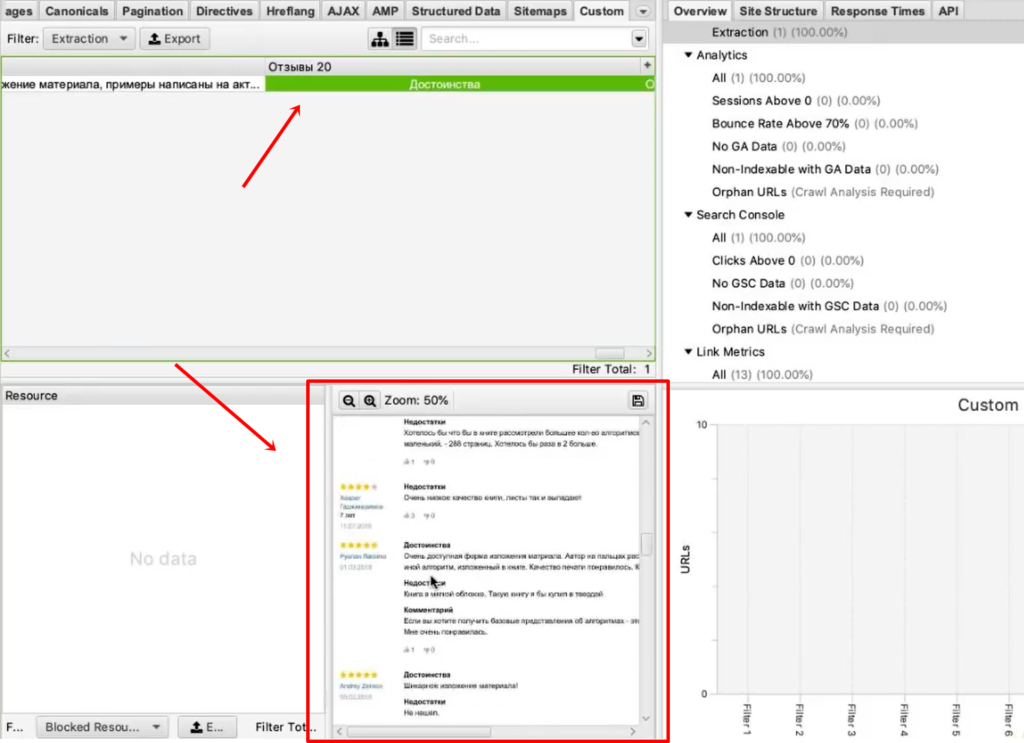
Итак, парсер собрал 20 отзывов. Внизу они показываются в качестве отрисованной страницы. А вверху в табличном варианте мы видим текст этих отзывов.
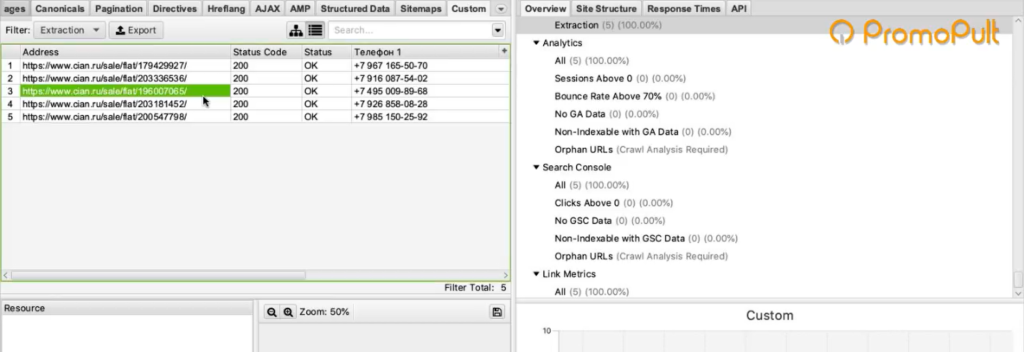
Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
Следующий пример — сбор телефонов с сайта cian.ru. Здесь есть предложения о продаже квартир. Допустим, стоит задача собрать телефоны с каких-то предложений или вообще со всех.
У этой задачи есть особенности. На странице объявления телефон скрыт кнопкой «Показать телефон».
После клика он виден. А до этого в коде видна только сама кнопка.
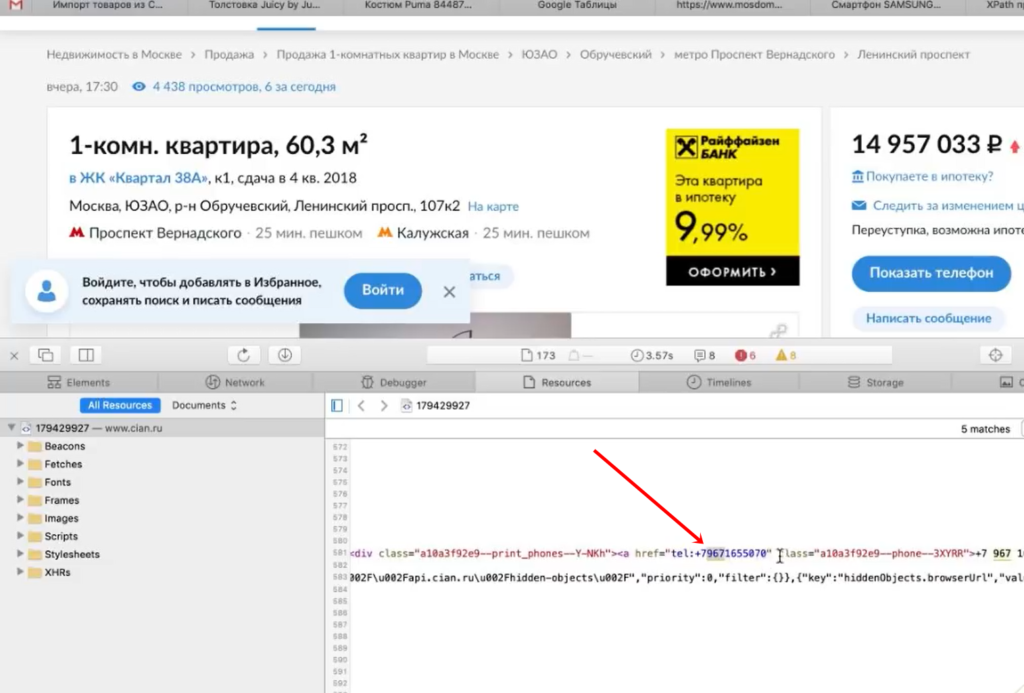
Но на сайте есть недоработка, которой мы воспользуемся. После нажатия на кнопку «Показать телефон» мы видим, что она начинается «+7 967…». Теперь обновим страницу, как будто мы не нажимали кнопку, посмотрим исходный код страницы и поищем в нем «967».
И вот, мы видим, что этот телефон уже есть в коде. Он находится у ссылки, с классом a10a3f92e9—phone—3XYRR. Чтобы собрать все телефоны, нам нужно спарсить содержимое всех элементов с таким классом.
Используем этот класс в XPath-запросе:
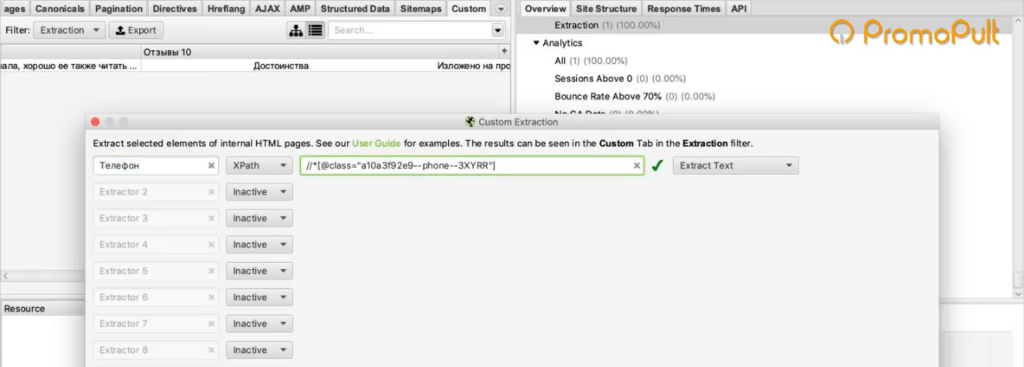
Идем в Screaming Frog, Custom > Extraction. Указываем XPath-запрос и даем название колонке, в которую будут собираться телефоны:
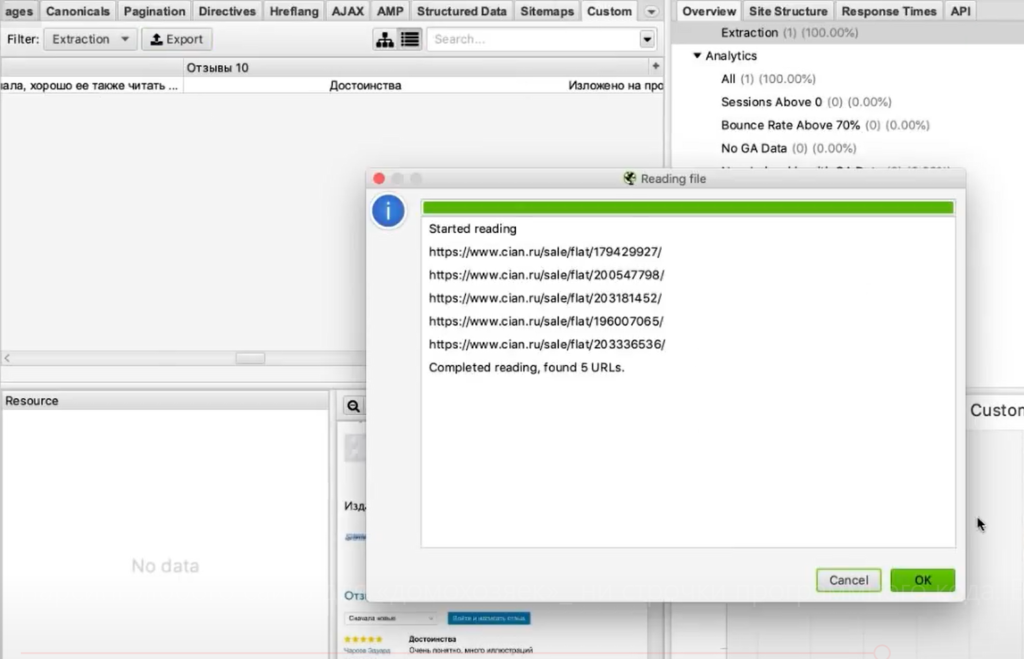
Берем список ссылок (для примера я отобрал несколько ссылок на страницы объявлений) и добавляем их в парсер.
Итак, пожалуйста, мы видим связку: адрес страницы — номер телефона.
Также мы можем собрать в дополнение к телефонам еще что-то. Например, этаж.
Кликаем по этажу, Inspect Element.
Смотрим, где в коде расположена информация об этажах и как обозначается.
Используем класс или идентификатор этого элемента в XPath-запросе.
Добавляем запрос и список страниц, запускаем парсер и собираем информацию.
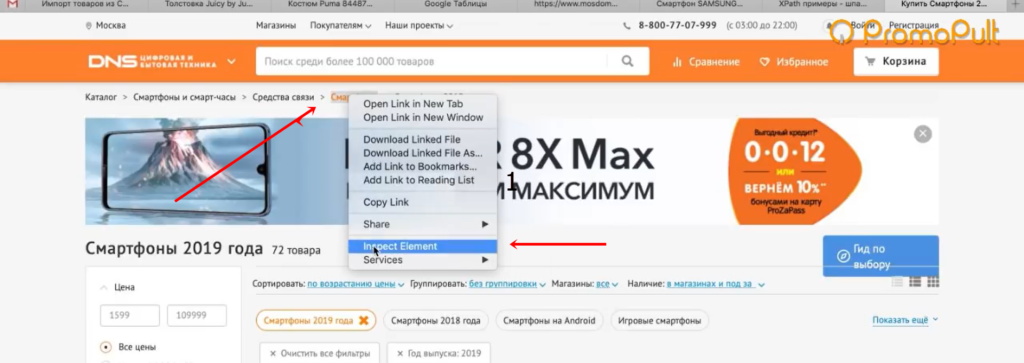
Пример 6. Как парсить структуру сайта на примере DNS-Shop
И последний пример — сбор структуры сайта. С помощью парсинга можно собрать структуру какого-то большого каталога или интернет-магазина.
Рассмотрим, как собрать структуру dns-shop.ru. Для этого нам нужно понять, как строятся хлебные крошки.
Нажимаем на любую ссылку в хлебных крошках, выбираем Inspect Element.
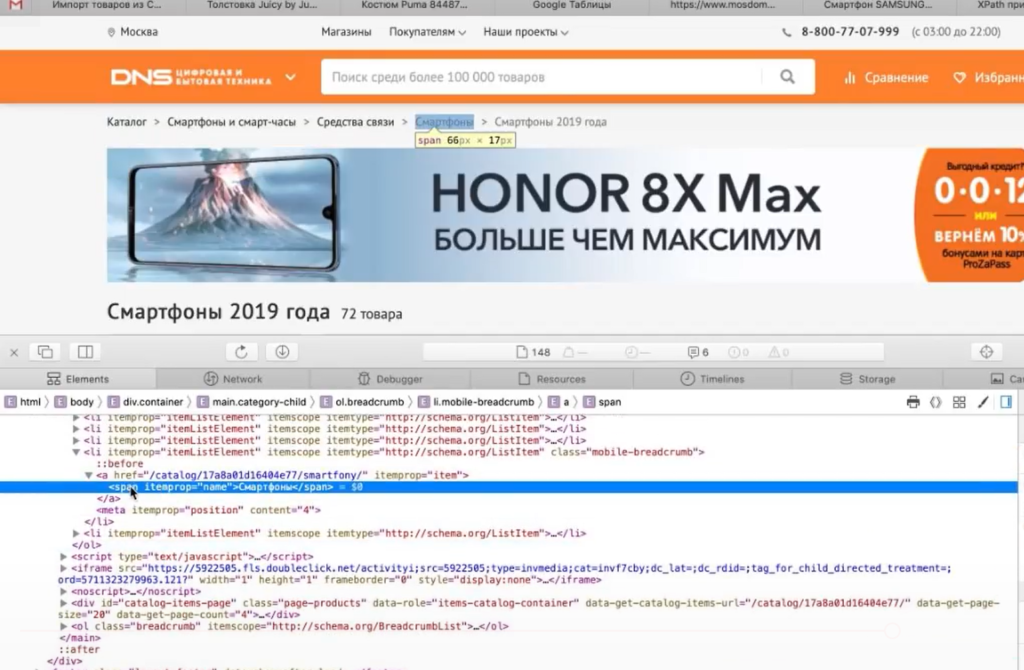
Эта ссылка в коде находится в элементе , у которого атрибут itemprop (атрибут микроразметки) использует значение «name».
Используем элемент span с значением микроразметки в XPath-запросе:
Указываем XPath-запрос в парсере:
Пробуем спарсить одну страницу и получаем результат:
Таким образом мы можем пройтись по всем страницам сайта и собрать полную структуру.
Возможности парсинга на основе XPath
Любую информацию с почти любого сайта. Нужно понимать, что есть сайты с защитой от парсинга. Например, если вы захотите спарсить любой проект Яндекса — у вас ничего не получится. Авито — тоже довольно таки сложно. Но большинство сайтов можно спарсить.
Цены, наличие товаров, любые характеристики, фото, 3D-фото.
Описание, отзывы, структуру сайта.
Контакты, неочевидные свойства и т.д.
Любой элемент на странице, который есть в коде, вы можете вытянуть в Excel.
Ограничения при парсинге
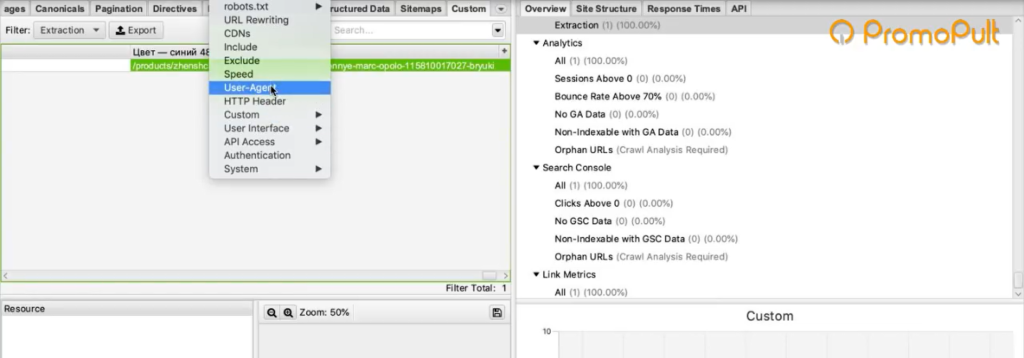
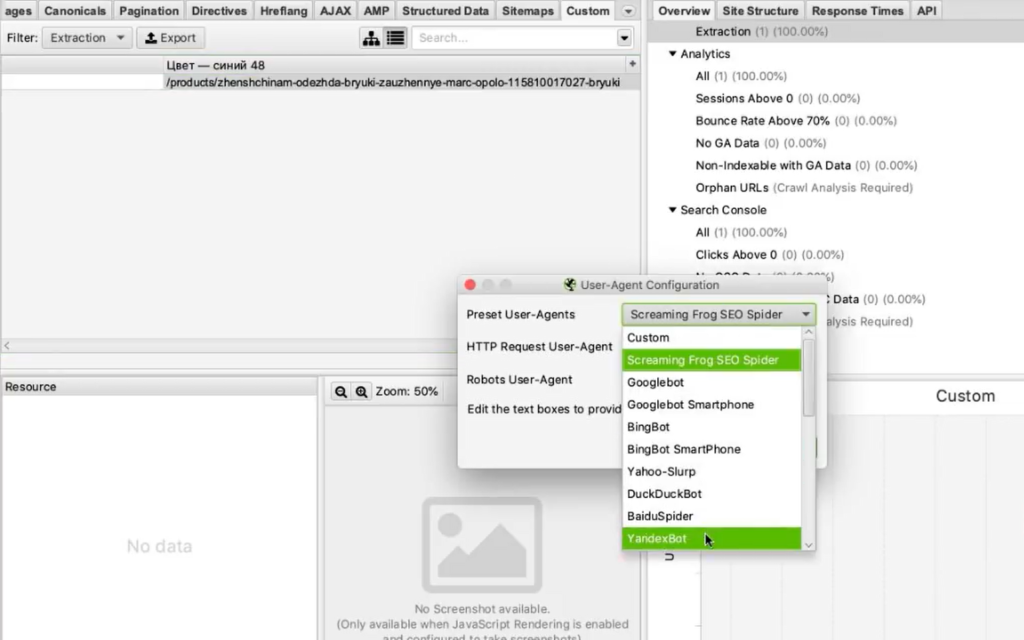
Бан по user-agent. При обращении к сайту парсер отсылает запрос user-agent, в котором сообщает сайту информацию о себе. Некоторые сайты сразу блокируют доступ парсеров, которые в user-agent представляются как приложения. Это ограничение можно легко обойти. В Screaming Frog нужно зайти в Configuration > User-Agent и выбрать YandexBot или Googlebot.
Подмена юзер-агента вполне себе решает данное ограничение. К большинству сайтов мы получим доступ таким образом.
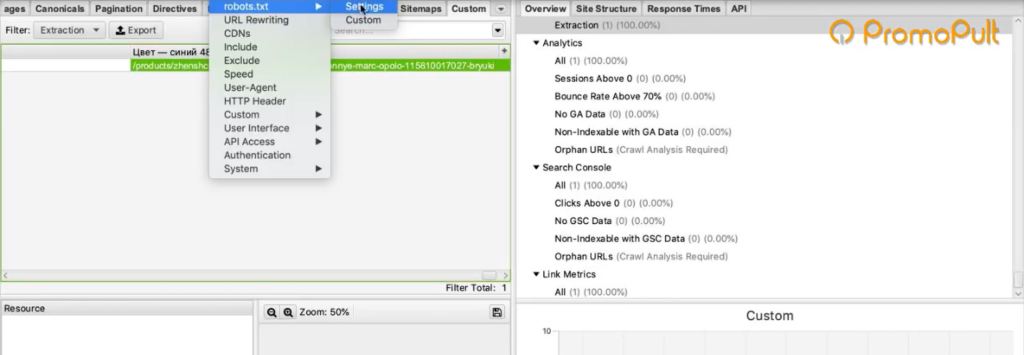
Запрет в robots.txt. Например, в robots.txt может быть прописан запрет индексирования каких-то разделов для Google-бота. Если мы user-agent настроили как Googlebot, то спарсить информацию с этого раздела не сможем.
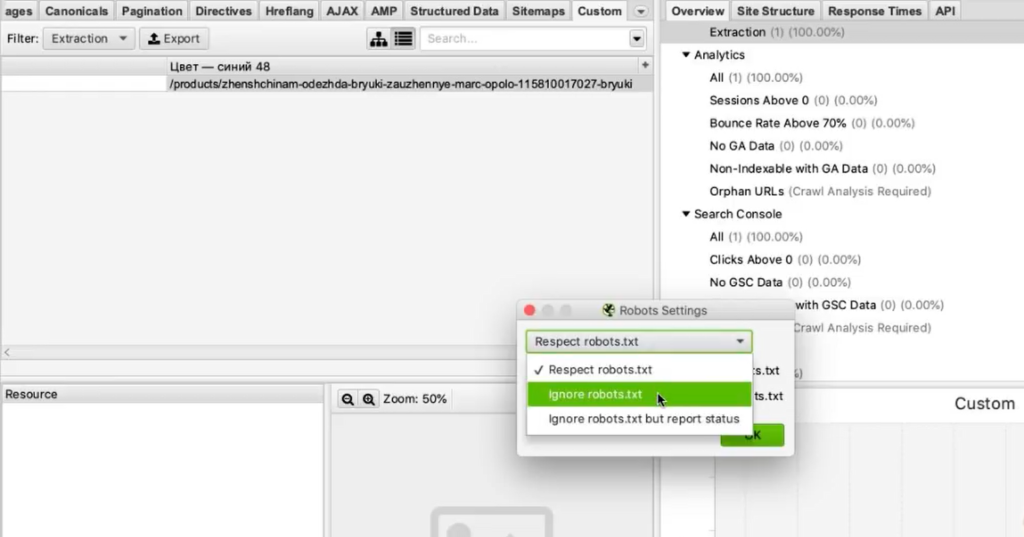
Чтобы обойти ограничение, заходим в Screaming Frog в Configuration > Robots.txt > Settings
И выбираем игнорировать robots.txt
Если вы долгое время парсите какой-то сайт, то вас могут заблокировать на определенное или неопределенное время. Здесь два варианта решения:
Использовать VPN.
В настройках парсера снизить скорость, чтобы не делать лишнюю нагрузку на сайт и уменьшить вероятность бана.
Анализатор активности / капча
Некоторые сайты защищаются от парсинга с помощью умного анализатора активности. Если ваши действия похожи на роботизированные (когда обращаетесь к странице, у вас нет курсора, который двигается, или браузер не похож на стандартный), то анализатор показывает капчу, которую парсер не может обойти.
Такое ограничение можно обойти, но это долго и дорого.
Теперь вы знаете, как собрать любую нужную информацию с сайтов конкурентов. Пользуйтесь приведенными примерами и помните — почти все можно спарсить. А если нельзя — то, возможно, вы просто не знаете как.


 Интерфейс Screaming Frog Seo Spider
Интерфейс Screaming Frog Seo Spider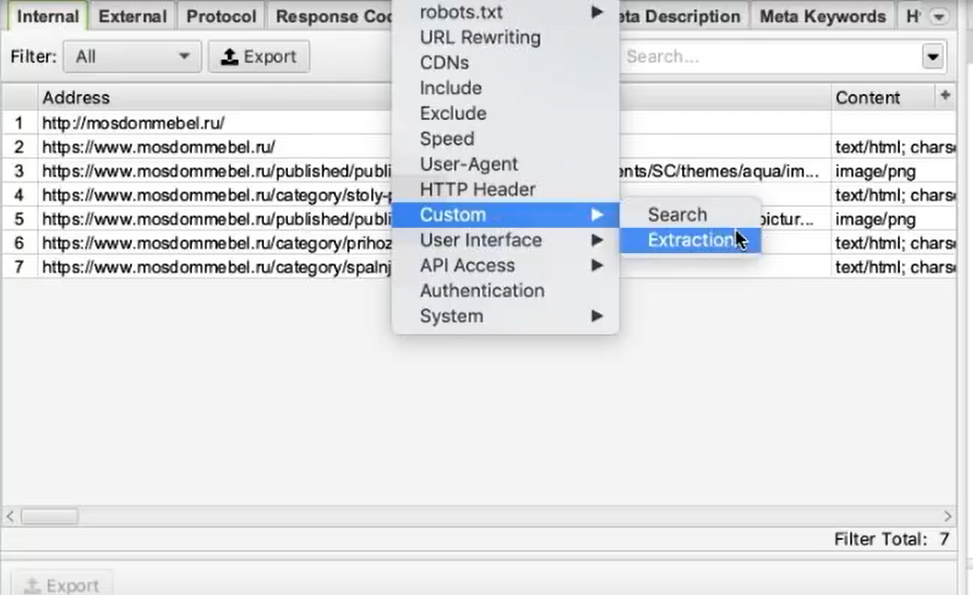
 Ссылка на карту сайта в файле robots.txt
Ссылка на карту сайта в файле robots.txt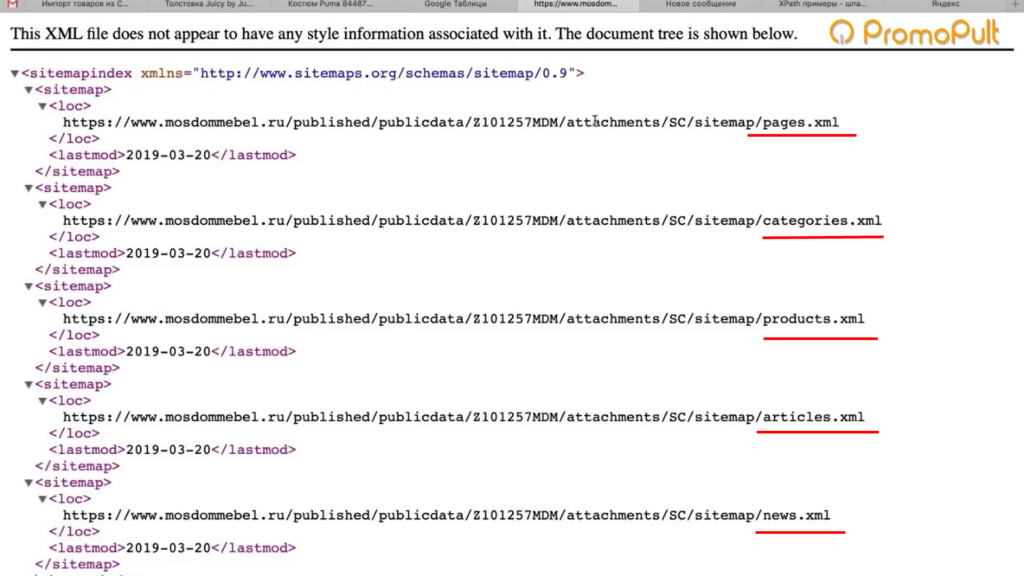 Ссылки на отдельные sitemap-файлы под все типы страниц
Ссылки на отдельные sitemap-файлы под все типы страниц Ссылка на sitemap-файл для карточек товара
Ссылка на sitemap-файл для карточек товара